User-agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:68.0) Gecko/20100101 Thunderbird/68.4.2
Nice to see discussion.
The column approach would work fine because all actions of columns
B/C (run all lex commands) must be done before column D/E actions
can start.
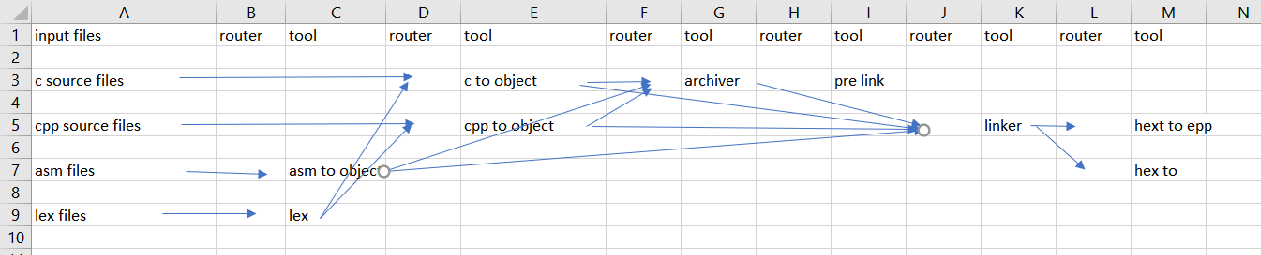
Your remark made me see that the new drawing introduced a nice
example of the performance hit the column approach introduces. All
asm and lex can be done at the same time, but due to the model asm
needs to wait untill lex is done.
To work around this one could change the model to the one below;
but this introduces a new and probably even bigger performance
hit.
In this case when there are no lex files the c and cpp
compilation has to wait until assembly is done.
I think it is wise to drop the strict column sequence solution.
Have the sequence purely based on the arrows showing the
"preceding actions". I think it is still a good idea to have the
convention only having arrows go from left to right but there is
no need for the model to enforce it. One can even consider
dropping the columns completely.
To be able to introduce pre/post build and other actions; we can
add "pre and post action" meta data to the columns (if the columns
are dropped we need another way of grouping and add the meta data
to the group).
It seems to me that letting go of the sequence based on the
columns makes introduction of "non file triggered actions"
complicated. Maybe we should simply add the meta data "all things
on the left should be finished before starting to process this
column" (default off) to the column.
I need to think. Hoping for input of the modelling experts.
Jantje
PS I won't be active in the coming days due to other activities.
Op 30/01/2020 om 23:39 schreef Jonah
Graham:
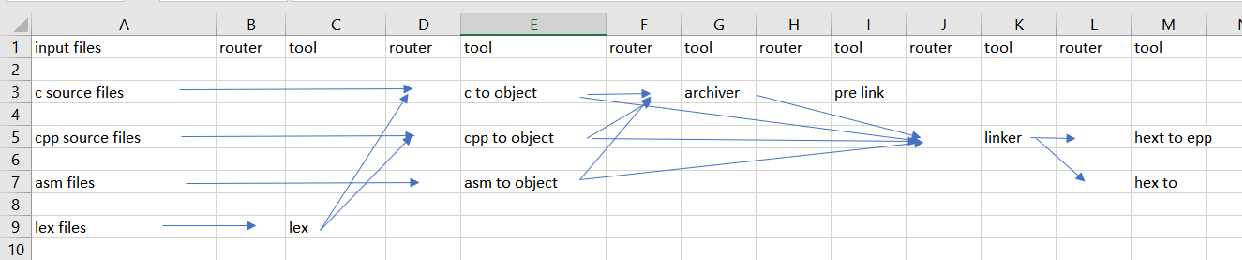
Thanks Jante - I am glad to see you are considering
the lex case in your thought processes. To complicate the
picture slightly, the lex output includes header files so it is
important, order wise, that the lex happens before the
compilation of other sources. So in the updated drawing you
still can't run everything in a column in parallel as there are
dependencies in that drawing from objects in column C back to
column A.
On Thu, 30 Jan 2020 at 16:35,
Jan Baeyens <jan@xxxxxxxxxx> wrote:
Jonah
Given the responses I think my drawing has been
misunderstood. Or maybe I'm all wrong :-). What I drew
was an arduino like toolchain in a "non existing modelling
tool". A kind of mock-up of what I feel the modelling tool
should be capable to do.
When I say that the proposed model is non recursive I mean
you can not draw an arrow that goes from right to left
which would mean going back in time. As far as I
understand lex there is no need to do so.
Assuming that Arduino decides to extend the toolchain to
support lex files; I would have to modify the model to
look something like below.
Note: even though Wikipedia states lex generates C files
I made the model having lex generate both C and CPP files
to emphasis the need/power of a filter function in the
router.
@Alexander
I'm really wondering what I would need to do to get
Sloeber working after I changed the model adding the lex
compiler as above.
Modelling a simple library project would look like
Best regards
Jantje
Op 30/01/2020 om 18:01 schreef Jonah Graham:
Hi Jante,
It looks like you have been having some good
thoughts on this - hopefully that will continue to
spark some good conversation.
> IMHO recursivity at the file level does not
exists
I am not sure this is what you are referring to
here, but I would expect any new work to be able to
handle cases such as lex/y -> c/h -> .o. In the
current diagram that would imply arrows from column A
-> C -> A -> C -> E.
On Wed, 29 Jan 2020 at
17:54, Jan Baeyens <jan@xxxxxxxxxx>
wrote:
Op 27/01/2020 om 14:47 schreef Alexander
Fedorov:
Hello,
We (with my good friends @ArSysOp) are working on
Toolchain metamodel prototype that should cover
the needs of CDT and will be flexible enough to be
applied for sibling areas.
Of course there is a number of EMF usage tricks
collected through all that years that we are going
to use during this work. We know the model-to-text
generation technologies from JET to Acceleo, so we
will be able to create whatever we need, not only
the default Java classes.
Great
Currently we are polishing things that were
presented for Postgres community 1 year ago during
the "IDE for stored procedures" talk and
discussion. Yes, it may sound curious, but the
"toolchain model" idea with all the "target
hardware description" and "project structure
model" appears to be very similar for a lot of
ecosystems.
This is what I would expect. Basically in toolchain
land there are "files" and "tools". There is only a
very limited set of combinations you can have with
"files" and "tools".
IMHO recursivity at the file level does not exists
and tool sequence is pretty obvious at the model
level. However: correct me if I'm wrong.
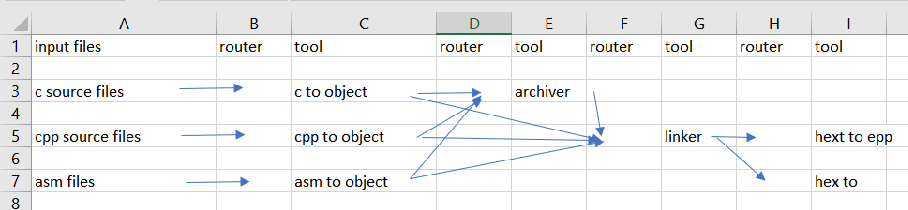
I have been thinking hard about how to model a
gcc toolchain and below is a representation of how
I see things now
I haven't yet found a good name for what I called
router. It is absolutely crucial to understand
router to understand the model. All other stuff is
pretty obvious
In it's simplest form router will create a list of
"input file; output file" (like "input.cpp"
"input.cpp.o"). for each item in the list tool can
add a command which results in "input file; output
file; command" which -in make world- is called a
"rule".
A more complicated router may have multiple input
files and multiple output files which means that
the router produces a list of "list of input
files; list of output files".
Also the tool can produce more than one command so
the output of a router tool combinations should be
a list of "list of input files; list of output
files; ordered list of commands".
The router can also filter input files. For
instance in the example above the output of the "c
to object" tool is send to both the archiver and
the linker. It is up to the "collection of
routers" to make sure the files are processed at
the right place. Given a specific file: the model
supports all options (archiver; linker; archiver
and linker;none) and assumes the need for coding
to support this construction.
The builder can simply go from left to right
processing the router/tool columns one by one.
Asking the routers the "list of input files; list
of output files" checking whether a command needs
to be run and if so ask the command to generate
the "ordered list of commands" to run. Run these
and move on to the next.
Note 1 that the router explicitly names the
output file(s).
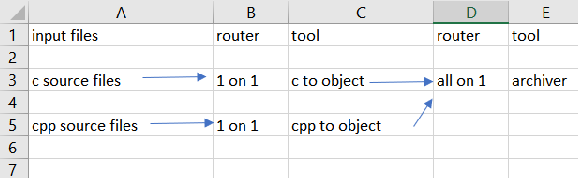
Note 2 when implementing this model it seems
logical to have 2 generic routers ("1 on 1" -fi
compile- and "all on 1" -fi archive-) "1 on 1"
would need a "name provider" (append .o) and "all
on 1" will need a output file (archive.ar). The
model above needs "custom build" routers next to
the generic ones
Note 3 Looking an the linker input files (which
can be object files and archive files) one can
argue that the "list of input files' needs to be a
"list of lists of input files". One can also argue
it is up to the tool to "triage the files". I
haven't decided yet what I think is the best.
Note 4: this model assumes there is no order of
commands in the column. It behaves as if all the
commands from one column can be executed at the
same time.
Note 5: the model assumes that all actions in a
column must have finished before the next column
can be "evaluated/executed". This allows for "non
file based commands" like "pre build actions";
"post build actions" to have their own column like
demonstrated below
Note 6:I understand that note 4 and 5 are a
serious constraint for a more generic modelling
tool.
The plan is to share it on GitHub as a set of
Ecore metamodels and then go through several
iteration of minor "releases" until we will find
good solution. Then we can have it either as a
separate Eclipse project or as a part of CDT -
this may be decided later.
Do you think this will be multi year or multi month
project before we get it into CDT?
Regards,
AF
23.01.2020 23:35, Jonah Graham пишет:
I have no experience with emf
modelling so I don't know it is capable
enough. I also have no experience
getting this in java classes. Help will
be needed if we go this way. Learning
EMF is now on my todo :-)
Is there some doc from the discussion
from Alexander Federov and William
Riley?
P.S. Well, as we started the introduction session
... actually, my family name is Fedorov, from the
Greek "Θεόδωρος " you
may know it as the Latin "Theodor", that means
"God-given" :)