Architecture
If an entire team is querying the same set of models, indexing them from a central location is more efficient than maintaining multiple indexes. In other cases, we may want to query models from outside Eclipse and even from applications written in other languages (e.g. C++ or Python).
To support these use cases, Hawk includes a server that exposes its functionality through a set of Thrift APIs. This server product is a headless Eclipse application that can be run from the command line. The general structure is as shown here:
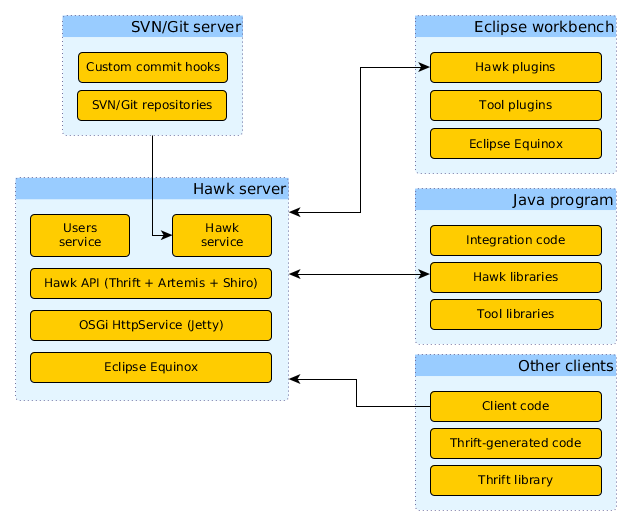
The server component is implemented as an Eclipse application, based on the Eclipse Equinox OSGi runtime. Using Eclipse Equinox for the server allows for integrating the Eclipse-based tools with very few changes in their code, while reducing the chances of mutual interference. The OSGi class loading mechanisms ensure that each plugin only "sees" the classes that it declares as dependencies, avoiding common clashes such as requiring different versions of the same Java library or overriding a configuration file with an unexpected copy from another library.
To mitigate the risk of connectivity problems due to enterprise firewalls, the server uses for most of the API the standard HTTP and HTTPS protocols (by default, on the unprivileged ports 8080 and 8443) and secures them through Apache Shiro. Optionally, the Hawk API can be exposed through raw TCP on port 2080, for increased performance: however, security-conscious environments should leave it disabled as it does not support authentication. The embedded Apache Artemis messaging queue required for remote change notifications in Hawk requires its own port, as it manages its own network connections. By default, this is port 61616. These notifications are made available through two protocols: Artemis Core (a lightweight replacement for the Java Message Service, for Java clients) and STOMP over WebSockets (a cross-language messaging protocol, for web-based clients).
The server includes plugins that use the standard OSGi HttpService facilities to register servlets and filters. Each service is implemented as one or more of these servlets. The currently implemented endpoints are these:
| Path within server | Service | Thrift protocol |
|---|---|---|
| /thrift/hawk/binary | Hawk | Binary |
| /thrift/hawk/compact | Hawk | Compact |
| /thrift/hawk/json | Hawk | JSON |
| /thrift/hawk/tuple | Hawk | Tuple |
| /thrift/users | Users | JSON |
All services provide a JSON endpoint, since it is compatible across all languages supported by Thrift and works well with web-based clients. However, since Hawk is performance sensitive (as we might need to encode a large number of model elements in the results of a query), it also provides endpoints with the other Thrift protocols. Binary is the most portable after JSON, and Tuple is the most efficient but is only usable from Java clients. Having all four protocols allows Hawk clients to pick the most efficient protocol that is available for their language.
The available operations for the Users and Hawk APIs are listed in Thrift API. For details about the optional access control to these APIs, check Thrift API security.