Core concepts and general usage¶
Components¶
Hawk is an extensible system. Currently, it contains the following kinds of components:
| Type | Role | Current implementations |
|---|---|---|
| Change listeners | React to changes in the graph produced by the updaters | Tracing, Validation |
| Graph backends | Integrate database technologies | Neo4j, OrientDB, Greycat, SQLite |
| Model drivers | Integrate modelling technologies | EMF, Modelio, IFC2x3/IFC4 in this repo, and UML2 |
| Query languages | Translate high-level queries into efficient graph queries | Epsilon Object Language, Epsilon Pattern Language, OrientDB SQL |
| Updaters | Update the graph based on the detected changes in the models and metamodels | Built-in |
| VCS managers | Integrate file-based model repositories | Local folders, SVN repositories, Git repositories, Eclipse workspaces, HTTP files |
General usage¶
Using Hawk generally involves these steps:
- Create a new Hawk index, based on a specific backend (e.g. Neo4j or OrientDB).
- Add the required metamodels to the index.
- Add the model repositories to be monitored.
- Wait for the initial batch insert (may take some time in large repositories).
- Add the desired indexed and derived attributes.
- Perform fast and efficient queries on the graph, using one of the supported query languages (see table above).
In the following sections, we will show how to perform these steps.
Managing indexes with the Hawk view¶
To manage and use Hawk indexes, first open the "Hawk" Eclipse view, using "Window > Show View > Other... > Hawk > Hawk". It should look like this:

Hawk indexes are queried and managed from this view. From left to right, the buttons are:
- Query: opens the query dialog.
- Run: starts a Hawk index if it was stopped.
- Stop: stops a Hawk index if it was running.
- Sync: request the Hawk index to check the indexed repositories immediately.
- Delete: removes an index from the Hawk view, without deleting the actual database (it can be recovered later using the "Import" button). To remove a local index completely, select it and press
Shift+Delete. - New: creates a new index (more info below).
- Import: imports a Hawk index from a factory. Hawk itself only provides a "local" factory that looks at the subdirectories of the current Eclipse workspace.
- Configure: opens the index configuration dialog, which allows for managing the registered metamodels, the repositories to be indexed, the attributes to be derived and the attributes to be indexed.
Creating a new index¶
To create a new index, open the Hawk view and use the "New" button to open this dialog:
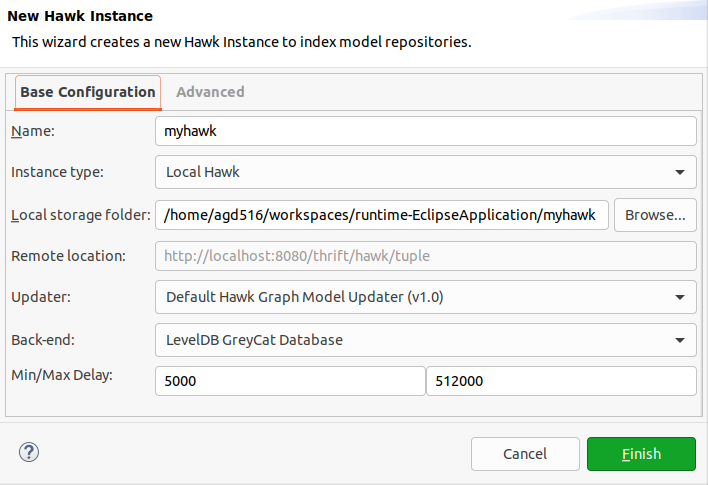
The "Base Configuration" tab of this dialog contains these fields:
- Name: a descriptive name for the index. Only used as an identifier.
- Instance type: you can use a local instance, or an instance hosted in an external server. By default, Hawk only indexes the latest version of the model, but you can also make it operate in a time-aware manner mode) where it will record all versions of the model into a temporal graph.
- Local storage folder: folder that will store the actual database (in local instances), or a reference to the remote server (in remote instances). If the folder exists, Hawk will reuse that database instead of creating a new one.
- Remote location: only used for the remote instances.
- Back-end: database backend to be used (note that only some backends support time-aware operation: please see here for details).
- Min/max delay: minimum and maximum delays in milliseconds between synchronisations. Hawk will start at the minimum value: every time it does not find any changes, it will double the delay up to the maximum value. If it finds a change, it will reset back to the minimum value. Periodic synchronisation can be completely disabled by changing the minimum and maximum delays to 0: in this mode, Hawk will only synchronise on startup, when a repository is added or when the user requests it manually.
The "Advanced" tab of this dialog allows you to select which Hawk plugins to enable for this instance:
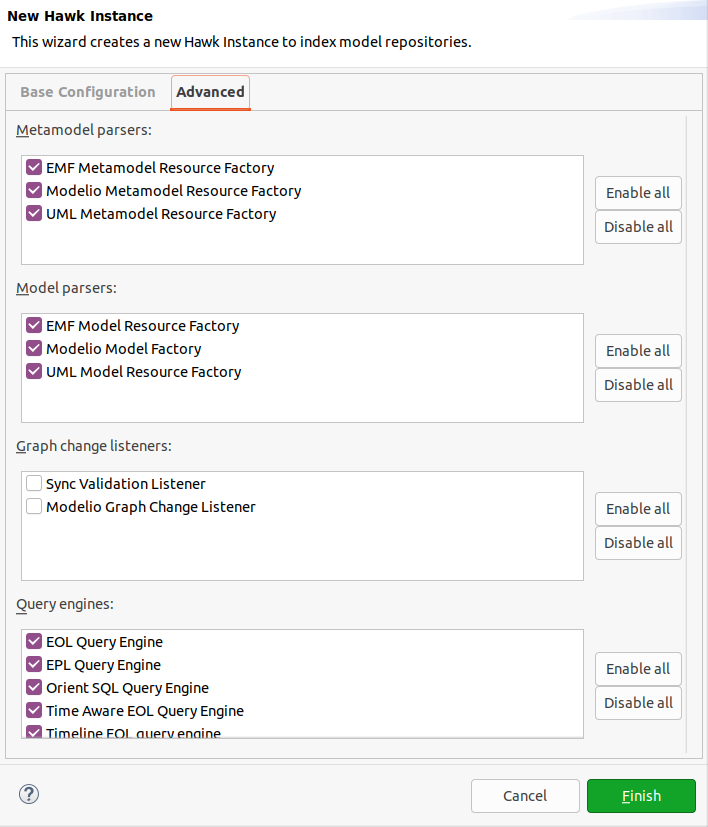
By default, local instances will have all metamodel parsers, all model parsers, and all query engines enabled out of the box. Remote instances will have no plugins enabled by default.
Since Hawk 2.2.0, the dialog requires selecting at least one metamodel parser, one model parser, and one query engine.
Once all settings are to your liking, click on "Finish" and Hawk will create and set up the index.
Managing metamodels¶
After creating the index, the next step is to register the metamodels of the models that are going to be indexed. To do this, select the index in the Hawk view and either double click it or click on the "Configure" button. The configure dialog will open:
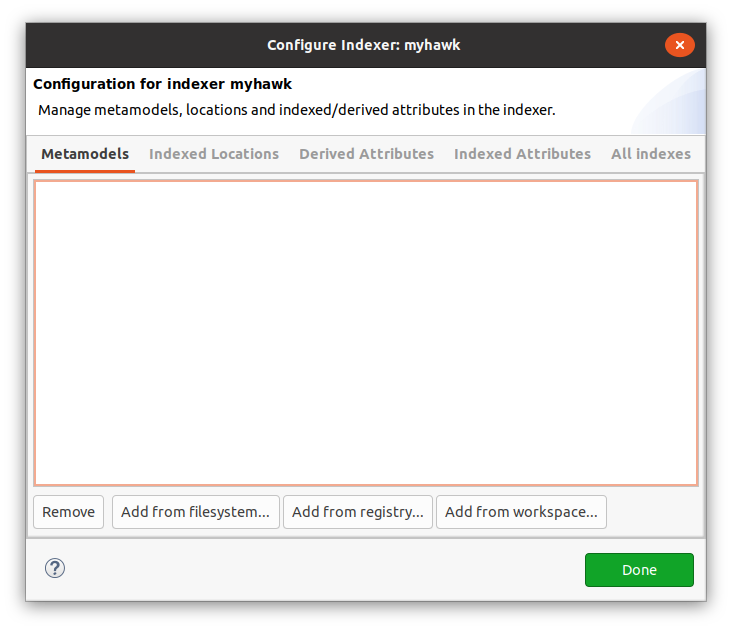
The configure dialog has several tabs. For managing metamodels, we need to go to the "Metamodels" tab. It will list the URIs of the currently registered metamodels. Hawk will automatically try to register the necessary metamodels when it first encounters them in a model, so long as they are in the global EMF package registry. If the metamodel is not in the global EMF package registry, or if you would like to set up all metamodels in advance, you can use one of the "Add" buttons:
Add from filesystem...will ask for the path to a file containing the metamodel in your computer (e.g. the.ecorefile for EMF-based models, or themetamodel-descriptor.xmlfor Modelio-based models).Add from registry...allows you to search for a EPackage in the global EMF registry by namespace URI.Add from workspace...will ask for the location of a file containing the metamodel in your Eclipse workspace.
We can also "Remove" metamodels: this will remove all dependent models and metamodels as well.
To try out Hawk, we recommend adding the JDTAST.ecore and XMLType.ecore metamodels in this folder, which were used in the GraBaTs 2009 case study from AtlanMod. For Modelio metamodels, use the metamodel-descriptor.xml in the Hawk test suite for Modelio 3.6 projects (for other versions, use the older descriptors included as metamodel_*.xml files in the Modelio sources).
Keep in mind that metamodels may have dependencies to others. You will need to either add all metamodels at once, or add each metamodel after those it depends upon.
Managing repositories¶
Having added the metamodels of the models to be indexed, the following step is to add the repositories to be indexed. To do so, go to the "Indexed Locations" tab of the Hawk configure dialog, and use the "Add" button. Hawk will present the following dialog:

The fields will depend on the type of repository being added. For example, for "Git Repository", you will be asked for the path to the local clone, and the branch to be indexed. Other repositories may allow for entering a username/password pair (which will be stored on the Eclipse secure storage), or may ask for paths to individual files.
You can also tick the "Freeze repo" tick to temporarily prevent Hawk from checking the contents of a repository. This setting can be later changed by selecting the repository entry and clicking on "Edit...".
To try out Hawk, after adding the JDTAST.ecore and XMLType.ecore metamodels from the previous section, we recommend adding a "Local File Monitor" pointing to this set0.xmi file. It has around 70k model elements. To watch over the indexing process, check the "Info" column in the Eclipse Hawk view.
The supported file extensions are as follows:
| Driver | Extensions |
|---|---|
| EMF | .xmi, .model, any extensions in the EMF extension factory map, any extensions mentioned through the org.eclipse.hawk.emf.model.extraExtensions Java system property (e.g. -Dorg.eclipse.hawk.emf.model.extraExtensions=.railway,.rail). |
| UML2 | .uml. .profile.uml files can be indexed normally and also registered as metamodels. |
| BPMN | .bpmn, .bpmn2. |
| Modelio | .exml, .ramc. Parses mmversion.dat internally for metadata. |
| IFC | .ifc, .ifcxml, .ifc.txt, .ifcxml.txt, .ifc.zip, .ifczip. |
Managing indexed attributes¶
Simply indexing the models into the graph will already speed up considerably some common queries, such as finding all the instances of a type: in Hawk, this is done through direct edge traversal instead of going through the entire model. However, queries that filter model elements through the value of their attributes will need additional indexing to be set up.
For instance, if we wanted to speed up return IJavaProject.all.selectOne(p|p.elementName='MyProject'); (which returns the Java project named "MyProject"), we would need to index the elementName attribute in the IJavaProject type. To do so, we need to go to the Hawk configure dialog, select the "Indexed Attributes" tab and press the "Add" button. This dialog will open:

Its fields are as follows:
- Metamodel URI: the URI of the metamodel that has the type we want.
- Target Type: the name of the type (here "IJavaProject").
- Attribute Name: the name of the attribute to be indexed (here "elementName").
Please allow some time after the dialog is closed to have Hawk generate the index.
Currently, Hawk can index attributes with strings, booleans and numbers.
Indexing will speed up not only =, but also > and all the other relational operators.
Managing derived attributes and references¶
Sometimes we will need to filter model elements through a piece of information that is not directly stored among its attributes, but is rather computed from them. To speed up the process, Hawk can maintain precomputed and indexed values for these derived attributes in the graph. A derived attribute can contain a scalar value (an integer, a floating-point number, a boolean, or a string), or a collection of scalar values.
In other cases, we may want to maintain derived relationships between model elements, which were not reflected in the original model. Hawk can use the same functionality to automatically maintain these derived references, which can speed up later queries.
For instance, if we wanted to quickly filter UML classes by their number of operations, we would go to the Hawk configure dialog, select the "Derived Attributes" tab and click on the "Add" button. This dialog would appear:
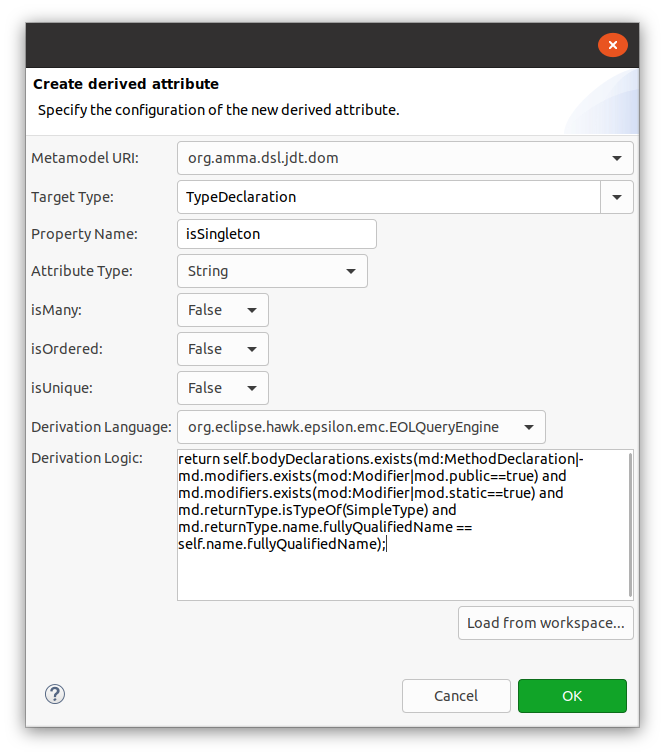
The fields are as follows:
- Metamodel URI: the URI of the metamodel with the type to be extended.
- Type Name: the name of the type we are going to extend.
- Attribute Name: the name of the new derived attribute (should be unique).
- Attribute Type: the type of the new derived attribute.
- isMany: true if this is a collection of values, false otherwise.
- isOrdered: true if this is an ordered collection of values, false otherwise.
- isUnique: true if the value should provide a unique identifier, false otherwise.
- Derivation Language: query language that the derivation logic will be written on. EOL is the default choice.
- Derivation Logic: expression in the chosen language that will compute the value.
- For a particularly long expression, it is best to write it in a separate
.eolfile and use the "Load from workspace..." button to load it into the field. - Hawk provides the
selfvariable to access the model element being extended. - If the computed value is a scalar value or a collection of scalar values, Hawk will create a derived attribute. On the other hand, if the computed value is a model element or a collection of model elements, Hawk will create a derived reference.
- For a particularly long expression, it is best to write it in a separate
For this particular example, we'd set the fields like this:
- Metamodel URI: the URI of the UML metamodel.
- Type Name: Class.
- Attribute Name: ownedOperationCount.
- Attribute Type: Integer.
- isMany, isOrdered, isUnique: false.
- Derivation Language: EOLQueryEngine.
- Derivation Logic:
return self.ownedOperation.size;.
After pressing OK, Hawk will spend some time computing the derived attribute and indexing the value. After that, queries such as return Class.all.select(c|c.ownedOperationCount > 20); will complete much faster.
Querying the graph¶
To query the indexed models, use the "Query" button of the Hawk view. This dialog will open:
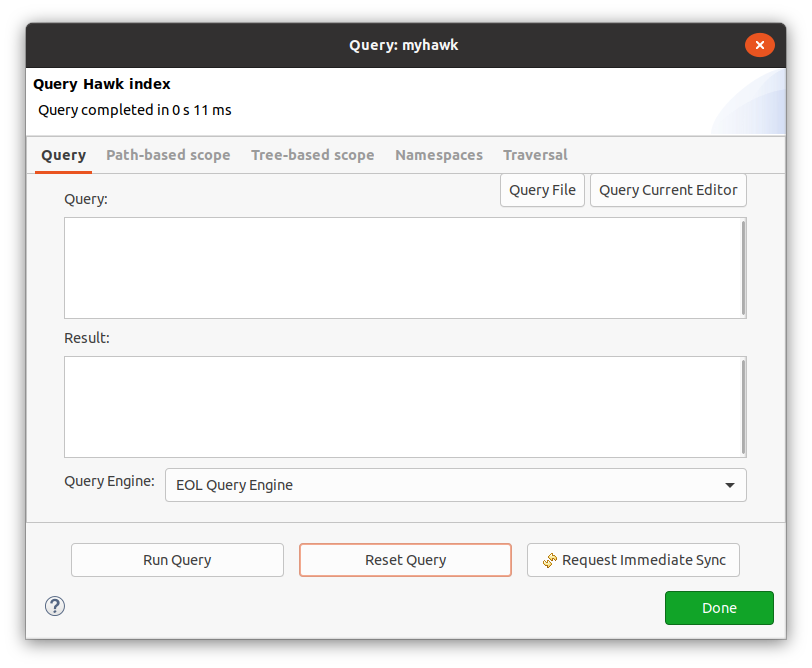
The actual query can be entered through the "Query" field manually, loaded from a file using the "Query File" button, or loaded from the currently open editor through "Query Current Editor". The query should be written in the language selected in "Query Engine".
Running the query with "Run Query" button will place the results on the "Result" field.
Resolving ambiguous names¶
In some cases, you may have registered multiple metamodels (with different namespace URIs) that contain types with the same name (e.g. two metamodels may define a Class type).
One solution is to use `namespace`::Class, but this may be unwieldy if you need to refer to the same type multiple times.
Alternatively, you can list namespace in the "Default Namespaces" field of the "Namespaces" tab.
This field takes a list of comma-separated namespaces, which will be tried in that order to resolve types without explicit namespaces.
Limiting query scope¶
By default, the query covers all files indexed across all repositories. This can be controlled in several ways, using the options in the "Path-based scope", "Tree-based scope", and "Traversal" tabs.
Path-based scope¶
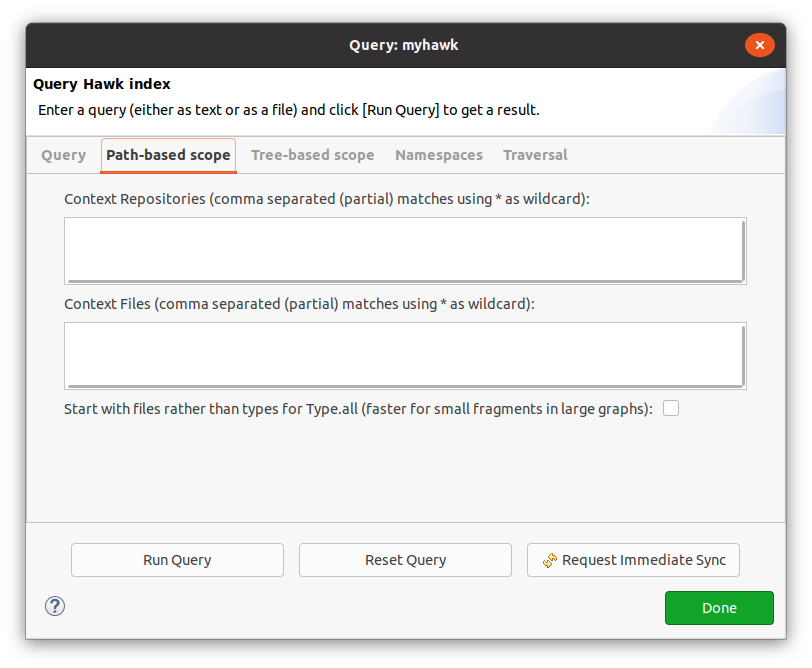
One option is to limit the set of repositories and files that will report results through the query.
Both Context Repositories and Context Files can take a comma-separated list of patterns, which can use "*" as a wildcard for zero or more characters.
It is also possible to change how Hawk traverses the graph to find all the instances of a type.
If the Start with files box is checked, Hawk will first find the matching repositories and files and then filter their contents by type, instead of finding all the instances of the type and filtering them by file and repository.
This can be faster if only a small subset of the files should be traversed within a very large fragmented model.
Tree-based scope¶
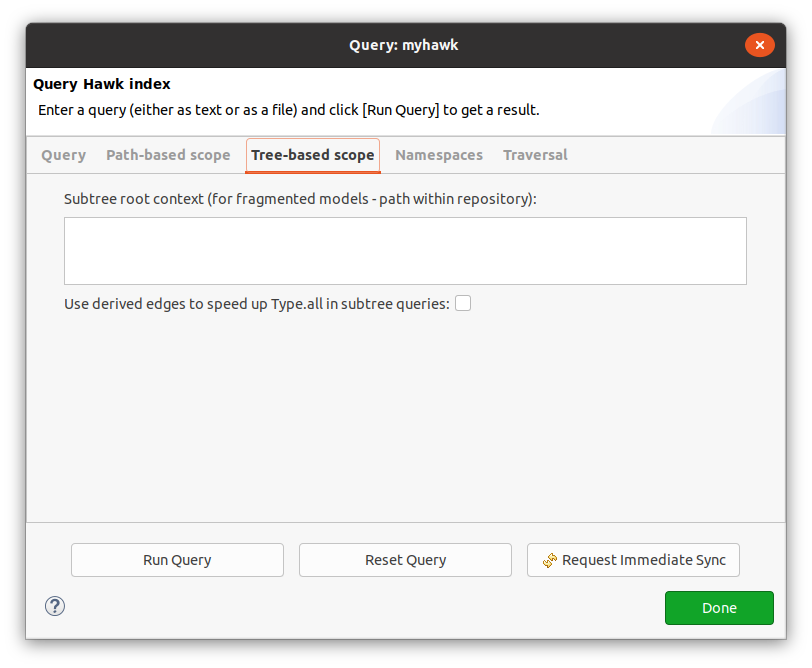
Instead of path-based scope, tree-based scope can be used to take advantage of the containment relationships already present in models that are fragmented (i.e. broken up into multiple files).
Suppose that you have a folder like this:
/root.xmi: root model fragment representing the whole system./a/component.xmi: model fragment for a component within the system./a/b/subcomponent.xmi: model fragment for a subcomponent within the system.
You can use /a/component.xmi in the "Subtree root context" to limit the query to only the model elements within that component.
If you tick "Use derived edges", when querying YourType.all Hawk will automatically extend the type of the root element of the subtree root context with allof_YourType derived references to speed up later queries.
Traversal¶
By default, the above scopes only limit what is returned from Type.all queries: they do not prevent a query from "escaping" its original scope by following references, for performance reasons.
If you would like to ensure that all references are limited to the specified scope, tick the "Enabled Full Traversal Scoping" option. This may have a significant effect in performance, as it will require following several other edges for every reference being followed.