Hi Rocky,
Thanks for investigating this. You are right, the algorithm to
iterate the state system callstack is a very naive one, using
single queries to parse pretty much the whole state system. While
it works and is easy to verify and test, it can be greatly
improved.
One other step would be to revisit this algorithm and use other
more powerful queries instead, but calls would not be visited
chronologically so each function will have an unknown parent for a
while... So this is easier said than done. But since with
callstacks the parent ends after the child, reading the state
system from end to beginning could help avoid unknown parents for
a while.
But if we can do this, then multithreading it would be much
easier! State Systems in read mode are [supposed to be] very
thread-safe.
But indeed the easiest would be to save the callgraph to file.
That's something I intended to experiment on in a near future for
the "Generic callstack" feature of the incubator. Save it in such
a way that it is also easy to produce statistics and flamegraphs
for a time selection as well. (Shameless plug, here's a post I
just wrote about the data-driven callstack in the incubator,
introducing the feature by the same occasion [1]). I was thinking
along the lines of saving it to a state system where the
attributes represent the symbols and their children are their
symbol callees and save the call count for each. Doing a full
query at 'begin' and 'end' would allow to easily rebuild the
callgraph. But it remains to be tested. If you have other ideas
for this, we'd gladly discuss and review!
I'm also working on benchmark for this analysis so we have a
baseline to compare the different approaches. Benchmarks are on
gerrit and for the incubator so far, but I plan to make their
equivalent for main Trace Compass.
Thanks,
Geneviève
[1]
http://versatic.net/tracecompass/incubator/callstack/2017/11/27/tale-generic-callstack.html
On 2017-11-27 10:36 PM, Rocky Dunlap -
NOAA Affiliate wrote:
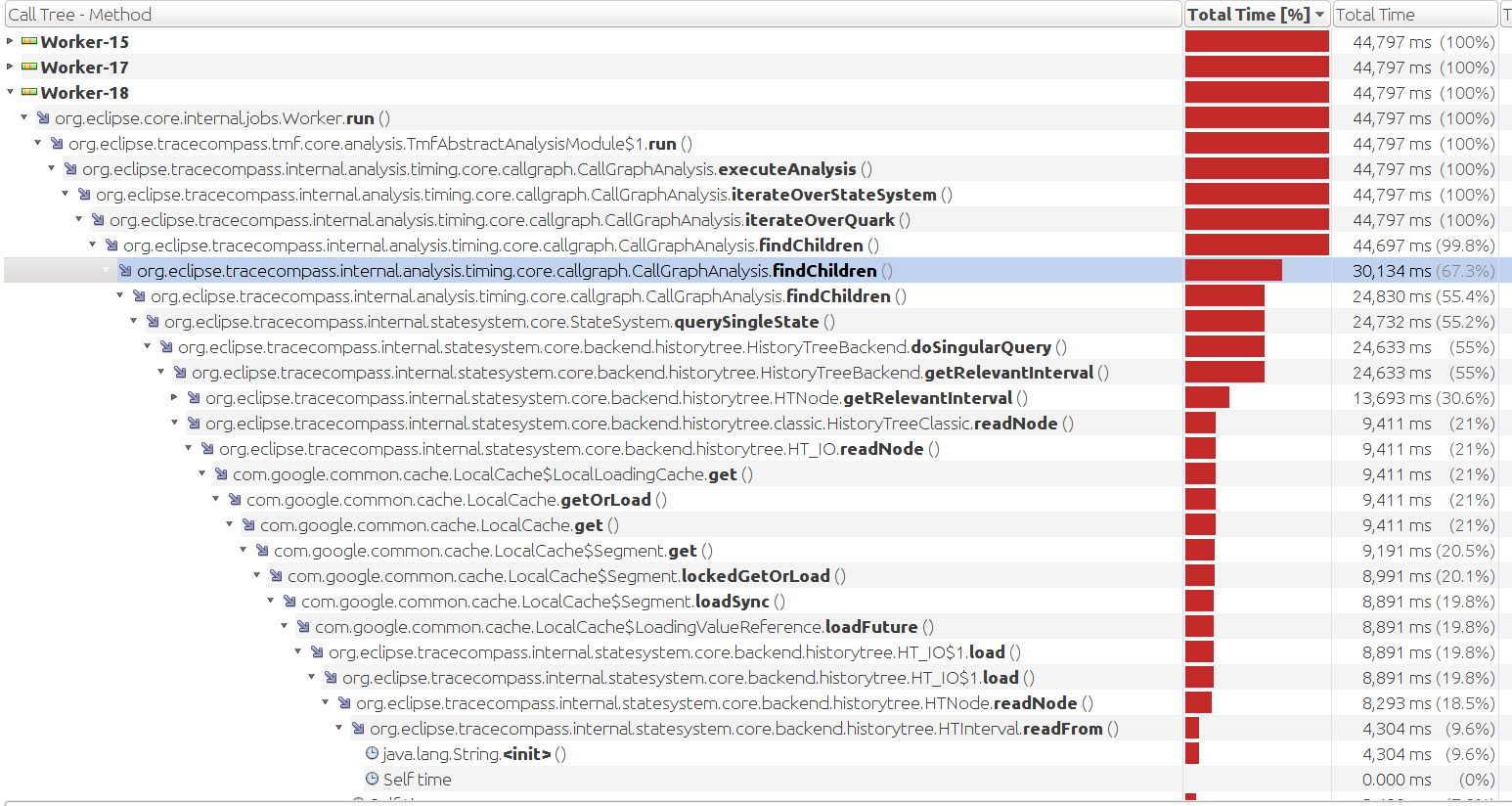
Our traces tend to have a lot of threads and generate large
call stacks. The CallGraphAnalysis is taking a bit longer to
run that I would prefer, so I've done some very preliminary
profiling. Looks like almost all of the time is spent
querying the state system:
I have some options in mind, but before diving into anything, I
thought I would get insight from this group about what is likely
going to be the best approach. Some ideas for your
consideration:
1. Could the CallGraphAnalysis state be written out to
file instead of rebuilding it each time?
2. It is currently single threaded. What is the
concurrency policy for StateSystem? If more worker threads
were used, what is the likelihood of speeding this up vs. just
having a lot of contention on the back end? Are the
StateSystems thread safe?
3. What is the indexing strategy, if any, and could that
be improved for the kinds of queries issued by the
CallGraphAnalysis?
I think these are roughly in the order of easiest to
hardest. There are probably other options as well. Doing 1
at a minimum seems not too bad. Thoughts?
Thanks,
_______________________________________________
tracecompass-dev mailing list
tracecompass-dev@xxxxxxxxxxx
To change your delivery options, retrieve your password, or unsubscribe from this list, visit
https://dev.eclipse.org/mailman/listinfo/tracecompass-dev