Ah, forgot to attach a GC Root of Test Result if I exclude weak
reference
- Winston
On 3/6/12 9:39 AM, Winston Prakash wrote:
On 3/4/12 5:10 AM, Henrik Lynggaard Hansen wrote:
Hi
Any update on below?
From my investigation it seems we already have #1, but I
would like to add another suggestion
Replace any homegrown multi threading solutions like
OneShotEvent with the java standard libraries
I agree with you on that. There are other classes like
CopyOnWriteArrayList etc also could be replaced with Standard one
See my comments below
Best regards
Henrik
On Feb 22, 2012 10:40 PM, "Winston
Prakash" < winston.prakash@xxxxxxxxx>
wrote:
Hi Henrik,
Thanks, I'll go through this and answer in detail. Mean
while you might want to read the threads at Eclipse cross project where we are
discussing about Hudson performance.
- Winston
On 2/22/12 1:33 PM, Henrik Lynggaard Hansen wrote:
Hi
Before I get to the actual suggestions, here are some numbers from our
Hudson installation to give you a sense of scale I used
http://wiki.hudson-ci.org/display/HUDSON/Monitoring. Perhaps winston
or someone can provide similar from the internal oracle instances or
the eclipse instances?
Number of jobs: around 600, but properly one around 400 active at the moment
Number of builds kept: 30.000
Number of slaves:60 (many of these are host specific nodes which are
inactive for parts of the day)
Number of http requests per minute (daytime): average around 1400-1600
with peaks of 2500
Number of http request served in a day: 730.000 measured but we had
to reboot Hudson because it was hanging so I would estimate around
800.000-900.000 would be more realistic
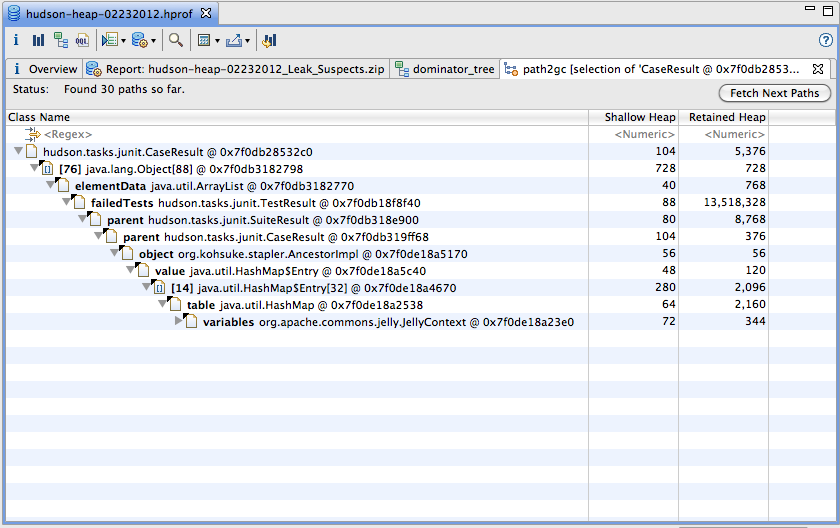
I've analyzed several heap dumps from Eclipse foundation Hudson
instance. It is clear retaining all the builds in the memory has
tremendous effect on the memory consumption. As you mentioned
JUnit are weakly referenced with in the builds. However, there are
direct reference to them via Jelly tag which displays the JUnit
which causes the retaining of CaseResults longer than intended.
This is I found via the GC root analysis.
(See the attached screenshots)
As we discussed in the Governance meeting, we need to visit the
concept of "lighter metadata in memory".
I had to disable the moniroting plugin again because it has too big
overhead and we would need to reboots during office hours. I am still
working on getting some stats on which URLs are being hit the most.
This installation is not fully sized, we will need to grow it
significantly as we add more projects.
Anyways onwards to my suggestions:
1. Create a static folder served by the container:
Move all static content (help pages, logo etc.) to a separate folder
and exclude that URL pattern from stabler. This way it should be
served by the container and much better cached, or proxied
As per your experiment, Hudson servlet does set the expiry
correctly for static contents. However, downloading large
artifacts via Hudson servlet concerns me. End user should try to
use directly the proxy server such as Apache for such purpose.
2. Don't generate semi-static content:
It looks like semi-static content such as RSS feeds are generated
using jelly templates on each request which seems quite expensive.(I
suspect rss request make up the bulk of my 730.000 requests). Suggest
we move to a model where such
resources are written to disk when it changes which is far less often
than it is requested.
We then make a fast path in stabler where the first thing it does is
look into a map of URL, and if the URL is present in the map the file
on disk is served directly instead of going through stabler "views".
Plugins could even take part in this be writing files to disk and
registering the URL to file mapping via a service. I suspect this
could speed up things quite a bit since plugins could write all sorts
of resources that only needs to be calculated once a build is done
like change logs, test reports, dependency graphs etc. (we need to
figure out something with the dynamic sidebar but still)
(if someone can give me a pointer to the good starting points in the
code I would like to give this a go)
Your suggestion seems like a good option. I'll look in to the code
and let you know
IMO, RSS are served on demand. Wondering who is causing the
traffic of 730.000 requests
3. Don't reserve a thread per executor.
As soon as a slave goes on line there is created a executor thread for
each executor. There really is no need for this, just create the
threads as needed
Executor is a thread. Threads are lightweight, so should not a
resource contender. However, I do noticed GC roots ending at these
Executors. Modifying the code to create the thread as needed
significantly changes the Execution model, but worth looking in to
it.
4. Revisit master slave handshaking
I am not sure how master/slave communications are initiated, but I
think it might be different based on the slave type. SSH slaves appear
to keep using the SSH channel opened during startup, while JNLP slaves
"phone home" to a server socket but both reserve a thread on the
master. I suggest we make use of a server socket approach on all slave
types as a default and use the "master calls slave" as fallback. This
will allow us to use NIO and a thread pool instead of reserved threads
on the master.
IN case of JNLP handshake is done via server socket and the stream
channel pipe is created using input and output stream of the
connected socket. However in case of SSH slaves, the channels are
bound to the standard output and input of the SSH session. You
mean to say we need to try to use server socket on both cases and
just use SSH only to start/restart the slave?
What do you mean by "master call slave"? Isn't it slave initiates
the communication in case of Slave restart?
5. Pre-compile / pre-assemble jelly?
I don't know if it is possible but right now the jelly files are
re-parsed on request (as far as I can tell), is there a technique
where we can precompile sush files or perhaps just pre-resolve all the
includes and build a jelly file per page?
I think this is not possible and should not happen. It defeats the
purpose of server based rendering. However, we need to investigate
the option of caching in stapler. That is served the cached
rendered page, until the cache time out expires. Not sure if it is
there already.
- Winston
|