|
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #674485 is a reply to message #674422] |
Fri, 27 May 2011 06:27   |
|
After thinking about it for a while:
Using JaroWinkler is just a guess what algorithm might work well for this. This means it may turn out that it is a perfect match - or not. How do you feel about using SimMetrics for a proof of concept just to see how it works? Then we could easily use different metrics to evaluate how they perform w/o efforts implementing them from scratch.
Since this code cannot go to Eclipse then, Johannes could create a public git repository on our repository hosting server so that we can share the intermediate results outside Eclipse (w/o licensing issues) and integrate it into our CI server.
How about that?
[Updated on: Sun, 05 June 2011 09:56] Report message to a moderator |
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #675399 is a reply to message #674537] |
Tue, 31 May 2011 11:58 |
|
Hello,
I found that we may use Levenshtein distance algorithm (http://www.merriampark.com/ld.htm). It seems like it likely matches to what we are looking for to compare our subwords... Tell me if I'm wrong.
This algorithm is quite simple to implement, as I have already written a simple 50 lines utility that seems to work efficiently.
I only found one limitation : it seems that some implementations rise OutOfMemory errors when comparing long strings... But I think we will not face this problem in our use case.
I can provide my snippet if needed.
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #675412 is a reply to message #675399] |
Tue, 31 May 2011 12:47 |
|
Levenshtein is great for very similar words and slightly misspelled ones (typos). One drawback with Levenshtein is that it does not prefer common prefixes over general matches - a feature which seems valuable as pointed out by Deepak in the blog post. But I also came across Levenshtein and wasn't sure which one to take. That's why I asked for a recommendation at SimMetrics forum a two weeks ago:
http://sourceforge.net/projects/simmetrics/forums/forum/621875/topic/4535973
How about that:
Implement both and create a "benchmark" for both approaches, i.e., a few samples that show how code completion would work with Levenshtein and JaroWinkler? Later we may make the completion algorithms exchangeable to see how both work and to ease switching to newer ones?
What do you think?
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #676031 is a reply to message #673616] |
Thu, 02 June 2011 15:01 |
|
Hello,
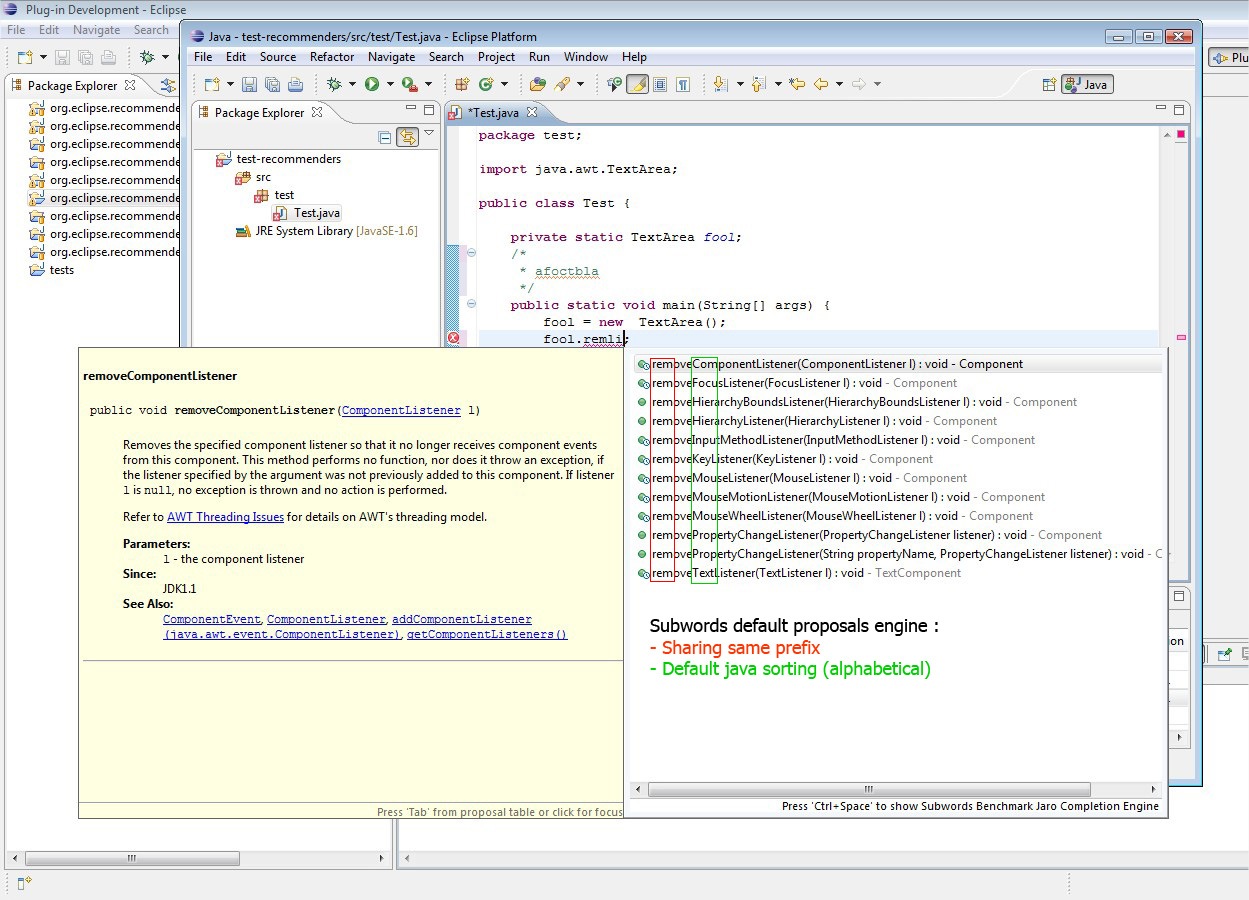
Well, I just finished implementing a "benchmark plugin" in order to compare proposals ranking algorithms efficiency. Results are very interesting.
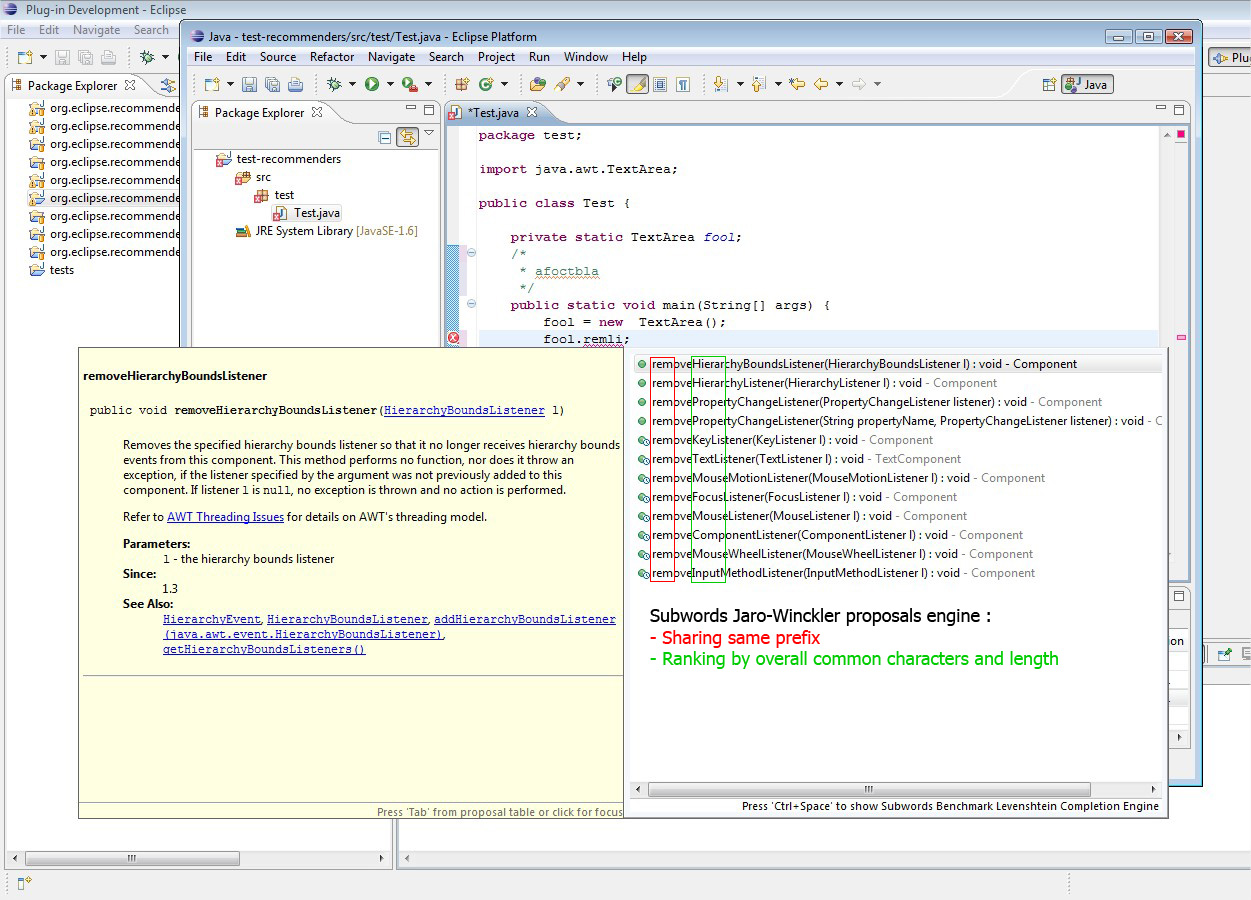
Here is what I did : I added, besides default subwords proposals, two other engines that add relevance ordering on proposals using respectively Jaro-Winckler and Levenshtein algorithms (that I coded from scratch as needed by EPL, helped by descriptions found on the web).
I made some screenshots to illustrates all of this :
- Default Subwords Engine
- Jaro-Winckler algo.
- Levenshtein algo.
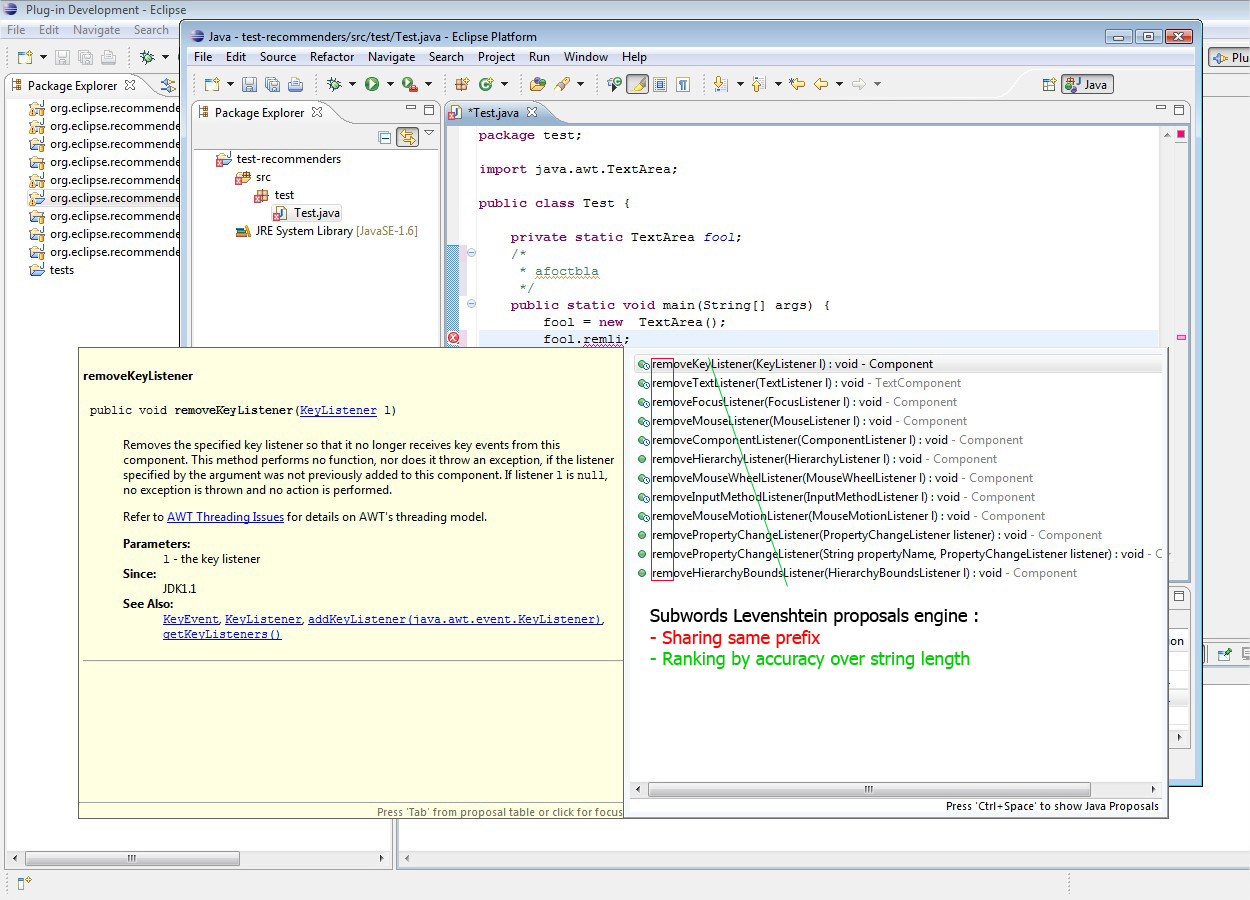
As you can see, Levenshtein algo is very interesting to sort items by accuracy. In some cases, Jaro algo may be confusing (ends with melted results, less understandable). Thus, even if both algos compare strings letter by letter, Levenshtein's one seems to prior matching "subwords" as we intend it (successions of similar letters) while Jaro's one simply counts matching letters on the whole strings.
One major problem risen by this feature is that it mixes methods and fields proposals... It is quite frustrating when using completion. I think we will have to implement extra proposal sorter extension to keep original presentation (first methods, then fields...)
More tests have to be done to check possible limitations on multiple use cases but I can already say that I did not notice any performance loss in diplaying proposals. As images show, I tested on TextArea object that holds lot of items.
I can provide sources if you decide to check by yourself.
I am still running some tests to see how these algo behave with upper/lower-case characters and if they entirely take into account "subwords" as we need it.
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #676560 is a reply to message #673616] |
Sun, 05 June 2011 09:01 |
|
Hello!
Some news about the algorithms. After some tests, I found some limitations on our current usage.
I worked mainly on Levenshtein's one since it seems to be cleaner for what we want (at least for now).
First limitation is that it lacks of weighting results on common prefix share : tell me if I'm wrong, but we want to prior proposals that share common prefixes, right? But here is what I have on a simple example :
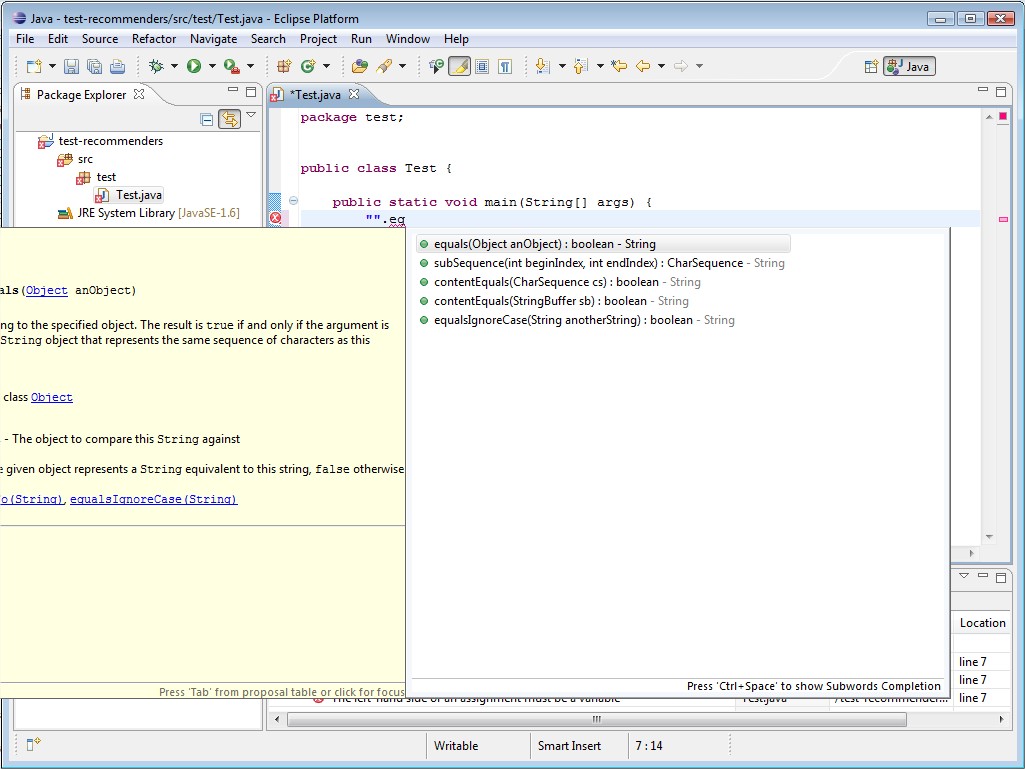
As you can see, "equalsIgnoreCase" is thrown to the bottom of the list due to its length... So, I tried to find an extension of this algo that could leverage results with common prefix length. I could not find precisely what I wanted (if you know some, please let me know) so I tried to add a home-maid calculation to get more precise results. Here is what I get :
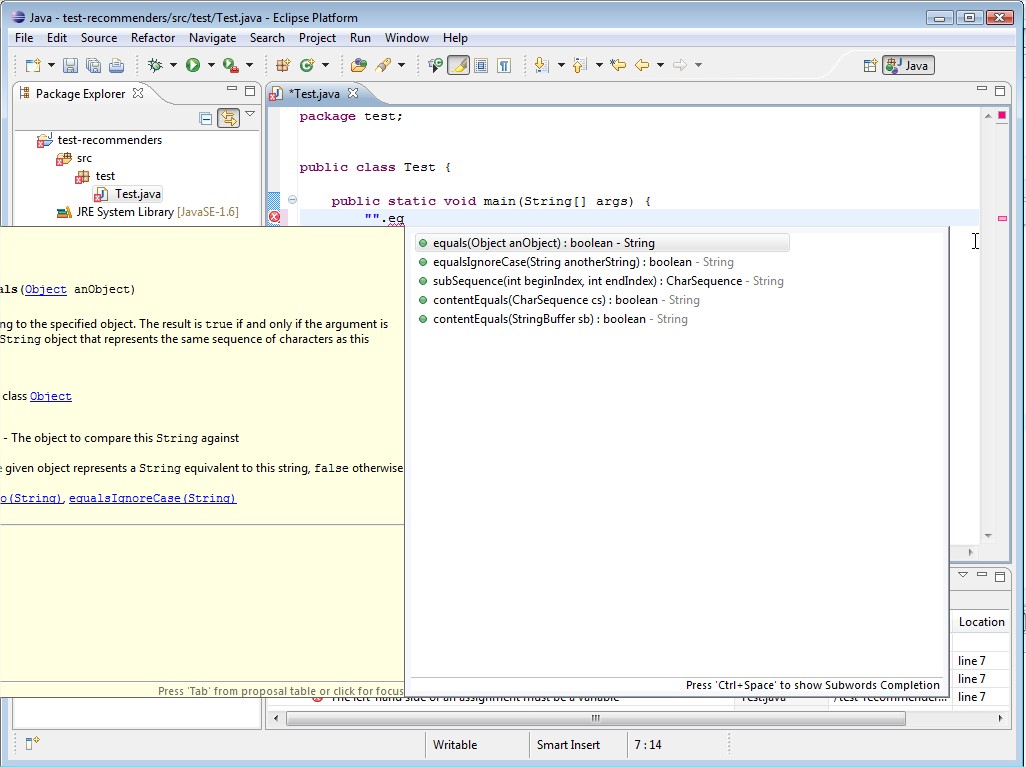
Now, Levenshtein result is leveraged with a common prefix care. I don't really know if my calculation is entirely correct, but it is quite simple and for now it seems quite acceptable.
The second limitation is that Levenshtein does not really take into account subwords as we intend it. See :
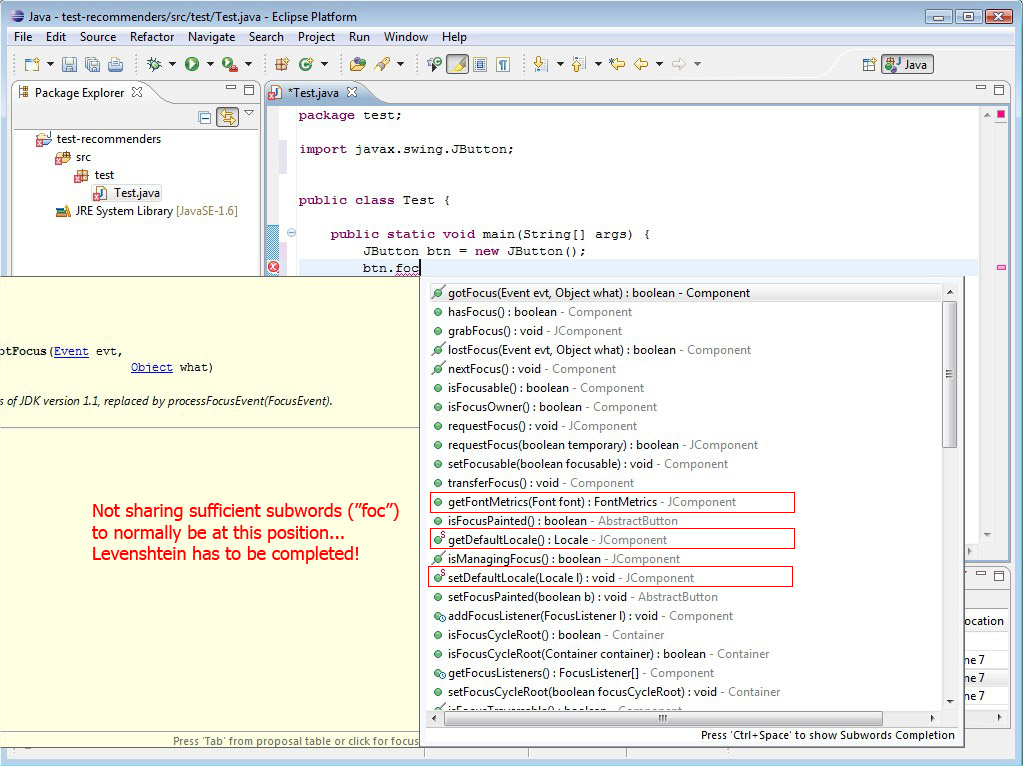
So I will try to find improvements, but keep me aware of what you about that...
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #676611 is a reply to message #676567] |
Sun, 05 June 2011 17:36 |
|
Hi,
Well I read some papers about n-grams counting, it is quite interesting! But I have a question about all of that : how should we leverage Levenshtein result with this algo and "my" prefix matching? I mean : for now, Levenshtein give us the differences count between strings. Then, I substract my home-maid calculation to reduce the gap depending on prefixes. Now n-grams could give us some more matching count, but what weight should we give it regarding the others?
Another related question : what n-gram should we use? I think that 3-gram is the most interesting in our use case. But we may try to also look for 4-grams ou 5-grams to increase subwords' length matches and proposal relevance... But this kind of search seems a little bit greedy in calculation time...
What do you think?
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #676617 is a reply to message #676611] |
Sun, 05 June 2011 17:55 |
|
I think 2- or 3-grams should be fine, right? In addition: No matter what works best at then end, in a smart implementation this just a configuration param 
Regarding combination of n-grams with Leventshtein: Do you already see an advantage of combining both metrics? I can imagine to just use your prefix scoring + n-grams. However, "scoring" is something that we can "learn" later on. Literally
You may just come up with a weighted sum formula that considers all three metrics. The weights then can be tweaked later on (after we have some user data) to find the best weights for them. This project is getting more and more interesting
See http://en.wikipedia.org/wiki/Weight_function for what I mean with a weighted sum formula.
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #676629 is a reply to message #676617] |
Sun, 05 June 2011 19:02 |
|
Right... My fear about a sum formula is that it might be too much time consuming for all proposals. And I am not sure that users might be able to choose between some strategies to sort proposals (if we let them chose by configuration).
All those ideas are interesting but for our project I think we have to make a choice or we will scatter in too complex computations, won't we?
The more I read docs about n-grams the more I think I might be more pertinent to our problem : when users type a few letters and invoque content assist, they may have a little idea of what they are looking for. I think they may have typed succession of subwords rather than random letters. So Levenshtein loses weight compared to n-grams + prefix scoring, what do you think? In this point of view, we may prefer implement the second strategy rather than Lvenshtein's one.
Don't hesitate to contradict me, I'm just thinking aloud!
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #676640 is a reply to message #676629] |
Sun, 05 June 2011 20:43 |
|
Hi Pef,
I would propose to go for n-grams + prefix bonus. That's a quite nice set of algorithms you implemented in just one week
Regarding your computation "fear" (here we drift little bit more into research ideas - you may skip this )
The scoring and evaluation can also be done "post mortem", i.e., if we track what tokens the users enter and what they finally selected from the proposal list, we get into the comfortable position to know what would have been the best solution. Think of it as some kind of feedback a programmer gives you what was actually relevant.
For illustration:
Given a programmer enters "gl" and triggers code completion.
The system now proposes, say, 20 elements that match the regex "gl".
She then selects "getLayoutData()" from the list of proposals.
Now assume you have such kind of information for a few thousand completion events. With this data you can replay the completion events and try out several ranking strategies and identify the one that performs best over all queries, i.e., presents the actually selected proposal on the highest position most of the time.
With such an approach it becomes quite easy to evaluate which algorithm works best or whether we should use a weighted scoring function etc. We just have to share the completion events... But as I said, with this we would get more and more into research. On the other side I'm sure that such a system would probably be the most advance (context-free) completion system Eclipse has ever seen Anyways, let's see how q-grams works out first
Best,
Marcel
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #683490 is a reply to message #683485] |
Mon, 13 June 2011 21:11 |
|
Hi Pef,
can you make the Eclipse source project available? I'm having trouble to execute your jar since my paths and swt versions differ:
Exception in thread "main" java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.eclipse.jdt.internal.jarinjarloader.JarRsrcLoader.main(JarRsrcLoader.java:58)
Caused by: java.lang.UnsatisfiedLinkError: Could not load SWT library. Reasons:
no swt-win32-3659 in java.library.path
no swt-win32 in java.library.path
A zip of the source project should work.
Thanks,
Marcel
[Updated on: Mon, 13 June 2011 21:11] Report message to a moderator |
|
|
|
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #686383 is a reply to message #685578] |
Wed, 22 June 2011 06:42 |
 Steve Ash Steve Ash
Messages: 4
Registered: June 2011 |
Junior Member |
|
|
I'm afraid I'm just going to be offering some opinions. Don't know if it will be of value. I haven't looked at the code yet, and so my points may be uninformed.
I'm sure you've already discovered the "reward" formula in winkler-- this approach to rewarding shows up a lot: w = j + (c * 0.10 * (1 - j)) where w is the resulting winkler, j is the jaro score, c is the number of common prefix characters in [0,4] and 0.10 is the "scaling" factor. So in the edit distance apps I work on (record linkage, fuzzy searching engines, etc.) we often mess with the range of c and the scaling factor of 0.10. Sounds like youre on the right track though, given your results above.
I like the bi or tri-grams approach in general, as i feel it will be better suited than leven and jaro-- and faster. I agree with your observation though that leven and jaro both dont really give you what you want -- you want to be much more conservative in most cases. finding matches where characters are interspersed is bad. I would think the bigrams would be great at this -- and still provide resilience against misspellings. Plus there are only a few thousand unique bigrams so you can do lots of packed representation optimizations. And if you order them beforehand, then counting the common ones is O(n).
I have implementations of jaro and winkler that I could provide if you guys haven't already coded another. I haven't looked at the open source gpl one you looked at, but its probably similar. I have an "optimized" jaro which operates at O(nlogn) instead of pseudo (n^2) (technically jaro is n but doesnt act like it in practice) but I can't donate it as its covered by a patent.
In general I'm super excited about this! Let me know how I can help!
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #686611 is a reply to message #686383] |
Wed, 22 June 2011 15:32 |
|
Hey Steve,
you help is greatly appreciated. So far, Pef did most of the work on the ranking strategies. Thus, I've to catch up with his latest changes to see where we are at the moment. He's currently pushing his code to code recommenders' labs so that everyone can checkout try out the different strategies.
One thing that comes in my mind which would be great to figure out (although it's more a UI task than an algorithmic one): When you trigger code completion there is no highlighting which characters match in the proposal. IDEA has this neat highlighting (see http://goo.gl/BY0El for an example). It would be cool if you or someone else can spent a few moments to figure out whether this is possible with current implementations or how to achieve that. This is just an intermediate action until we have everything in place to get the real tool evaluation done but a neat one.
Aside this, it would be great to your feedback on the different ranking strategies Pef worked on. I think we will have all code related to the proposals engine in the lab repository by end of the week to you can see what's there and how completion works with current solution. I'll post an update if we have a lab build up an running for this.
Thanks,
Marcel
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #688300 is a reply to message #688297] |
Fri, 24 June 2011 11:54 |
|
|
Just a little precision. Looking at the screenshot I realized I forgot to specify that we are currently using a 3-gram algorithm. This seemed a pretty good choice to start with but maybe we could do more tests with 2-grams for example, or even with combinations of both. I may commit a little evolution of the tool regarding this option.
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #689064 is a reply to message #688345] |
Sun, 26 June 2011 17:41 |
|
Hi,
I added the little feature on the test tool about paramaterized Ngrams. If you test it, you could see that with 2 chars length window, we have a more precise granularity on proposals. I think this could be enhanced with common prefix weight like I added on Levenshtein.
I am also testing your scoring expectations class to see how we could converge to.
|
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #689111 is a reply to message #689110] |
Sun, 26 June 2011 21:22 |
|
i just "found" it. I though you would push directly into head. My first impression is quite good. I'll give it a try tomorrow the whole day to see how it works out in daily use.
BTW:
When I enter "acc" as input I get an exception:
---------------- Jaro-Winckler ----------------
Prefix : acc
java.lang.IndexOutOfBoundsException: Index: 1, Size: 1
at java.util.ArrayList.RangeCheck(ArrayList.java:547)
at java.util.ArrayList.get(ArrayList.java:322)
at org.eclipse.recommenders.rcp.codecompletion.subwords.benchmark.relevance.SubwordsJaroWinklerDistance.calculateDistance(SubwordsJaroWinklerDistance.java:100)
at org.eclipse.recommenders.rcp.codecompletion.subwords.benchmark.relevance.SubwordsJaroWinklerDistance.calculateRelevanceDistance(SubwordsJaroWinklerDistance.java:37)
at org.eclipse.recommenders.tests.codecompletion.subwords.benchmark.ProposalsDistanceBenchmark.testJaroDistance(ProposalsDistanceBenchmark.java:110)
at com.developpef.SubwordsBenchmark$2.widgetSelected(SubwordsBenchmark.java:157)
at org.eclipse.swt.widgets.TypedListener.handleEvent(TypedListener.java:234)
at org.eclipse.swt.widgets.EventTable.sendEvent(EventTable.java:84)
at org.eclipse.swt.widgets.Display.sendEvent(Display.java:3783)
at org.eclipse.swt.widgets.Widget.sendEvent(Widget.java:1375)
at org.eclipse.swt.widgets.Widget.sendEvent(Widget.java:1398)
at org.eclipse.swt.widgets.Widget.sendEvent(Widget.java:1383)
at org.eclipse.swt.widgets.Widget.notifyListeners(Widget.java:1195)
at org.eclipse.swt.widgets.Display.runDeferredEvents(Display.java:3629)
at org.eclipse.swt.widgets.Display.readAndDispatch(Display.java:3284)
at com.developpef.SubwordsBenchmark.open(SubwordsBenchmark.java:66)
at com.developpef.SubwordsBenchmark.main(SubwordsBenchmark.java:50)
|
|
|
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #690420 is a reply to message #689209] |
Wed, 29 June 2011 13:49 |
Johannes Lerch
Messages: 18
Registered: February 2011 |
Junior Member |
|
|
I just integrated your latest contribution. You might have to search a little to find it, as i refactored a lot of stuff. I also added some tests and found some bugs. For example i think qgrams is symmetric and your implementation was not. I fixed those issues, but i would appreciate that you will take a look on that to verify that i didn't broke it.
The main classes of interest are now SubwordsRelevanceCalculator, QGramSimilarity and the corresponding test classes SubwordsRelevanceCalculatorTest, QGramSimilarityTest and ExpectedScoringsTest. As you can see your current approach matches my expectations. Nice job!
But can you give me more details on the weighting function? What was the intent of the factor 20 and why is the difference of the length of both strings relevant?
For all who want to test the current state: Get it from the head channel. I turned off the default java proposals and will check what it feels like to only have the subwords completion.
[Updated on: Thu, 30 June 2011 07:10] Report message to a moderator |
|
|
|
|
|
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #696040 is a reply to message #673616] |
Wed, 13 July 2011 06:57 |
|
Hi,
Sorry for my absence but I just had some hard days at work... I will update your modifications and try to improve my code regarding your latest remarks if still needed. As you infered it, my weighting strategy was to prior shortest proposal matches (as Levenshtein proposed). But your choices seem interesting. I will give you my feedback as soon as I tested it.
Thanks for your investment!
|
|
|
| Re: Help Wanted: Ranking Strategy for Subwords Completion Engine [message #696053 is a reply to message #696040] |
Wed, 13 July 2011 07:43 |
|
Hi Pef,
we adapted some parts of your code. You find the latest version in the org.eclipse.recommmenders git repository. We came across an issue with relevance scoring since JDT does not support updating the relevance of a proposal. This is annoying and confusing when typing.
I'm not sure whether we can (yet) deliver the bigrams solution with that issue. I reported the issue here: https://bugs.eclipse.org/bugs/show_bug.cgi?id=350991 JDT is yet not very responsive because of the upcoming Java7 release. But I hope we'll get a solution rather soon.
In the meanwhile it would be cool if you could install the latest version from HEAD update site and give it a try?
Best,
Marcel
|
|
|
|
|
") ]
]  Search
Search Help
Help Register
Register Login
Login Home
Home








