Select and use the right open source components with Eclipse SCAVA
Eclipse SCAVA is an open source platform for automatically analyzing the source code, bug tracking systems, and communication channels of open source software projects. SCAVA provides techniques and tools for extracting knowledge from existing open source components and to use such knowledge to support the selection and reuse of existing software to develop new systems and to provide developers with real-time recommendations that are relevant to their current development tasks. Eclipse SCAVA has been created out of the EU-funded CROSSMINER project under the H2020 Programme.
As shown in Figure 1, Eclipse SCAVA fits conceptually between the developer and all the different and heterogeneous data sources that one needs to interact with when understanding and using existing open source components.
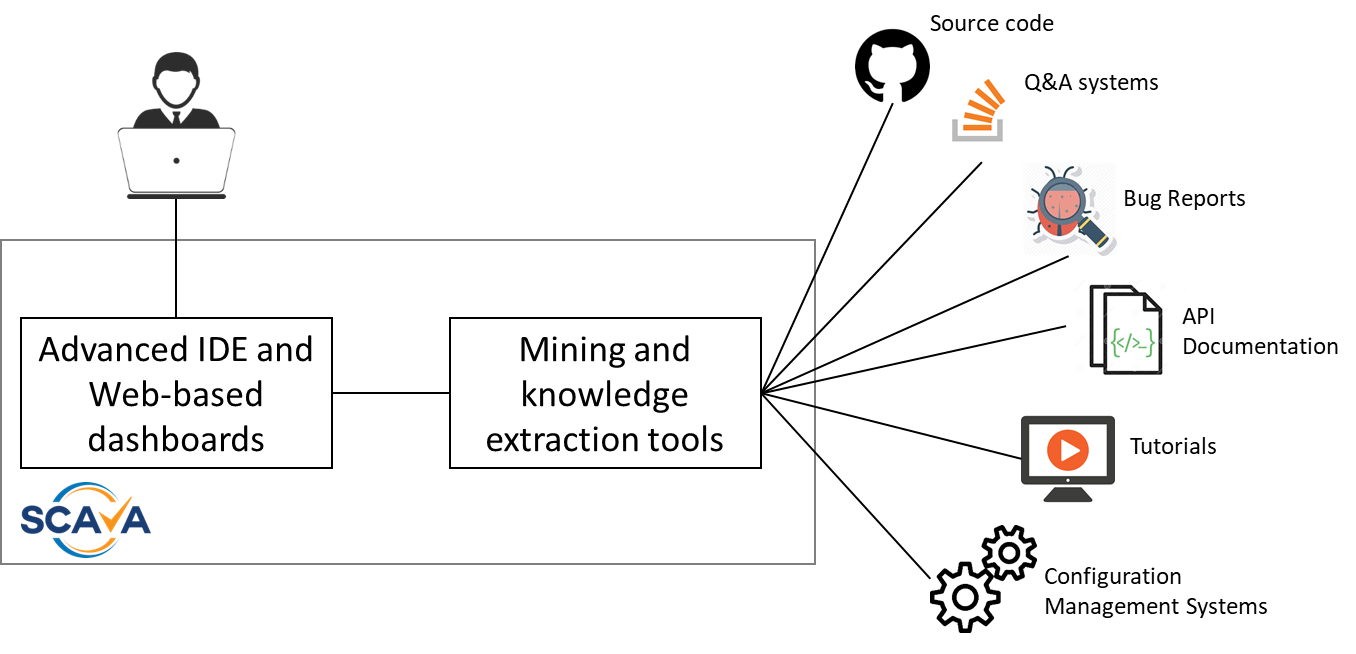
Figure 1: Overview of Eclipse Scava
Recommender systems typically implement four main activities i.e., data preprocessing, capturing context, producing recommendations, presenting recommendations. In this respect, both the Eclipse-based IDE and the Web-based dashboards make use of data produced by the mining tools working in the back-end of the Eclipse SCAVA infrastructure.
The developer context is used as a query sent to the knowledge base that answers with recommendations that are relevant with respect to the developer contexts. Machine learning techniques are used to infer knowledge underpinning the creation of relevant real-time recommendations. The knowledge base infers more insight from raw data produced by the different mining tools, which include the following:
- Source code miners to extract and store actionable knowledge from the source code of a collection of open source projects;
- NLP miners to extract quality metrics related to the communication channels, and bug tracking systems of open source projects projects by using Natural Language Processing and text mining techniques;
- Configuration miners to gather and analyze system configuration artifacts and data to provide an integrated DevOps-level view of a considered open source project; and
- Cross-project miners to infer cross-project relationships and additional knowledge underpinning the provision of real-time recommendations.
Additionally, Eclipse SCAVA provides the means to simplify the development of bespoke analysis and knowledge extraction tools by delivering a framework that will shield engineers from technological issues and allow them to concentrate on the core analysis tasks instead.
The SCAVA Eclipse-based IDE and Web-Based Dashboards
The Eclipse SCAVA technical offering consists of several components that can be either singularly used or developers can benefit from integrated ways of using them via an Eclipse-based IDE and Web-based dashboards. Recommendation examples that Eclipse SCAVA is able to produce are shown below.
Recommending Additional Libraries
As shown in Figure 2, depending on the set of third-party libraries currently being used by the software system being developed, Eclipse SCAVA can recommend additional libraries that should be included. Such recommendations are based on the similarity of the considered software system under development with respect to already existing and analyzed libraries.
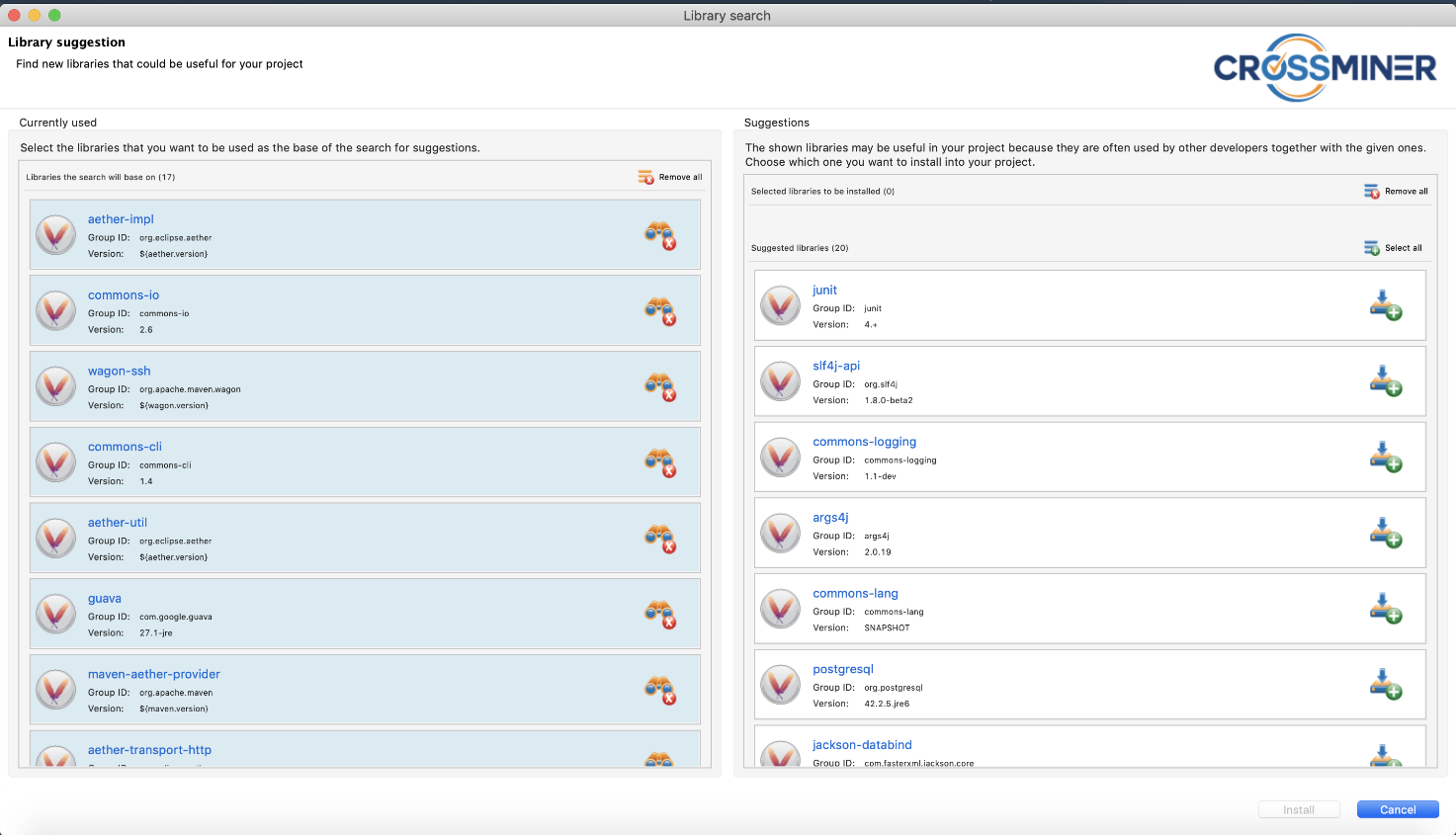
Figure 2: Suggesting additional libraries
Recommending API Documentation
Depending on the set of selected libraries, the system shows API documentation and Q&A posts that can help developers understand how to use the selected libraries. Figure 3 shows a list of ranked StackOverflow posts that are recommended with respect to their relevance to the selected source code directly in the editor.
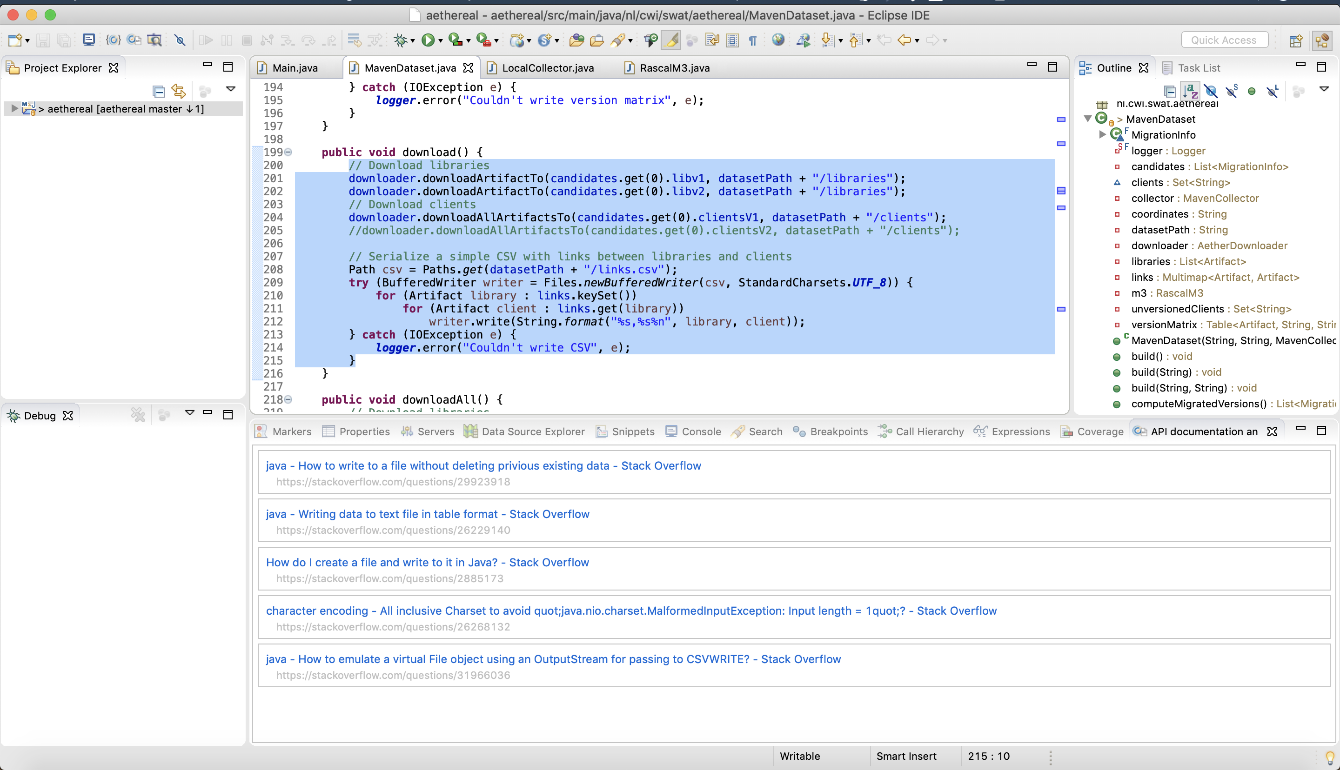
Fig 3: Recommending Stack Overflow posts
Recommending API Function Calls and Usage Patterns
Eclipse SCAVA is also able to recommend API function calls that the developer might need to add to the method being developed. For instance, Figure 4 contains a representative example where the findBoekrekeningen method queries the available entities and retrieves those of type Boekrekening. To this end, the Criteria API library is used. The situation shown in Figure 4 is when the development is in an early stage and the developer already used some methods of the chosen API to develop the required functionality. However, they are not sure how to proceed from this point. In such cases, different sources of information may be consulted, such as StackOverflow, video tutorials, API documentation, etc. For instance, by providing the first three statements of the findBoekrekeningen method declaration, Eclipse SCAVA can provide developers with recommendations consisting of a list of API method calls that should be used next, and code snippets that could support developers in completing the method definition with the framed code in Figure 4.

Fig 4: Recommending API function calls
Web-Based Dashboards
Eclipse SCAVA dashboards present up to date, high level, and quantitative panoramic views of analyzed projects. They include specific metrics for tracking key performance aspects and show details like who and how they are contributing to a given project. Dashboard panels show summary, aggregated and evolutionary data, statistical analysis, faceted views, etc. for each data source. The interface allows drilling down into the data combining different filters (time ranges, projects, repositories, contributors). NLP analysis tools can also be applied to retrieve all the sentiments related to the analyzed projects. For instance, Figure 5 shows an interactive Wheel of Emotions that can be used to filter the sentiments shown in the dashboard.
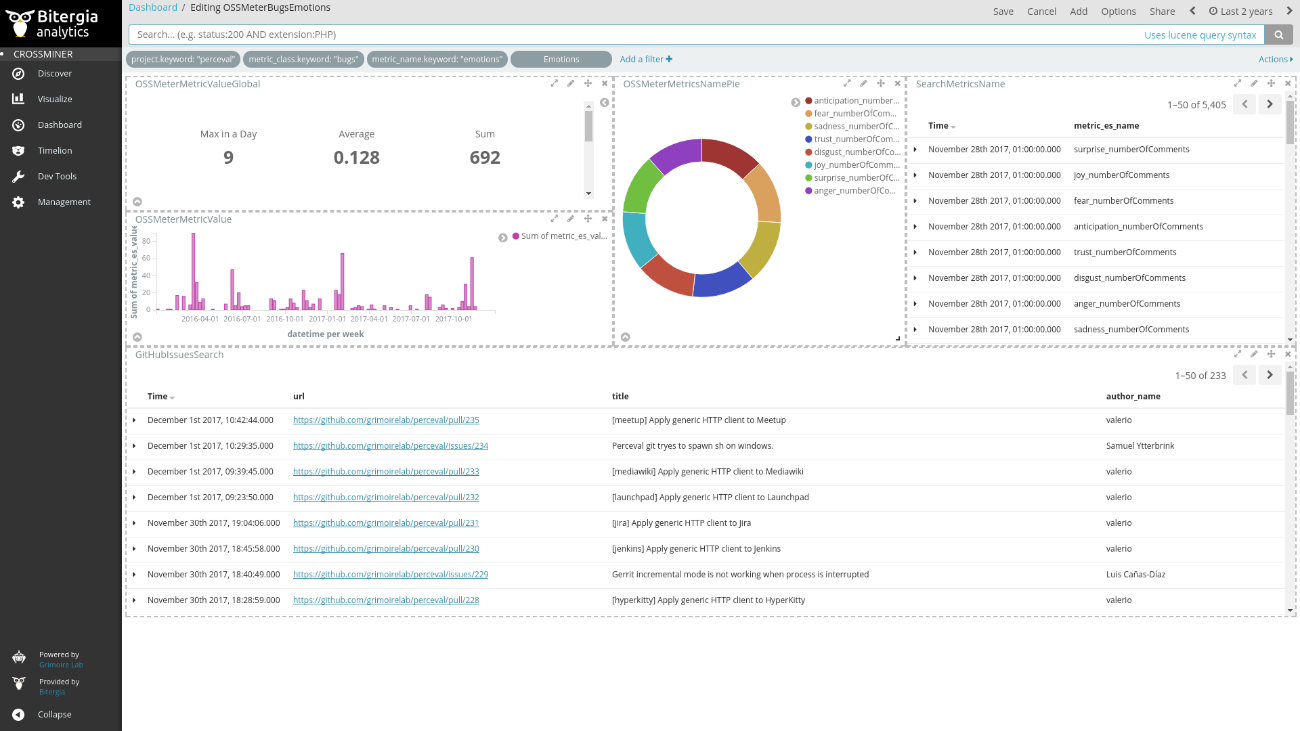
Fig. 5: Evolution in time of Sentiments in Issues
References
Eclipse SCAVA has been created out of the EU funded CROSSMINER project (https://www.crossminer.org/) which has been supported under the Horizon 2020 Programme. For details about the installation and usage of ECLIPSE SCAVA, please refer to https://scava-docs.readthedocs.io.
Authors of Article
| Author | |
|---|---|
 |
Davide Di Ruscio is an Associate Professor at the Department of Information Engineering Computer Science and Mathematics of the University of L'Aquila. His main research interests are related to several aspects of Software Engineering, Open Source Software, and Model-Driven Engineering (MDE) including domain specific modelling languages, model transformation, model differencing, model evolution, and coupled evolution. He has been in the PC and involved in the organization of several workshops and conferences, and reviewer of many journals like IEEE Transactions on Software Engineering, Science of Computer Programming, Software and Systems Modeling, and Journal of Systems and Software. He is a member of the steering committee of the International Conference on Model Transformation (ICMT), of the Software Language Engineering (SLE) conference, of the Seminar Series on Advanced Techniques & Tools for Software Evolution (SATTOSE), of the Workshop on Modelling in Software Engineering at ICSE (MiSE) and of the International Workshop on Robotics Software Engineering (RoSE). Davide is in the editorial board of the International Journal on Software and Systems Modeling (SoSyM), of the Journal of Object Technology, and of the IET Software journal. Since 2006 he has been working on different European and Italian research projects by contributing the application of MDE concepts and tools in several application domains (e.g., service-based software systems, autonomous systems, open-source software systems, and hybrid polystore systems). Currently, Davide is the technical director of the H2020 CROSSMINER project https://www.crossminer.org/. More information is available at http://people.disim.univaq.it/diruscio. |
 |
|
 |
|---|