GeoWave 1.0 - Scalable Retrieval and Analysis to Massive Spatial Datasets

LocationTech GeoWave is an open source software library that connects the scalability of distributed computing frameworks with modern geospatial software to store, retrieve, and analyze massive geospatial datasets. GeoWave enables data scientists, analysts, and others to effectively query and analyze massive datasets when traditional geospatial software tools are not capable of doing so.
At the core of GeoWave is the capability to store, retrieve, and analyze multi-dimensional data structures within distributed key-value stores. Spatio-temporal data serves as a primary special case of multi-dimensional data for which GeoWave provides tailored extensions. GeoWave is intended to be easily pluggable into any sorted key-value store, including current, fully-supported implementations available for Apache HBase, Apache Accumulo, Apache Cassandra, Redis, RocksDB, Google BigTable, and Amazon DynamoDB. This also includes near-term plans to add Apache Kudu support. The datastore support is provided as an extension that is discoverable at runtime. Access to the GeoWave programmatic API, command line, or service will be syntactically the same for all key-value stores. Furthermore, there are optimized data transfer utilities across supported stores so your data can be expediently moved to an appropriate storage system. This approach provides seamless transitions of scale from embedded applications and external in-memory services all the way up to more common applications within highly distributed ecosystems.
While "scalable" typically implies massive distributed systems, we've found great success in also catering to smaller-scale use cases with the benefits of being able to seamlessly scale up to the "mind boggling." GeoWave's full-featured support for a large variety of key-value stores has provided an inherent ability to leverage the right storage technique for the right job. In particular, this has proven invaluable for generic multi-dimensional indexing within maps, timelines, and graphs embedded in analysis tooling (pictured below). The power of "scalability" is truly achieved when a user applies the same techniques and methodology regardless of whether the data is at an appropriate scale local to their system such as RocksDB, at a larger scale within a server-side memory store such as Redis, or on an extreme scale within such highly distributed key-value stores as Accumulo, HBase, Cassandra, BigTable, or DynamoDB - each with dramatically different cloud payment and deployment models.
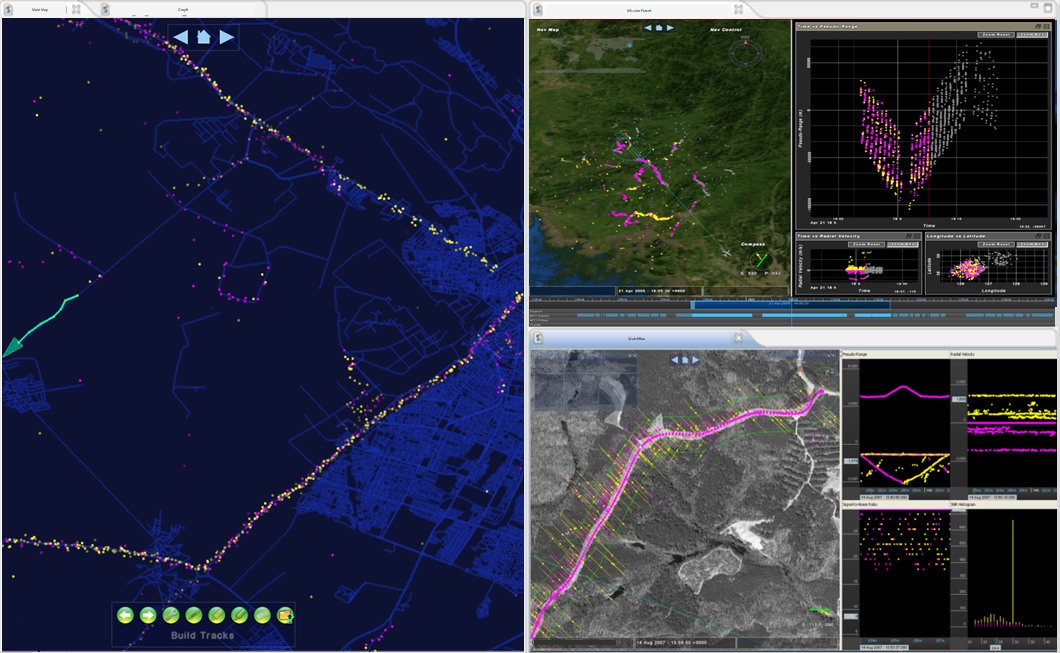
An example analysis tool requiring GeoWave multi-dimensional indexing for map, timeline, and graph search and visualization of massive datasets
GeoWave was released under the Apache 2.0 license in June 2014 and has rapidly gained momentum since. At the project's inception, GeoWave provided spatial and spatio-temporal indexing within Apache Accumulo. Following the project's open source release, generalities formed in support of many data stores with store agnostic APIs and fully general-purpose, multi-dimensional indexing built on top of the core spatial and spatio-temporal indexing. For those following GeoWave development and anxiously awaiting the 1.0 release, you merely need to hold out a few more months - the wait will be well worth it. Time has enabled the development team to be confident in core APIs. It was only after the third or fourth fully supported data store or general purpose multi-dimensional use case that we know for sure we got it right.
So what is the meaning of 1.0 and why has it taken nearly five years in the open source community? For GeoWave, it certainly has not been any indication of lack of stability or production quality. For the customers and the types of large scale systems this software is built to support, there is absolutely no room to sacrifice on these attributes. The GeoWave 1.0 release will bring both a consistent persistence structure and a very clearly-defined and locked down public API. While prior releases had solid APIs, there was not a commitment to lock it down, which we found to be a necessary sacrifice to maximize innovation. Current supported customers with production deployments have reaped the benefits of this evolutionary period, but perhaps the churn has added strain on the open source community. With this upcoming release, the broader community can confidently take full advantage of this innovation.
About the Author
