Eclipse OMR: Building Language Runtimes for the Cloud
The Eclipse OMR project was created at the Eclipse Foundation in March 2016 aiming to build an open community around a set of core technology components for building runtimes for languages like Java, Javascript, Ruby, Python, etc. These components include a platform porting library, a thread library, diagnostic services, monitoring services, a garbage collector (GC). Just recently, in September 2016, a Just in Time (JIT) compiler component was contributed by IBM. All told, this project currently holds about 800,000 lines of C and C++ code derived primarily from the production IBM J9 Java Virtual Machine (JVM). While the code was seeded from the J9 JVM, the project is open to accept new high quality contributions that make improvements to existing components or that add new components.
The genesis of this project was the observation that, despite the ecosystem maturity that should have come from decades of research and development in the building of languages and runtimes, almost no currently popular language runtimes share any common componentry. That's been true for a long time, but more recent pressure points have been the creation of widely available cloud computing platforms and the trend towards microservice rather than monolithic architectures. Cloud platforms have made it easier than ever before to deploy applications written in whatever language works best for the task at hand, while microservice architecture principles encourage the development of decoupled services that do not depend on or encourage monolithic effort funnelled into a single language runtime. The language polyglot is here, it's exciting, and it's only getting better as language communities continue to grow and flourish, but the fact that none of the language runtimes in popular use share any implementation technology slows down progress towards better and more capable cloud platforms: the incredible efforts made by the diverse community of language runtime developers around the world are mostly directed into particular communities and then repeated as warranted.

Figure 1: No shared technology means improvements are expensive to share across languages
For example, implementing or extending support for hardware features like SIMD, GPU, FPGA, RDMA, transactional memory, other forms of hardware acceleration, etc. can be a lot of work, and currently it must be done repeatedly in every language runtime to provide even the most basic support for these kinds of features. That support mostly surfaces as a library with relatively loose coupling to the language which puts most of the effort to leverage these features on developers. Wouldn't be nice if hardware platform providers could implement "always there" support once without so much bespoke work per language and where community investment in automatic exploitation of these features, such as SIMD instructions or transactional memory, could surface in multiple runtimes without the effort or time required for complete reimplementation?
How Was Eclipse OMR Created?
When the IBM Runtime Technologies team initiated the Eclipse OMR project, our goal was to take the core technology that IBM has invested in for decades and divide it into three pieces that would enable the hundreds of developer years invested in this technology to be at least partially reused: 1) a set of core technology components having no particular language semantics, 2) a set of components that are so tied to Java semantics that it does not make sense to share them with other languages, and 3) a *glue layer* that configures and integrates with the core technology components so that they work in the context of the language runtime.
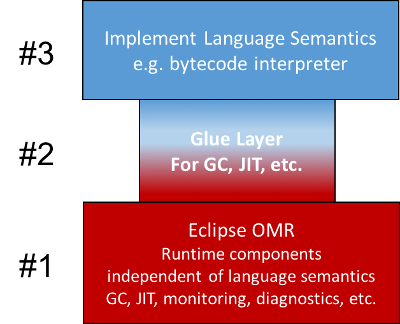
Figure 2: Language runtimes in three conceptual pieces
We formed the open source Eclipse OMR project around the first piece (the bottom piece in the diagram), while the second and third pieces would continue to be used in conjunction with Eclipse OMR to build the J9 Java Virtual Machine which, as announced at Java One 2016, will also be open sourced.
The glue layer consists of queries and definitions that connect the language runtime to the Eclipse OMR components. For example, one GC related query in the glue layer answers the question "how large is this object in memory?". Others would be "please iterate over the root set of pointers and call this callback function on each one", or "here is an object, please iterate over the other objects it points at and call this callback function on each one". "object" is just a name for a block of memory. These queries are just functions to be implemented by your glue layer:

Figure 3: Examples of glue layer queries
For another example, one requirement to integrate with the OMR compiler component is to implement code that can translate language bytecodes into the intermediate language (IL) used by the OMR compiler. We call this function an *IL generator*. We are also working on a simpler way to create Il Generators using a library called JitBuilder.
Integrating OMR with a Runtime
Our goal is that most of the work required from the developers for a particular language runtime should fall into the second and third pieces in the figure above, where the knowledge of the language semantics is most important. Of course, understanding how to express the language semantics in the glue layer requires some understanding the OMR components, but the goal is to keep language designers working primarily in code that is focused on the language without being forced to (re)implement the core runtime technology. The Eclipse OMR project is about sharing the parts that make sense to share and trying to make it easy to integrate the shared parts with the parts that aren't shared.
We call this integration model "clone; clone; make": first you clone your repository (containing your runtime and your language glue implementation), then you clone the OMR repository, and you can build the result using your own "make". Obviously there's work to do to make this integration so straight-forward, but at Eclipse OMR, we're working to make it as easy as possible to integrate OMR with the runtime. We want to make it easy both for language runtimes to get started using OMR but also for them to continue to take advantage of improvements made in OMR and to encourage people to push the code they need to write into OMR when that code could be reused by other language ecosystems.
IBM, for example, accepts changes from the Eclipse OMR project at GitHub on an hourly basis to produce builds and run tests on all the platforms IBM cares about. Those builds are integrated more than once daily into the development version of the J9 Java VM by simply cloning the current repository into a subdirectory of the JVM. That's all IBM does to integrate Eclipse OMR into the development version of the J9 JVM. If you want to test drive it, an early (internal) snapshot of the Eclipsen OMR project code is also used in the IBM SDK, Java Technology Version, Version 8 release, available for download and as a Docker image.
This simple approach to integration doesn't only work for the language runtime Eclipse OMR was originally created from, though. We have also applied it in several prototype implementations we have done with CRuby, SOM++, and CPython runtimes.
With that simple integration process, we migrated several key capabilities from the J9 JVM into the community Ruby, and SOM++, and Python runtimes by leveraging the common implementation layer provided by Eclipse OMR. The point isn't just to demonstrate that IBM could use their own tools and technology in other runtimes, but rather to evaluate the value and effectiveness of the single point of investment strategy. Without implementing much code on the runtime side and without changing the tools at all, we could do live method profile, heap monitoring, introduce enterprise caliber garbage collection and implement a simple Just In Time compiler for all three languages. These runtime ports have all been or will be donated into the open (with flexible licensing) so people can look at it, try it out, and provide feedback on what works well and what doesn't.
Wrap Up
IBM runtime developers are working directly in the Eclipse OMR project and will continue to do so as they work to create their next greatest production runtimes. IBM maintains the OMR parts of their runtime via the Eclipse OMR project. That's just how IBM has decided to build its runtimes from now on: fully in the open.
The Eclipse OMR project is currently made up of a relatively small number of committers along with a larger number of developers actively working in the project. It is our fervant hope that runtime developers of all kinds, from career runtime writers to academics to hobbyists, will come join us. We are a relatively new project still in Incubation status at the Eclipse Foundation, and still getting used to operating in the open. We're not perfect yet, but we're always trying to improve. We welcome anyone to come get involved in whatever way interests you, and if there's something we can do to help you get started, please open an issue or write in to our mailing list.
Come check out the project and roll up your sleeves with us! I look forward to seeing you there!
About the Authors
