Eclipse Jetty and HTTP/2 Optimization
What is Eclipse Jetty?
The Eclipse Jetty project has been a member of the Eclipse Runtime group for many years, with close to two hundred published releases. Jetty came to the Eclipse Foundation in 2009 with fourteen years as an open source project under its belt. Originally created as an issue tracking system for entry into a competition by Sun Microsystems, Jetty won with the most interesting http engine portion being teased out into its own open source project. Enter the servlet-api and we have the origin of the one of the most popular software components in use around the world today. We came to Eclipse seeking a best of breed software foundation that would enhance and promote the clean intellectual property foundation of the project and have been well pleased with this aspect.
Earlier this year the Jetty project migrated its canonical source and issue tracking repositories to GitHub. Both the amount and quality of user contributions have improved dramatically. Coupled with the migration of the user documentation into asciidoc and inclusion in the canonical repository, we could not be happier with how it is positioned. We see new patches and improvements on a weekly basis and attribute it to largely to the innovative environment and platform that Github has created. The dedication that the Eclipse Foundation has shown in integrating with the Github platform is a testament to their commitment to the open-source community.
Getting Started with Jetty
If you have never used Jetty before, welcome! The Eclipse Jetty project is Java-based, providing an HTTP server, HTTP client, and javax.servlet container. The latest stable releases can be found on the Eclipse Jetty project download page. Jetty can be run as either a traditional distribution or as embedded Java.
Running Jetty from the distribution is almost as simple as downloading it. Simply extract the Jetty download package to a directory of your choice and run the following from a terminal or console:
> java -jar/start.jar
Or, if you prefer to embed Jetty as part of your existing Java code, you can implement a server in your existing Java code like this:
package org.eclipse.jetty.embedded;
import org.eclipse.jetty.server.Server;
/**
* The simplest possible Jetty server.
*/
public class SimplestServer
{
public static void main( String[] args ) throws Exception
{
Server server = new Server(8080);
server.start();
server.dumpStdErr();
server.join();
}
}
Regardless of which example you chose to start Jetty, once you do, you can navigate to http://localhost:8080/ and see that Jetty is running. Congratulations! This is only the tip of the iceberg that is Jetty. More information, including a complete Getting Started guide, can be found in the official Eclipse Jetty documentation.
Jetty 9.4 and HTTP/2
At the twenty-one year mark the Jetty project will be proud to release Jetty 9.4, a minor version release that brings with it a host of improvements. Figuring greatly into this release is the completely refactored Session Management system which has come about from our close collaboration with Google Cloud Platform on both App Engine Standard and App Engine Flexible environments. Improvements to Websockets include support for java.websocket 1.1 features as well as the often asked for proxy support for the Jetty websocket client. In keeping with logging being the single most complex, refactored, and iterated upon foundation within the Java ecosystem, we have also added out of box module integrations with many of the most popular logging frameworks in use today.
In addition to these enhancements, careful attention has been given to HTTP/2 with improved flow control, high throughput, low resource graceful degradation and improved mechanical sympathy. Much effort has gone into Jetty 9.4 to avoid thread starvation when using Jetty's Eat-What-You-Kill scheduling strategy.
Jetty has several instances of a computing pattern called ProduceConsume, where a task is run that produces other tasks that need to be consumed. An example of a Producer is the HTTP/1.1 Connection, where the Producer task looks for IO activity on any connection. Each IO event detected is a Consumer task which will read the handle the IO event (typically a HTTP request). In Java NIO terms, the Producer in this example is running the NIO Selector and the Consumers are handling the HTTP protocol and the applications Servlets. Note that the split between Producing and Consuming can be rather arbitrary and we have tried to have the HTTP protocol as part of the Producer, but as we have previously blogged, that split has poor mechanical sympathy. So the key abstract about the Producer Consumer pattern for Jetty is that we use it when the tasks produced can be executed in any order or in parallel: HTTP requests from different connections or HTTP/2 frames from different streams.
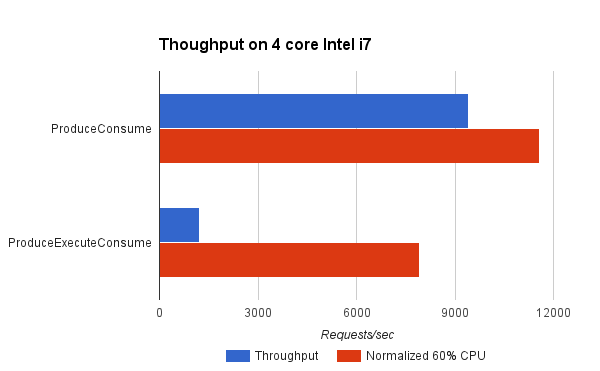
It can be seen that the ProduceConsume strategy achieves almost 8 times the throughput of a more traditional ProduceExecuteConsume strategy. However in doing so, the ProduceExecuteConsume strategy is using a lot less CPU (probably because it is idle during the dispatch delays). Yet even when the throughput is normalised to what might be achieved if 60% of the available CPU was used, then this strategy reduces throughput by 30%! This is most probably due to the processing inefficiencies of cold caches and contention between tasks in the ProduceExecuteConsume strategy.
Eat What You Kill
Mechanical Sympathy not only affects where the split is between producing and consuming, but also how the Producer task and Consumer tasks should be executed (typically by a thread pool) and such considerations can have a dramatic effect on server performance. For example, if one thread produced a task then it is likely that the CPU's cache is now hot with all the data relating to that task, and so it is best that the same CPU consumes that task using the hot cache. This could be achieved with complex core locking mechanism, but it is far more straight-forward to consume the task using the same thread.
Jetty has an ExecutionStrategy called ExecuteProduceConsume, nicknamed Eat-What-You-Kill (EWYK), that has excellent mechanical sympathy properties. We have previously explained this strategy in detail, but in summary it follows the hunters ethic that one should only kill (produce) something that you intend to eat (consume). This strategy allows a thread to only run the producing task if it is immediately able to run any consumer task that is produced (using the hot CPU cache). In order to allow other consumer task to run in parallel, another thread (if available) is dispatched to do more producing and consuming.
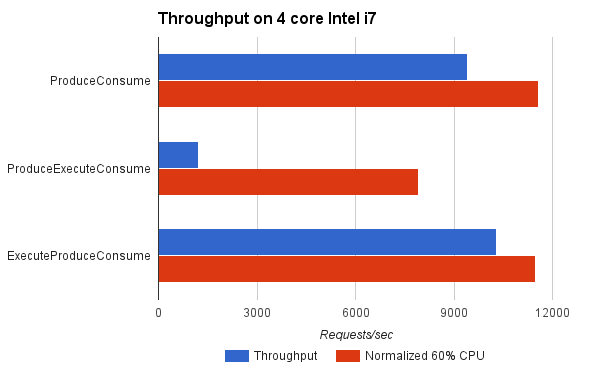
For the benchmark, ExecuteProduceConsume achieved better throughput than ProduceConsume because it was able to use more CPU cores when appropriate. When normalised for CPU load, it achieved near identical results to ProduceConsume, which is to be expected since both consume tasks with hot caches and ExecuteProduceConsume only incurs in dispatch costs when they are productive.
Thread Starvation
EWYK is an excellent execution strategy that has given Jetty significant better throughput and reduced latency. That said, it is susceptible to thread starvation when it bites off more than it can chew.
The issue is that EWYK works by using the same thread that produced a task to immediately consume the task and it is possible (even likely) that the consumer task will block as it is often calling application code which may do blocking IO or which is set to wait for some other event. To ensure this does not block the entire server, EWYK will dispatch another task to the thread pool that will do more producing.
The problem is that if the thread pool is empty (because all the threads are in blocking application code) then the last non-blocked producing thread may produce a task which it then calls and also blocks. A task to do more producing will have been dispatched to the thread pool, but as it was generated from the last available thread, the producing task will be waiting in the job queue for an available thread. All the threads are blocking and it may be that they are all blocking on IO operations that will only be unblocked if some data is read/written. Unless something calls the NIO Selector, the read/write will not been seen. Since the Selector is called by the Producer task, and that is waiting in the queue, and the queue is stalled because of all the threads blocked waiting for the selector the server is now dead locked by thread starvation!
Always two there are!
Jetty's clever solution to this problem is to not only run our EWYK execution strategy, but to also run the alternative ProduceExecuteConsume strategy, where one thread does all the producing and always dispatches any produced tasks to the thread pool. Because this is not mechanically sympathetic, we run the producer task at low priority. This effectively reserves one thread from the thread pool to always be a producer, but because it is low priority it will seldom run unless the server is idle - or completely stalled due to thread starvation. This means that Jetty always has a thread available to Produce, thus there is always a thread available to run the NIO Selector and any IO events that will unblock any threads will be detected. This needs one more trick to work - the producing task must be able to tell if a detected IO task is non-blocking (i.e. a wakeup of a blocked read or write), in which case it executes it itself rather than submitting the task to any execution strategy. Jetty uses the InvocationType interface to tag such tasks and thus avoid thread starvation.
This is a great solution when a thread can be dedicated to always Producing (e.g. NIO Selecting). However Jetty has other Producer-Consumer patterns that cannot be threadful. HTTP/2 Connections are consumers of IO Events, but are themselves producers of parsed HTTP/2 frames which may be handled in parallel due to the multiplexed nature of HTTP/2. So each HTTP/2 connection is itself a Produce-Consume pattern, but we cannot allocate a Producer thread to each connection as a server may have many tens of thousands connections!
Yet, to avoid thread starvation, we must also always call the Producer task for HTTP/2. We do as it may parse HTTP/2 flow control frames that are necessary to unblock the IO being done by applications threads that are blocked and holding all the available threads from the pool.
Even if there is a thread reserved as the Producer/Selector by a connector, it may detect IO on a HTTP/2 connection and use the last thread from the thread pool to Consume that IO. If it produces a HTTP/2 frame and EWYK strategy is used, then the last thread may Consume that frame and it too may block in application code. So even if the reserved thread detects more IO, there are no more available threads to consume them!
So the solution in HTTP/2 is similar to the approach with the Connector. Each HTTP/2 connection has two executions strategies - EWYK, which is used when the calling thread (the Connector's consumer) is allowed to block, and the traditional ProduceExecuteConsume strategy, which is used when the calling thread is not allowed to block. The HTTP/2 Connection then advertises itself as an InvocationType of EITHER to the Connector. If the Connector is running normally a EWYK strategy will be used and the HTTP/2 Connection will do the same. However, if the Connector is running the low priority ProduceExecutionConsume strategy, it invokes the HTTP/2 connection as non-blocking. This tells the HTTP/2 Connection that when it is acting as a Consumer of the Connectors task, it must not block - so it uses its own ProduceExecuteConsume strategy, as it knows the Production will parse the HTTP/2 frame and not perform the Consume task itself (which may block).
The final part is that the HTTP/2 frame Producer can look at the frames produced. If they are not frames that will block when handled (i.e. Flow Control) they are handled by the Producer and not submitted to any strategy to be Consumed. Thus, even if the Server is on it's last thread, Flow Control frames will be detected, parsed and handled - unblocking other threads and avoiding starvation!
Looking Ahead
We anticipate Jetty 9.4 to be released in late 2016, and release candidates have already started being distributed. Further out, Jetty 10 is scheduled to be released towards the end of 2017. Jetty 10 will introduce support for both Java 9 and Servlet 4.0, both of which are likely to release in the next year. It remains to be seen how we will incorporate new features from these into the existing release branches of Jetty. For example, a Jetty 9.5 may be in the cards for Java 9 Jigsaw support, retaining the Java 8 minimum version requirement but supporting the newer features.
We welcome the community to provide feedback and enhancement requests on the GitHub project. For those interested in professional support or development, please contact Webtide, the primary committers behind the Jetty project.
About the Authors

