GeoWave — Making Sense of Massive Geospatial Datasets

GeoWave is a software library aimed at connecting geospatial software with distributed computing frameworks. GeoWave leverages the scalability of a distributed key-value store for effective storage, retrieval, and analysis of massive geospatial datasets. While the core toolkit is generally applicable to multi-dimensional use cases, GeoWave has focused on tailored extensions to support spatial types and operators, with or without temporal timestamps or time ranges. Additionally, it provides advanced features to leverage a distributed backend for visualization or analysis. The software is intended to be easily pluggable into any sorted key-value store, and its modular design is intended to enable feature extension into various geospatial toolkits.
GeoWave was developed at the U.S. National Geospatial-Intelligence Agency (NGA) in collaboration with RadiantBlue Technologies and Booz Allen Hamilton. The NGA released GeoWave under the Apache 2.0 License on June 9, 2014 with the hope to make it possible for other organizations to benefit from the agency’s development efforts and to reap benefits in innovation, creativity, and the power of a far-reaching community of developers who approach problems from different perspectives. Since then the project has engaged with the Eclipse Foundation to join its LocationTech working group to benefit from a broader community. Indeed, there has been increased interest in GeoWave and its close cousin, GeoMesa, for performing spatio-temporal queries on massive data stores. Open feedback from the community is critical to improving the capability. GeoWave hopes this transition will accelerate the ability of the open source geospatial community to leverage distributed computation and storage. It is often difficult to interact with the growing massive quantity of geospatial data using existing geospatial toolkits. Providing the capability to keep up with this growth is key to allowing the geospatial community to leverage the latest advancements in distributed computing.
From its inception, GeoWave utilizes Apache Accumulo to store spatio-temporal content and extends GeoServer to deliver that content through Open Geospatial Consortium (OGC) standard services to any compliant client. Hadoop (YARN) can be utilized to further analyze the content with common spatial algorithms available in both MapReduce and Apache Spark. Kernel density estimation, density-based clustering (DBSCAN), and k-means clustering, are examples of algorithms provided by GeoWave. Developers and data scientists can use these algorithms as building blocks for deeper data analytics. GeoWave supports raster, vector, and point cloud data. There are default indexes for each format along with the ability to create highly specialized indexes for your cluster configuration or dataset. GeoWave has additional extensions to other common geospatial toolkits such as Point Data Abstraction Library (PDAL) and Mapnik, and work is underway to extend GeoWave to other distributed key-value stores and geospatial frameworks.
The foundation of GeoWave uses the Compact Hilbert space filling curve to preserve locality between multi-dimensional objects and the single dimensional sort order imposed by key-value stores. To re-phrase this, the core of GeoWave will keep objects that are logically close in space and time, physically close on a cluster. And explicitly what this means to a user is that distributed spatial and spatio-temporal retrieval and analysis can be effectively accomplished at a massive scale.
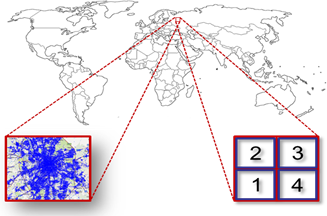
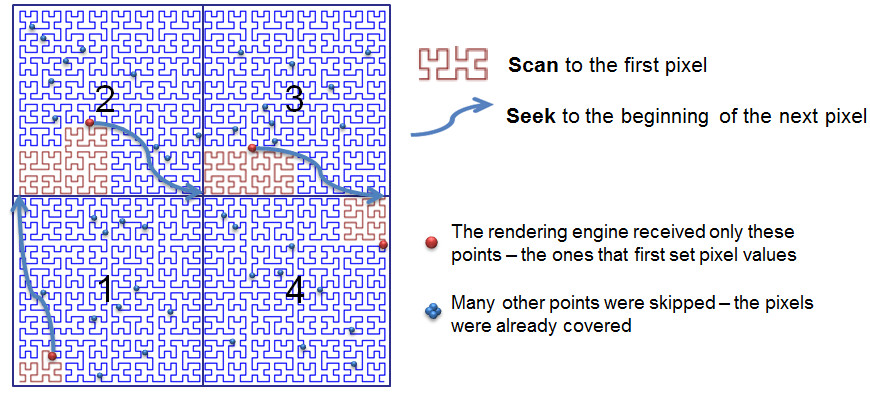
In addition to traditional storage and retrieval functions, GeoWave provides efficient visualization of massive datasets. By providing this capability as a fundamental feature of a distributed geospatial datastore, GeoWave has been able to remove the inherent bottleneck on the rendering engine that results from rapidly retrieving huge datasets from the data store. One key observation of rendering huge amounts of data onto a web map is that the pixels of the map can merely represent a finite amount of data. A transformation between pixel space on a map and the underlying space filling curve that is used to organize the data enables very effective spatial subsampling to be employed at the scope of the underlying storage. Therefore huge quantities of data can appear to be rendered interactively, while truly what you see is what you get from the underlying datastore.
Following pictorially below, if a user is zoomed out over the world with millions or billions of objects within the bounds of a city that represents merely 4 pixels on a map, we can utilize this subsampling to interact with the huge data sets at any scale.
GeoWave is an actively developed project and there is much more work to be done in accomplishing its ambitious goals. The project is driving towards a 1.0 release under LocationTech. For this release, the development team is continuing to engage with other open source projects to find opportunities to complement existing geospatial capabilities. We will be focusing on ease of use and ease of deployment, and will be integrating GeoWave’s full geospatial capabilities on a variety of key-value stores.
About the Authors
