Papyrus 2.0: What, Why and What's Next
Eclipse Papyrus is a Domain Specific Language (DSL) platform based on the most widespread standard modeling language, the Unified Modeling Language (UML). This open source application has two principal objectives. First, it aims to implement the complete UML specification (currently version 2.5), enabling it to be used as the reference implementation for the Object Management Group (OMG)) standard. Second, it intends to provide an open, robust, highly scalable, and highly customizable tool for defining DSLs and corresponding tools. It does so using the UML profile mechanism as well as powerful UI customization facilities.
Papyrus enables users to benefit from the advantages of both well-known interests of using standards-based solutions and the efficiency of domain-specific modeling solutions. Finally, Papyrus also aims to support large-scale industrial projects. It provides an efficient and effective alternative to custom and proprietary DSL tools, without losing the benefits of an international standard. Papyrus’ growing list of industrial supporters is testimony to this. Papyrus can also serve as an experimental platform for researchers constructing proof-of-concept prototypes. Built on top of Eclipse as an open source project, Papyrus is an ideal candidate for this purpose.
The Papyrus project was launched at Eclipse in 2008. It left the incubation stage in 2014, and after 2 years of intensive work, we decided it was time to push a major new version of the tool, Papyrus 2.0. Version 2.0 improvements included new features to make modeling friendlier for users and DSL design features for toolsmiths. We refactored the underlying architecture and improved the methods and tools used to design Papyrus itself in pursuit of our own continuous process improvement.
This article is organized into sections that feature highlights in Papyrus 2.0 for our three primary user groups: modelers, toolsmiths and designers. We’ll conclude the article with some hints about the future of Papyrus. And, if you have not yet started using Papyrus and you do want to (really, you should indeed ;-), the penultimate section provides the required information to make the step.
The User's Corner
A New Welcome Page
To facilitate discovery and review of models, Papyrus 2.0 now has a welcome page for each Papyrus editor. This page will be displayed each time no specific diagram or table is displayed and it can be triggered easily at any time in the tool. As usual in Papyrus, it is fully customizable depending on your needs. In fact, it is possible to move or remove existing components, and to add new components dedicated to your own needs or concerns.
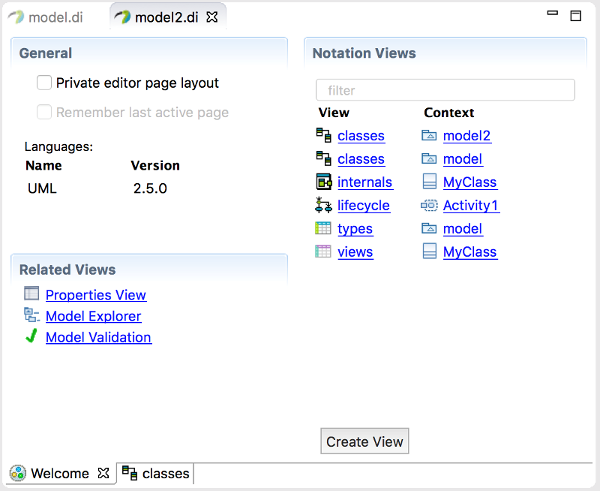
Figure 1 - Papyrus UI snapshot the new welcome page
Easing Navigation Within Models
Modern industrial systems are without a doubt increasing in complexity. The models of such systems reflect this in both the number of elements as well as the number of possible representations, (e.g. a UML semantic element or a view in a diagram). Therefore efficient navigation between related elements in the model, and their representations, is crucial to increased productivity and a better user experience. In Papyrus, we decided on a unified navigation system. When the user alt-hovers over an element in a diagram or the model explorer, a navigation menu appears.
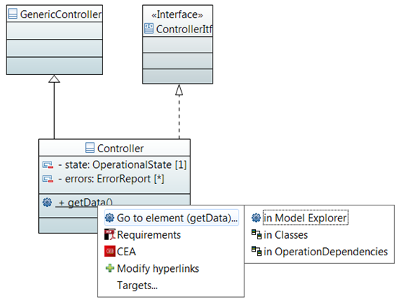
Figure 2 – Papyrus UI snapshot illustrating the view navigation feature
This menu is shown in Figure 2. The menu shows three kinds of items:
- The hovered over element(s): the user can choose to navigate to views of the element in other diagrams, or to show the element in the model explorer.
- Hyperlinks and hyperlinks creation button: the user can create hyperlinks for a particular view of an element in a diagram. A hyperlink can target either a diagram, another view in a diagram, a local document, or a website.
- Relationship navigation buttons: the navigation menu offers the user the ability to navigate to views of elements related to the hovered over element. Some examples of navigation to related elements include the parents of a class, the classes an operation depends on, the behaviors of a classifier, and the diagrams contained by a package.
We also provide fast navigation by double clicking on the view of an element in a diagram. If the user hasn’t created default hyperlinks for the view, hyperlinks are automatically proposed to the user. For example, double clicking on a class goes directly to its inner class diagram if it exists. The automatic hyperlinks and the relationship-based navigation proposed in the navigation menu are referred to in Papyrus as navigation strategies.
The navigation system in Papyrus is highly customizable through the preferences page of Papyrus. The user can customize their navigation experience according to their development method and habits. If unfortunately, no navigation strategy suits the user, a customized navigation strategy through the Papyrus navigation API can be implemented.
References View
Papyrus 2.0 offers a new view dedicated to highlighting the incoming and outgoing model references to the currently selected element. These references can be, for example, the various representations of the semantic element selected or all properties typed by the current selected type, etc. This view is then useful for navigating through the model and understanding the role of a given element. This view is also tightly integrated with the updated navigation framework in the upcoming version.
About tabular editors
Several new features and refactorings have been done on the table framework. The paste function has been refactored to manage the reimport of csv files. It allows the user to easily update the table contents. The cell editor declaration has been refactored to be more configurable by the user for a given column. NatTable 1.4 provides us CSS capabilities. Papyrus Table integrates this new feature. We replaced the EPF Richtext editor in Papyrus with the ckeditor which is now available in the Eclipse Nebula project. Tables embed it to enable the editing of the body of the UML Comment (Figure 3).

Figure 3 - Papyrus snapshot showing the rich text editing facilities of text-type cells within table-based editors
New columns are now available in the table. They provide the ability to write basic formulas similar to those in Spreadsheet editors. The user can now fill cells easily and quickly with a simple mouse selection and a move function like in well-known spreadsheet editors (Figure 4).

Figure 4 - Snapshot illustrating the formula support facility of Papyrus table editors
This action allows users to fill by copy, increment or decrement the initially selected cell value (Figure 5).
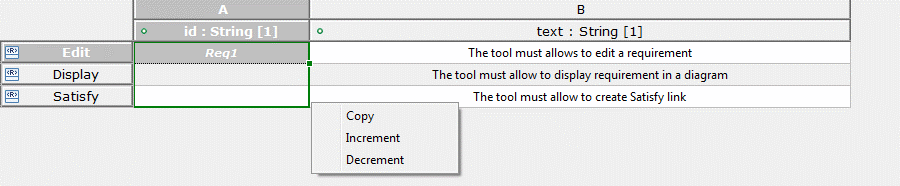
Figure 5 - Papyrus UI snapshot illustrating the automatic filling feature of table editors
Finally, the display of the table has been improved by integrating the validation markers provided by the Model Explorer and the Diagrams.
About Search
Being able to search and find specific elements is a basic feature of any modeler. Through the mechanism of profiles, UML is customizable for different domains.
A search query in a UML model must therefore be expressive enough for extensions of the base modeling language, unknown before runtime, contrary to a search queries in models of bounded domain-specific modeling languages.
In addition, models can be potentially large in size, comparable to databases in terms of number of elements. Therefore, the search query must not only be expressive enough, but search time must also be performant enough for a good user experience.
In Papyrus we offer a search menu with several modes: simple, advanced, or OCL-based. In the simple mode, the user can search model elements by name. In OCL mode, the search may run an OCL query on the model. Figure 6 shows the search menu in advanced mode. In the advanced mode, the user can choose filterable UML types and stereotypes, as well as their attributes, to consider in a search query. The stereotype options are particularly rich: the user may filter out unapplied stereotypes, choose stereotypes based on applied profiles or enforce if all stereotypes must be applied.
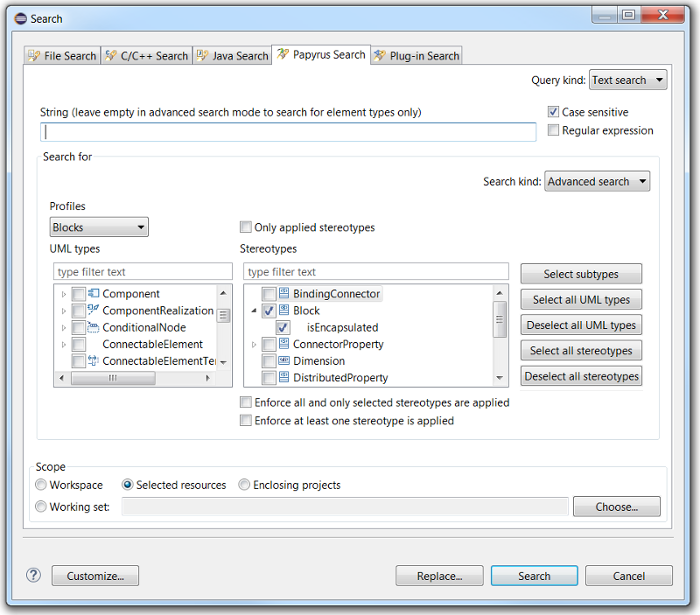
Figure 6 - Papyrus UI snapshot of the advanced search feature
We have also improved the performance of the search operation. Searching in a model of more than 10,000 elements is possible without freezing the UI!
Improved Viewpoints Usability
As defined in the ISO standard 42010, viewpoint is a means to offer specialized concepts of a language and their related UI customization for a given set of concerns for a given stakeholder. Papyrus 2.0 improved its support to viewpoint definition and usage. As shown in Figure 7, users can now more easily switch between available viewpoints. Depending on the active viewpoints, domain specific editing capabilities are also activated.
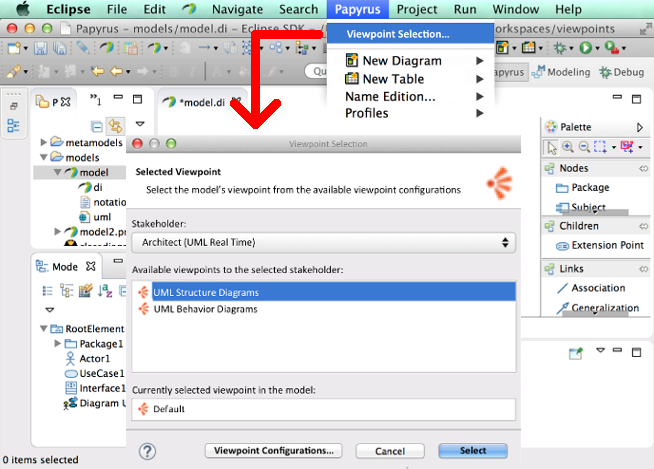
Figure 7 – Papyrus UI snapshot for selecting the active viewpoint
Around Collaborative Modeling
In the past year, team support for Papyrus has been significantly strengthened. Papyrus offers two options for enabling collaborative modeling.
In the first option, using Papyrus-specific enhancements of EMF Compare and EGit, users may conveniently manage the evolution of their Papyrus models in Git repositories (Figure 8). EMFCompare is registered with EGit for handling Papyrus models and applies a model-level comparison, conflict detection and merge, instead of performing the default line-based text merge of Git. The Papyrus-enhanced model comparison not only allows the user to compare diagrams and their underlying models, but also includes support for UML Profiles and, thereby, UML-based domain-specific modeling languages, such as SysML or Papyrus-RT. Moreover, the user interfaces for viewing differences among model versions are now more tightly integrated with the look and feel of Papyrus models. For instance, changes on composite modeling concepts are grouped semantically to achieve an improved user experience.
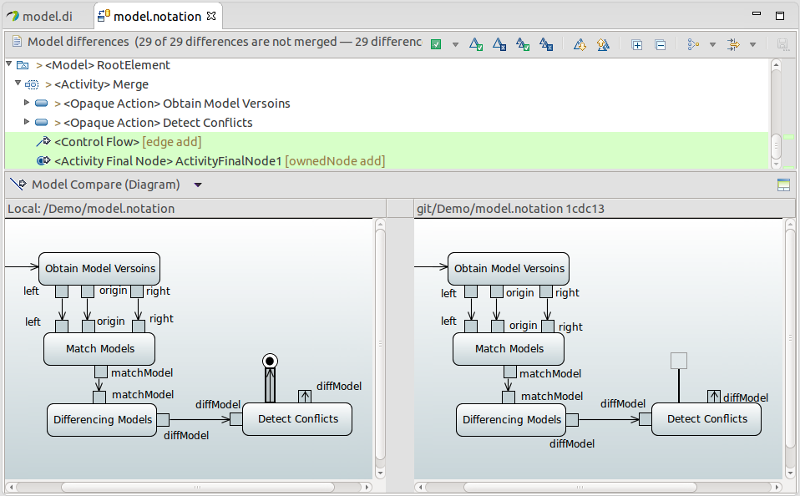
Figure 8 - UI snapshot of the collaborative modeling feature with Papyrus and EGit
In the second option, Papyrus provides an integration to CDO (Connected Data Objects) in order to support scalable, database storage of models for collaborative work. CDO achieves scalability by implementing an efficient persistence strategy relying on databases. Collaborative work is achieved through transactional access (with save points and rollback), a user management system, the ability to lock resource and the classical operations on repositories (clone/branch/merge/checkout). The Papyrus integration of CDO allows teams to work on the same model from multiple clients while keeping the Papyrus "look and feel". A model opened on a checkout from a CDO repository can be viewed by the same Papyrus model explorer view and the same Papyrus model editors as would a local model.
About SysML Support
The SysML Version 1.4 specification was released by the OMG (Object Management Group) in September 2015. Papyrus has tackled the challenge to implement this new standard for Papyrus 1.1. The first step was to release version 0.8.0 at the end of 2015 where users could find SysML relevant diagrams: block definition, parametric, requirement and internal block diagrams. The next release of SysML 1.4 will be based on Papyrus 2.0. It will make official, the deprecation of SysML 1.1 in favor of SysML 1.4. The new release will highlight several new features including: frame, inner port and part tree exploration. The team will also provide a migration tool to go from 1.1 to 1.4.
The Toolsmiths Corner
For toolsmiths we have two main sections. The first is on customization of the Papyrus tool UI, while the second is focused on the new support provided by Papyrus 2.0 to define domain specific modeling languages (DSML).
About the UI Customization
Library and Simplified User Interface Examples
Papyrus provides many native customization capabilities to provide a pure DSML experience on top of UML2. Papyrus 2.0 provides reproducible examples for toolsmiths who are developing a customized version of Papyrus. The standard Library sample from EMF has been adapted to the UML world, thanks to the UML2 profile mechanism. This example is easily installed and run in a Papyrus environment with a few clicks. Toolsmiths will see how the customizations can be created through Papyrus extensions.
An example of Capability configuration is also available to show how a simplified UI can be provided to users that are overwhelmed by a full set of Eclipse and Papyrus menus and toolbars.
Customization Editors for Palette, New Child in Model Explorer and Modeling Assistants
Creation tools like diagram palettes and new child menus in model explorer have been customizable in the last several versions of Papyrus. However, these frameworks were working separately, and the same behavior definition needed to be defined in several places. Thanks to central edition framework updates and new customization-specific editors, toolsmiths have access to user friendly wizards for defining new creation actions.
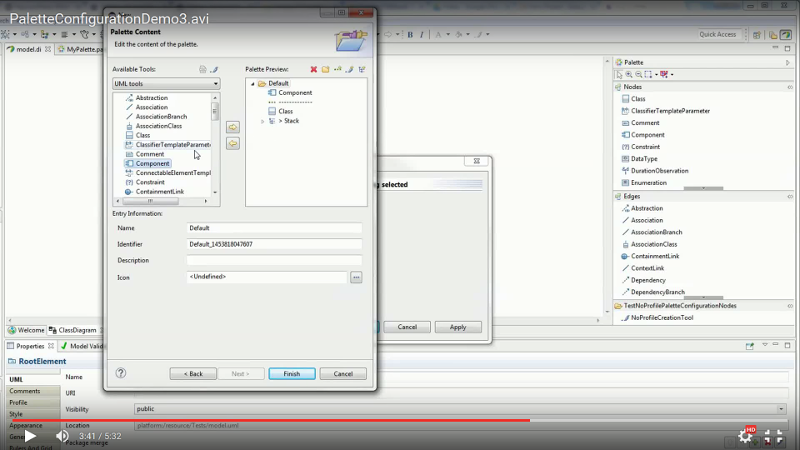
Figure 9 - Papyrus UI snapshot of the tool wizard enabling toolsmiths to define diagram customized palettes
Improved Viewpoints Framework
The viewpoint framework has been improved to allow toolsmiths to scope the activation of domain specific editing capabilities specific to each viewpoint.
About DSML design
This section lists the most important new or improved features related to the design aspects of a domain specific modeling language using Papyrus.
Improve ElementTypesConfiguration framework
To allow toolsmiths to define custom editing of the semantic model for their domain specific languages, the ElementTypesConfiguration framework has been extended and refined. To ease the scoping of the activation of ElementTypes to a specific domain, ElementTypesConfigurations are registered by domain (context). The execution of Advices can be ordered. ElementTypes can be reactive to profile and stereotype editing requests. ElementTypesConfiguration framework has been improved to make its built-in extension mechanism more user-friendly.
About the definition of table configurations
A new wizard for table configuration has been delivered in Papyrus 2.0. It provides an easier way for the user to create new table configurations or to edit an existing one in five clear steps.
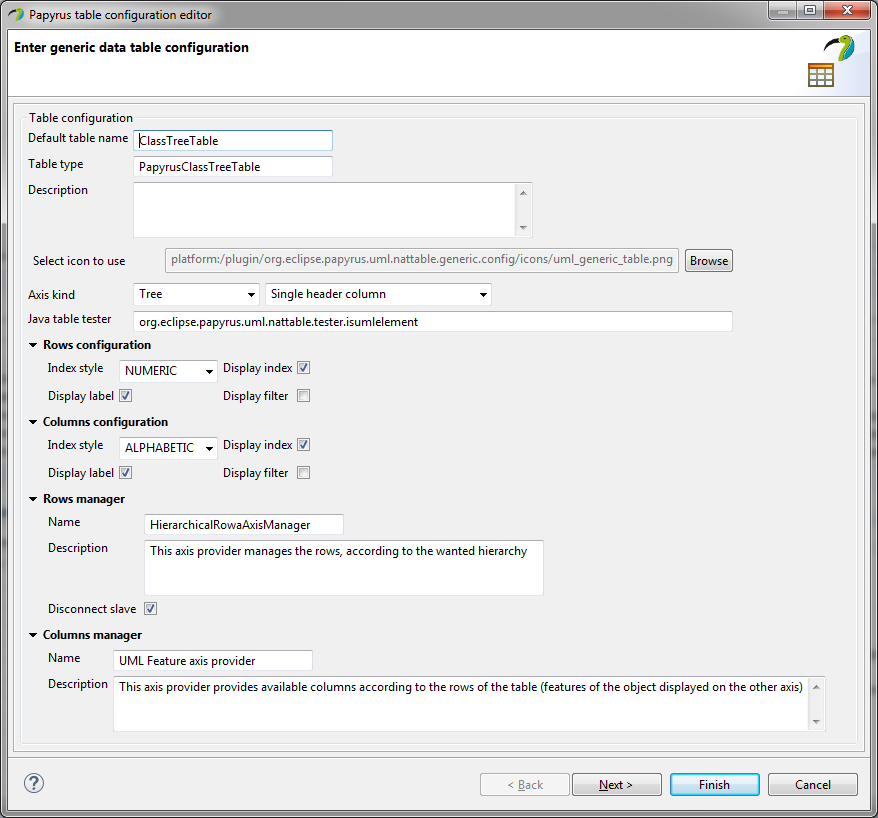
Figure 10 - Snapshot of the Papyrus Specific Table Configurator
Unified and Meaningful Notation Models
Identifiers of diagrammatic representations are now shared among diagrams allowing toolsmiths to reuse them instead of redefining them in their domain specific diagrams. Also, the identifiers have been migrated to meaningful strings so that APIs provided by Papyrus to manipulate the diagrams programmatically are now much easier to use.
The Committers Corner
A More Modular and Scalable Architecture
The main thrust of the API refactoring work has been in rationalizing the dependencies between bundles, in two different dimensions:
- Dependencies on the Eclipse Platform UI (primarily SWT and JFace).
- Examples include core run-time APIs such as the Service Registry and generated models being defined in plug-ins that have a user interface component. These APIs sometimes even directly initiate user interaction.
- Dependencies on other Papyrus bundles in the wrong architectural "component" or "layer".
- Examples include core services relying on UML concepts from the Papyrus UML Layer to find the semantic model in a resource set; and the hyperlink navigation framework providing an implementation for diagram views based on the Papyrus Diagram Layer.
The refactoring generally involved moving APIs (types, packages, and extension points) from bundles where they don’t belong because they force the host bundles to have architecturally invalid dependencies. We moved these APIs to bundles in more appropriate layers or to those dedicated to providing UI contributions to the Eclipse Workbench. Additional goals of this refactoring, outside of architectural correctness, were:
- Enabling the use of Papyrus technology in "headless" scenarios, such as in automation environments, web application back-ends, etc.
- Improving code quality through better testability of the individual Papyrus components.
- Improving the Papyrus build system by making it more modular for faster turnaround of continuous integration builds. This in turn improves developer productivity and transparency of the quality process for end users.
- Paving the way for the adoption of new technologies such as GEF4 by proper isolation of the code that would integrate them.
So, in summary, as far as end users (modelers using the Papyrus workbench) are concerned, these changes do not mean much in the short term, but they help to ensure the long-term viability of the tool and the developer community’s ability to deliver new releases year after year with new features that don’t risk the stability, usability, and flexibility of the software.
Improved Manipulation of Graphical Information
To ease the exploitation of the graphical information associated with the model (the so-called Notation models in terms of the Papyrus terminology), such as model transformations, the identifiers of the diagrammatic representations (VisualIDs) have been unified between diagrams. The same representation in different diagrams such as the Comment shape now shares the same identifier. Also, this identifier is human readable: integers that were used as identifiers have been migrated to meaningful qualified name strings. Thus, APIs provided by Papyrus to manipulate the diagrams programmatically are much easier to use.
Developer Tools for the ElementTypesConfiguration Framework
To facilitate the development of domain specific modeling languages, the ElementTypeConfigurations framework now provides a notifications mechanism that helps to trace the activation and operation of the ElementTypesConfiguration framework. A dedicated developer view uses this notification mechanism to ease debugging by providing the detailed traces produced by the ElementTypesConfigurations framework while editing in a Papyrus editor.
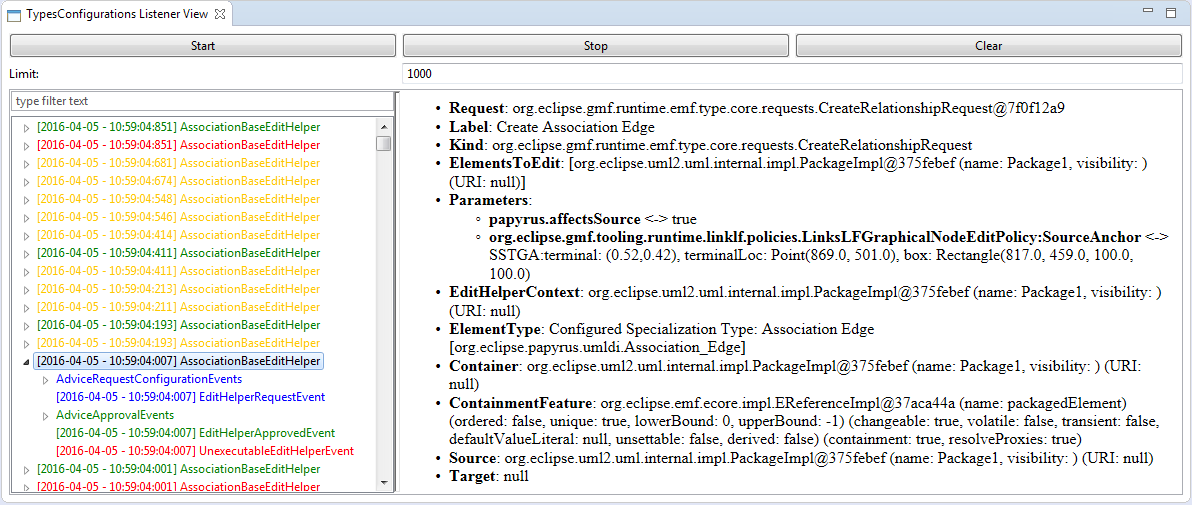
Figure 11 - Developer view for ElementTypesConfigurations framework operation tracing
In addition the "Registered ElementTypes view" has been improved to explore any context and to provide additional details on the registered ElementTypesConfigurations.
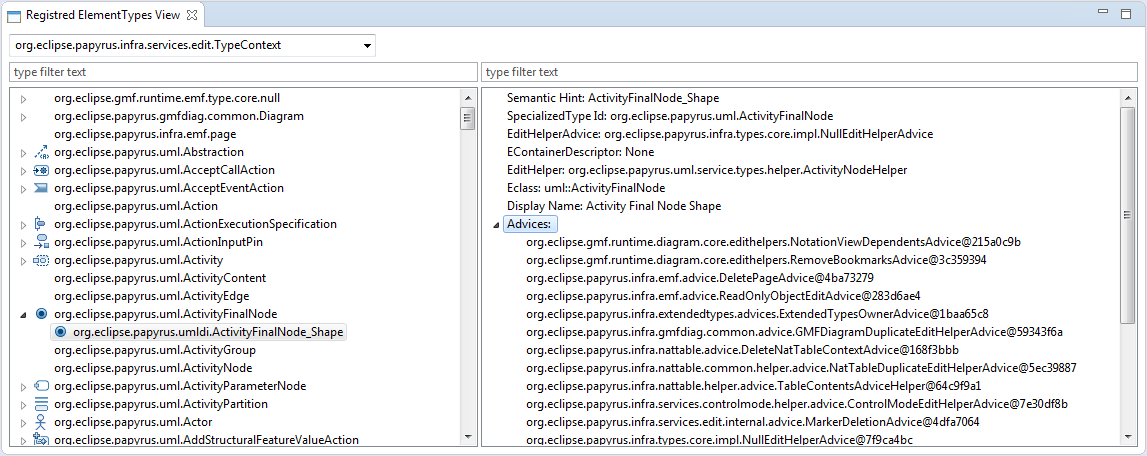
Figure 12 - Developer view to explore the ElementTypes registry
What's next?
Of course, the Papyrus team and its ecosystem will continue our efforts to improve Papyrus by providing new features and improving existing features. This work will continue to follow two major drivers: to provide users what they need to apply efficiently MDE to their domains and projects and to conform to standards.
We are looking forward to the Papyrus Industrial Consortium, which was launched early this year, to become a channel to enable us to collect and organize user needs and define the best solution to meet them. Read the next article to find out more.
Acknowledgment
All following people have contributed to the writing of this article, and I do want to thank all of them warmly: Christian Damus, Philip Langer, Shuai Lee, François Le-Fèvre, Vincent Lorenzo, Benoit Maggi, Florian Noyrit, Remi Schnekenburger, Xavier Zeitoun.
About the Authors
