Developing Domain-Specific Languages with Xtext
Domain-Specific Languages (DSL) have become an ubiquitous tool to provide powerful abstractions for specific use cases. They did not only become mainstream since Martin Fowler has released his latest book on that topic [1] but popular frameworks such as Spring Roo [2], Apache Camel [3], or Grails [4] make heavy use of these specialized little languages that are tailored to a particular purpose. These examples illustrate that there are sweet spots for DSLs in commonly used frameworks. The real power of DSLs is unveiled when they are custom-made for real-world projects, tough. In such narrow environments, DSLs can be used to describe main viewpoints of very specific systems. These often involve legacy infrastructure and proprietary protocols that are not handled by widely applicable frameworks and from-the-shelf solutions.
An important question to consider is whether developing and maintaining a dedicated, focused and inherently specific language is really worth the effort? Isn’t language design something complicated that only parser-gurus can handle? And what about IDE support? Today’s sophisticated programmers demand top-notch editing facilities, so even if we can afford to develop a DSL, can we really achieve effective IDE integration?
Eclipse Xtext is a framework that makes developing DSLs a breeze. It facilitates agile, iterative evolution; and the output is not only the infrastructure to parse the files of your newly created language, but a sophisticated IDE with code highlighting, code completion, and error checking for the new DSL. Xtext is a mature framework used in research and industry by companies such as Oracle, Google, BMW and many more. The community is vibrant with many friendly people willing to help in the forum and there’s even XtextCON, an annual three-day conference where users and developers come together to learn about and discuss the framework.
In his book on DSLs, Martin Fowler motivates the topic with a small example DSL, which he uses to explain different techniques, patterns and approaches for implementing internal as well as external DSLs (see box). In this article you will learn how to implement Fowler’s secret compartment state machine in a couple of minutes using Xtext.
External and Internal DSLs
A domain-specific language can be defined in two ways. One approach is to make use of the syntactic flexibility of a programming language to define an API, where the client code looks like it is written in a completely different language. This is quite hard with rigid languages like Java but some languages like Ruby provide enough syntactic flexibility, such that code can really look like it was written in a language of its own. A second approach is to us an external DSL that is not embedded in another host language but explicitly defined using a parser generator or something similar. DSLs developed with Xtext are all external DSLs. Both approaches have advantages and disadvantages and it is a good idea to know about both. However, most commonly cited disadvantages of external DSLs have been eliminated by Xtext.
The Example
Imagine you are running a company, called "Gothic Security", which specializes in developing security systems for secret compartments. You have many customers and you want to be able to easily define and reconfigure the security systems for your customer’s secret compartments. So you need a concise way to define such security systems: a domain-specific language.
Mrs. Grant’s security system might look like this:
events
doorClosed D1CL
drawerOpened D2OP
lightOn L1ON
doorOpened D1OP
panelClosed PNCL end
resetEvents
doorOpened
end
commands
unlockPanel PNUL
lockPanel PNLK
lockDoor D1LK
unlockDoor D1UL
end
state idle
actions {unlockDoor lockPanel}
doorClosed => active
end
state active
drawerOpened => waitingForLight
lightOn => waitingForDrawer
end
state waitingForLight
lightOn => unlockedPanel
end
state waitingForDrawer
drawerOpened => unlockedPanel
end
state unlockedPanel
actions {unlockPanel lockDoor}
panelClosed => idle
end
To unlock her panel, Mrs. Grant needs to first close the door. Then she opens up a certain drawer and turns on her bed light. This triggers a secret mechanism and the panel gets unlocked. Note the section with resetEvents, which says that if anyone opens the door, the whole system is reset back into idle state. The cryptic codes declared after the events and commands shall illustrate the binding to the target platform. Imagine that the controllers can only understand such cryptic names. This kind of name mapping is a typical pattern when integrating DSLs into target software systems and very similar to a mapping of SQL data types to Java or C# types.
The Grammar Definition
First we have to create a parser that is capable of reading such input-files and instantiating an in-memory model, based on the Eclipse Modeling Framework (EMF) [5], that represents the parsed state machine. Fowler calls these typed objects a semantic model. Common parser generators allow one to describe the syntax of the documents but don’t provide abstractions to describe strongly typed structures for the semantic representation of their content. Xtext’s grammar definition is different. It describes the concrete syntax as well as the mapping to a semantic model in a clean and concise way:
grammar org.eclipse.xtext.example.FowlerDsl with org.eclipse.xtext.common.Terminals
generate fowlerdsl "http://example.xtext.org/FowlerDsl"
Statemachine:
{Statemachine}
'events' (events+=Event)* ‘end'
'resetEvents' (resetEvents+=[Event])* 'end'
'commands' (commands+=Command)* 'end'
(states+=State)*;
Event:
name=ID code=ID;
Command:
name=ID code=ID;
State:
'state' name=ID
('actions' '{' (actions+=[Command])+ '}')?
(transitions+=Transition)*
'end';
Transition:
event=[Event] '=>' state=[State];
Even though you may not be too familiar with grammars in general, you’ll be able to make some sense of it. Without going into a detailed explanation (which can be found in the documentation [6] anyway), there are two especially noteworthy constructs. The assignments describe how the parsed values should be stored in the semantic model and the cross references in square brackets define how the objects should be interlinked. These constructs are unique features of Xtext’s grammar definition language.
Apart from the parser, there are many other aspects that Xtext derives from the grammar. For example, there is infrastructure for linking and scoping as well as for static analysis (validation) based on the semantics of the language. You even get an unparser, which allows you to instantiate or modify semantic models in-memory and write them back as text using the very same syntax as defined in the grammar. Even whitespace and comments are preserved and you can of course define formatting rules.
One of the best things about Xtext is the rich Eclipse integration that is available for every language. Based solely on the aforementioned grammar definition, Xtext provides a fully functional Eclipse editor. It supports all the features that you'd expect from other mature IDEs, such as on-the-fly validation and error indication, syntax coloring, content assist, and code navigation. You can find references to your semantic elements, look them up in a global index, and share concepts across different languages.
Modularity Concepts
As soon as you build a language to develop a fair-sized system, you’ll have to think about modularization. It’s often a good idea to split logically different things into different physical files. After all, developing in a DSL is not different from developing in a general purpose programming language. Xtext supports that out of the box. By means of the scoping and visibility rules of your language, references across file boundaries will be resolved by the framework based on the names of your semantic elements instead of concrete file references. As for many other service implementations in Xtext, this follows the lessons learned from mainstream programming languages. The defaults are quite similar to the namespace concept of C# and Java. Behind the scenes, Xtext uses an index in the IDE to ensure scalability for languages with a large number of artifacts. This index is used for various other features, too. Similar to the “Open Type” dialog Eclipse’s Java tooling provides to find and open Java types anywhere in the workspace, Xtext offers the feature to lookup arbitrary semantic elements in your IDE as well as a global “Find References” capability to identify other objects that refer to a particular element. The index is maintained by an Eclipse builder that automatically picks up any changes in your text files and revalidates the affected files in the background.
The very same information is used to trigger further processing components such as compilers or code generators. They can participate in the build process and generate or update other files such as Java code that is derived from your model files. The Xtext framework provides a dedicated customization hook for that purpose and bundles the Xtend language which is specialized for code generation. The following snippet illustrates a small template that creates an interactive state machine to test the logic of secret compartments:

Some people don’t like code generation, which is mostly because it adds complexity to the development process and makes turnarounds longer. Although Xtext works perfectly well with interpreters, the tight integration with the Eclipse infrastructure as well as build tools such as Maven, Gradle and Ant makes code generation happen transparently in the background. A longer development turnaround time is easily forgotten since it happens instantaneously. But again it’s up to you whether you want to use code generation or an interpreter to process your DSL scripts.
Language-specific Enhancements
Modern IDEs for general purpose programming do a very good job at error detection. This is especially true for statically typed languages, where many mistakes a developer might make, are found as you type. There are type checks to ensure that expressions are compatible and data flow analysis to detect null pointer exceptions. Xtext provides convenient means to define these kinds of validation rules too. A validation rule that ensures that the resetting events are not conflicting with the valid transitions of a state is only a matter of a single line of code. The detected issues will be displayed right in your editor in exactly the same way problems in Java files are reported. Xtext will underline the parts of the file that are erroneous and you get the chance to fix them immediately. You can even go one step further and provide quick fixes for any issue that you detect. Because DSL-specific validation rules are executed as you type, your users get important feedback and guidance as soon as possible. Validation is of course not bound to Eclipse but is also executed when the parser is used from other environments such as the command line.
Another way to guide your users is content assist. The workflow for many developers is often heavily based on smart content proposals, for good reasons. IDEs allow one to write new methods with a couple of keystrokes and they offer suitable proposals at any given point in the source code. Xtext automatically suggests valid proposals based on the lexical structure of the DSL. Also the scoping and linking rules are taken into account to provide suggestions for cross references. Writing code in an Xtext-based language is a real pleasure because of the guidance that users get from the editor. They can even define template proposals to create complete structures with a single keystroke. Template proposals may contain place holders that will be pre-populated by the framework which allows the selection of valid values from drop down lists and the like. These advanced IDE features are based on the fact that the editor is aware of the grammar definition and the currently edited semantic model which allows it to derive a great deal of helpful information.
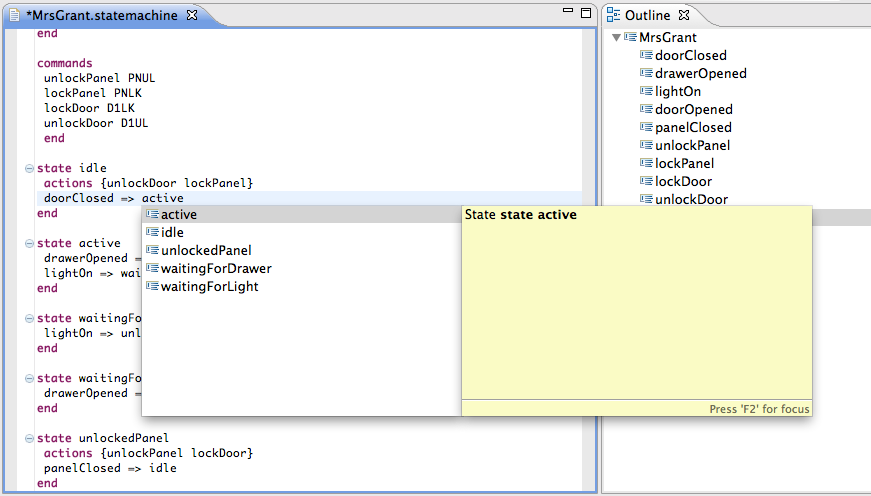
Extensibility
Validation and content assist are just two of many aspects you might want to specifically tailor for your DSL. Actually with Xtext there is no functionality that cannot be extended or replaced by your own implementation because the framework makes extensive use of dependency injection using Google Guice [7]. This allows for easy customization because nothing is hard wired deep down in some internal implementation class. Even though this offers great flexibility, the defaults should not be underestimated. They address the most common use cases and are based on common language design patterns. The less code you’ve written the less you’ll have to maintain and of course you’ll benefit from all the future enhancements made to Xtext itself.
Have fun!
There is so much more we could talk about, such as the possibility to integrate with Java code or the reusable statically typed expression language Xtext provides, which can be embedded at arbitrary places within your DSL. But this would go far beyond what fits into such an article. So we leave you with just one final bit of advice for now:
Go try it out! It’s open-source, well documented and fun to use.
- [*] - Xtext - http://www.xtext.org
- [1] - Martin Fowler - Domain-Specific Languages - Addison Wesley ISBN 978-0321712943
- [2] - Spring Roo - http://www.springsource.org/roo
- [3] - Apache Camel - http://camel.apache.org/
- [4] - Grails - http://www.grails.org/
- [5] - Eclipse Modeling Framework - http://www.eclipse.org/EMF
- [6] - Xtext Documentation - http://www.eclipse.org/Xtext/documentation.html
- [7] - Google Guice - http://code.google.com/p/google-guice/
About the Authors

