Visualizing Big Data with Hadoop and BIRT
According to Wikipedia, Big data is a collection of data sets so large and complex that they are difficult to process using on-hand database management tools or traditional data processing applications. Big data usually includes data sets with sizes beyond the ability of commonly used software tools.
It’s a good thing BIRT is not your traditional data processing application!
Eclipse BIRT was built with data source extensibility in mind. BIRT does this by leveraging the Eclipse Data Tools Project (DTP) and more specifically, the Open Data Access (ODA) framework. This framework allows new data sources, like recent big data sources, to be easily added to BIRT as needed. This post walks through creating a connection to Hadoop in order to visualize the data within BIRT.
Using HQL to query Hadoop data
BIRT provides an out-of-the-box driver that allows access to Hadoop Data through Hive using Hive Query Language (HQL). Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. To retrieve data from Hadoop, you write a query in Hive Query Language (HQL). HQL supports many of the same keywords as SQL, for example SELECT, WHERE, GROUP BY, ORDER BY, JOIN, and UNION.
A Hive query is executed by a series of automatically generated MapReduce jobs. Alternatively, you can use the TRANSFORM statement to specify scripts that translate into MapReduce functions in Hadoop. These scripts can be written in virtually any programming language. For example, the following HQL query specifies the script file mytest.py, written in the Python programming language.
SELECT TRANSFORM (userid, movieid, rating, unixtime) USING 'python mytest.py' AS (userid, movieid, rating, weekday) FROM u_data
Creating an HQL query in BIRT
To create a new query, select Hive Datasource from the New Data Source wizard and enter the connection properties, as shown in the figure below.
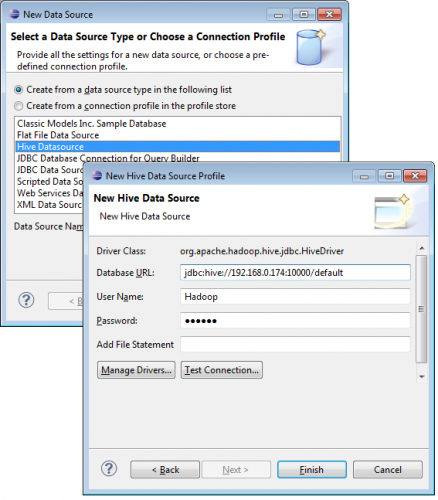
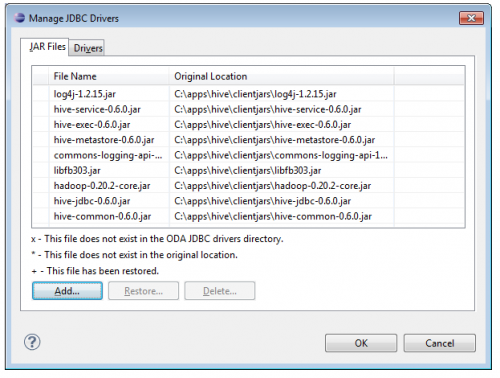
Next, choose Manage Drivers and add the Hive client JAR files. You only need to do this once.
Now, you can create a data set by writing an HQL query. If your query uses TRANSFORM statements that reference script files, use the Add File Statement property to add files to the Hadoop distributed cache. Type a semicolon-separated list of Add File commands. This property can be overridden by the data source or data set, using property binding or script. Type the HQL query in the query text area of the data set editor as shown below.
.jpg)
Complex HQL Subquery Example
.jpg)
Get JSON Object Example
.jpg)
Regular Expression Example
.jpg)
HQL Hints Example
Getting the Important Data to Stand Out
You can create multiple data sets using the same steps above, even joining data sets within BIRT. Once you have your big data connections and queries defined, you can start using the data to define your report within BIRT. At this point, you can simply drag your data sets onto the report canvas and start formatting.
.jpg)
But, being able to store more data brings its own new sets of challenges. The more data collected typically means more data that needs to be analyzed and displayed. This means, the important data really needs to stand out. BIRT supports this with several out-of-the-box features.
Highlighting
With the Highlighting feature in BIRT, you can set up formatting rules that are based on expressions. You can create simple to quite complex expressions in order to highlight the data. Highlighting can be added to grids, tables, columns, rows, data elements, labels, charts, and images.
.jpg)
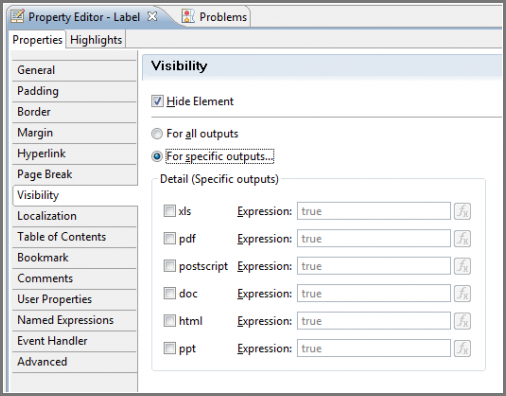
Visibility
The Visibility feature allows you to use expressions to decide which areas of BIRT are visible. This is quite useful for allowing certain groups of people to see only their data but can also be used to hide whole areas based on the data discovered. Visibility can also be applied to grids, tables, columns, rows, data elements, labels, charts, and images, but you can also have seperate visibility rules based on the final output, like PDF, HTML, etc.
Try it Yourself
The Hive/Hadoop data source has been available since BIRT 3.7 and can be downloaded as part of the Eclipse BIRT Designer from eclipse.org/birt or BIRT Exchange.
About the Authors
