Cloud-Native Geospatial technologies: COG, STAC, and the future of GeoTrellis
What is cloud-native geospatial?
Cloud-native geospatial is a description of the production, processes, and systems that are enabled with geospatial technology designed specifically for cloud computing infrastructure.
Geospatial data production is growing exponentially as ground, aerial, and space-based location-aware sensors become cheaper and more ubiquitous. Cloud computing infrastructure led by Amazon Web Services, Google Cloud Platform, Microsoft Azure, and Alibaba Cloud, among others are providing the infrastructure that can handle this load. These services are constantly improving in terms of accessibility, price, and capacity.
However, as has been demonstrated by the development of cloud infrastructure for photos, to fully leverage the volume of the Earth observation data produced and the capacity of the processing power, it will be essential to have an open ecosystem that combines open source tooling, openly licensed libraries of sample imagery for testing, and open standards to facilitate interoperability.
For working with digital photos the innovation ecosystem has been seeded by image libraries, like ImageNet, and several software tools - TensorFlow, Caffe, Keras, and Theano, to name a few - released under open source licenses and paired with new cloud computing infrastructure.
The geospatial Earth observation imagery community is following a similar trajectory, with open imagery catalogs, like SpaceNet, and open source libraries, like Raster Vision. However, geospatial imagery has some unique needs that call for new standards and capabilities, and there has been significant progress in the world of cloud native geospatial technology in the past year. Two noteworthy advances are the emphasis on standards for Cloud Optimized GeoTIFFs (COGs) and spatiotemporal asset catalogs (STAC). A number of individuals and organizations have contributed to this effort, but Chris Holmes, Product Architect at Planet and Technical Fellow at Radiant Earth Foundation, has done a tremendous job of convening the actors and laying the foundation for the collaborative design and development activities that are shaping the widespread adoption of these two standards. This post will provide a high-level overview of COGs and STAC and then describe how GeoTrellis fits into the ecosystem. For a deeper dive into the vision, find upwards of 30 blog posts written by Chris on the subject in the past year.
Cloud Optimized GeoTIFF

A Cloud Optimized GeoTIFF (COG) is similar to a regular GeoTIFF file but with an internal organization that enables more efficient read access to a portion of the image, the workflow most common for accessing imagery stored in a cloud infrastructure. It does this by leveraging the ability of clients issuing HTTP GET range requests to ask for just the parts of a file they need. See cogeo.org and this blog post for more detail. A very similar technology that enables you to instantly start watching a streaming video enables analysis on a large GeoTIFF without the need to download the entire file.
While a couple of different standards have tackled this problem, COG is well positioned to become the community and industry standard. Support for the new standard was quickly integrated into open source software libraries and it maintains backward compatibility; systems that can view a regular TIFF file can also view a COG, even if they are not leveraging the HTTP byte range reading or geospatial components. COGs are GeoTIFFS are TIFFs. In the short period since it was developed, the COG format has been rapidly adopted by Earth observation imagery providers because it represents a way to easily reduce network transfer costs in a distributed infrastructure. See Eugene Cheipesh's talk on Cloud Optimized GeoTIFFs at the 2018 FOSS4G-NA in St. Louis, where Eugene remarked, "I am pretty surprised to see a standing-room-only talk on a file format."
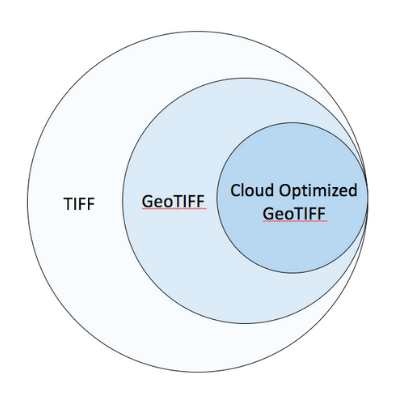
Diagram to describe that a Cloud Optimized GeoTIFF is a subset of a GeoTIFF, which is in turn a subset of a TIFF
As with many standards, like JSON and XML, there is nothing exceptional about the specification itself. Instead, the power is generated by the interoperable systems that are enabled by their widespread adoption.
SpatioTemporal Asset Catalog

The SpatioTemporal Asset Catalog (STAC) specification aims to standardize the way geospatial assets are exposed, discovered, and queried online. A 'spatiotemporal asset' is any file that represents information about the earth captured in a certain space and time. Unlike COG, which has already begun to establish itself in production workflows, STAC is a fairly new standard and there is an interesting and active discussion on the stac-spec GitHub repo.
As of the time of this writing, there have been three sprints focused on developing the specification with input from major imagery providers, remote sensing application creators, and developers from a number of geospatial technology companies. The initial specification includes a bare minimum number of fields required to make it a flexible, easily implemented standard, including; ID, type, geometry, and a link to the actual asset.
The long-term vision for STAC describes a transformation in the way humans interact with geospatial data. It envisions the ability to crawl both public and private data (when the right permissions are in place) from the world’s geospatial data providers, both large and small. Similar to how Google made the entire web searchable, the vision of STAC is to make all geospatial data queryable, what Chris Holmes has called, "A Queryable Earth". While STAC does not require COG, the two standards support each other.
GeoTrellis 2.0
In the November 2017 issue of the Eclipse newsletter, we announced the release of GeoTrellis 1.2. The project team has made several feature enhancement and changes since then, culminating in the release of GeoTrellis 2.0. A key advance has been the implementation of native COG support. This is an important step forward for integrating GeoTrellis with the cloud native geospatial ecosystem.
Additional improvements released with GeoTrellis 2.0 were performance and workflow optimizations. Notably:
- The move toward depending on cats rather than scalaz and a custom GeoTrellis functor implementation towards cats library usage.
- Reprojection, one of the most common operations in GeoTrellis, has improved performance due to one less shuffle stage and lower memory usage.
- The introduction of a Pyramid class to provide a wrapper for building raster pyramids.
- Collection Layer Readers SPI interface for CollectionLayerReaders.
GeoTrellis has always been designed to run in the cloud, so what is the significance of having native COG support in GeoTrellis? Previously GeoTrellis employed a custom Avro format for reading and writing layers. This meant that source data needed to be copied and rewritten in a format optimized for GeoTrellis that could not, however, be easily consumed by other components of an imagery processing workflow. This was a time-consuming, bandwidth-intensive process for massive, distributed imagery catalogs. The new COG support enables GeoTrellis to both read portions of images stored in the COG format and create new COG files. This reduces the cost and latency for both accessing and displaying imagery and using the imagery for analysis and machine learning applications.
Virtual Layer Mosaic
Now GeoTrellis can read and write COGs, but there are still limitations in the current architecture for working with massive imagery catalogs. Current GeoTrellis workflows require either reading all of the input files into distributed memory before any work can be done or undergoing an ETL process to create an index raster tile layer to support efficient queries. For example, let’s say you want to do a remote sensing analysis for the United States with the entire Landsat catalog on AWS. It would be untenable to fit the entire collection of scenes into the distributed memory of a cluster, but with standards like STAC, we expect that discovery and query of large image catalogs to become a more common use case.
The Virtual Layer Mosaic (VLM) is a concept the GeoTrellis team has been prototyping for working with large catalogs of raster data. VLM would enable the capability to perform remote sensing analysis on datasets without any data copying or reformatting. Rather, it would enable GeoTrellis to work directly with datasets that are stored in a variety of formats, leveraging COGs, when available, and eliminate the need to read every file into memory.
The underlying principle for Virtual Layer Mosaic is to separate the action of reading or querying imagery footprints and metadata from the action of reading the imagery cell values. This allows the insertion of a filter step before the read action and ability to push-down coregistration of multiple datasets into I/O stage where it is most efficient. Feature development on VLM is ongoing, and we hope to release initial support in Q1 2019. We have published a technical description and discussion of VLM in a GitHub issue.
Related Efforts
Map Algebra Modeling Language
Many of the imagery processing functions in GeoTrellis implement "Map Algebra", a set of operations for manipulating geospatial data developed by C. Dana Tomlin in the 1980s. The GeoTrellis project team has implemented a new Map Algebra Modeling Language (MAML), to support request for complex, multi-step raster processing enabling client software to craft sequences of image processing request through the direct construction and manipulation of map algebra expression trees. While the initial implementation is for GeoTrellis, it is not specific to GeoTrellis and could be used with other raster processing frameworks.
The main benefit of MAML is the ability to decouple the image processing request from the implementation of the processing. As a result, we can construct the program in the browser visually, or programmatically through custom MAML-based expression languages, and have its evaluation happen on a remote service with access to the data. Multiple evaluation strategies can be employed, e.g. to perform remote sensing band operations, to sample the data for quick preview or to trigger a distributed batch job.
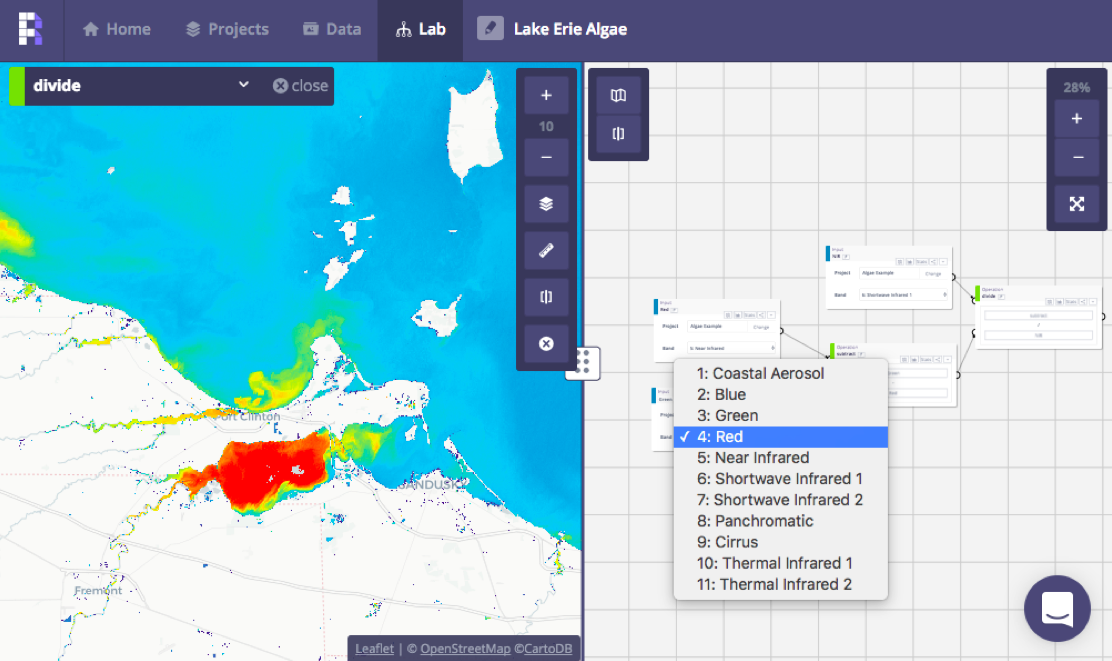
Screenshot of the ModelLab in Raster Foundry with a UI that describes operations used by MAML
The implementation of MAML has had benefits, but it has also introduced some complexity. Because dealing with these tree structures requires us to frame computation in terms of recursion, relatively sophisticated functional programming techniques turn out to be the most natural means of expressing the execution of a MAML program. This is a good fit for the Scala language in which GeoTrellis is written, but generalizing fold or reduce over structures with only a partial ordering (like a tree) introduces some new vocabulary for expressing computations as context-sensitive interpretations of abstract syntax trees (ASTs) a structure more commonly associated with compilers and interpreters.
GeoTrellis Server
GeoTrellis Server is a set of components designed to simplify viewing, processing, and serving raster data from arbitrary sources with an emphasis on doing so in a functional style. It aims to ease the challenges related to constructing complex raster processing workflows which result in TMS-based (z, x, y) and extent-based products. None of the tile serving code has been removed from GeoTrellis. Rather, the GeoTrellis Server project combines elements of GeoTrellis and MAML to simplify the process for creating a tile server while providing related utilities, like the ability to create MAML-generated histograms.
In addition to providing the mechanism for how sources of imagery can be displayed or returned, this project aims to simplify the creation of dynamic, responsive layers whose transformations can be described in MAML. In addition to MAML, GeoTrellis Server also supports the OGC WCS standard, and support for the OGC WMS standard will be available in Q1 2019.
Raster Foundry
Raster Foundry is an open source web application that provides a user interface for the GeoTrellis, MAML, and GeoTrellis Server technologies. It enables an easy-to-follow workflow accessible to non-experts. It makes it possible to search and perform analysis on the Landsat, Sentinel, and MODIS imagery datasets exposed through Earth on AWS. The Lab interface leverages MAML to make it possible to perform remote sensing band arithmetic and generate custom indices.
The recent incorporation of COG support in GeoTrellis now enables a Raster Foundry user immediately visualize and execute analysis functions with only a URL for a valid COG.
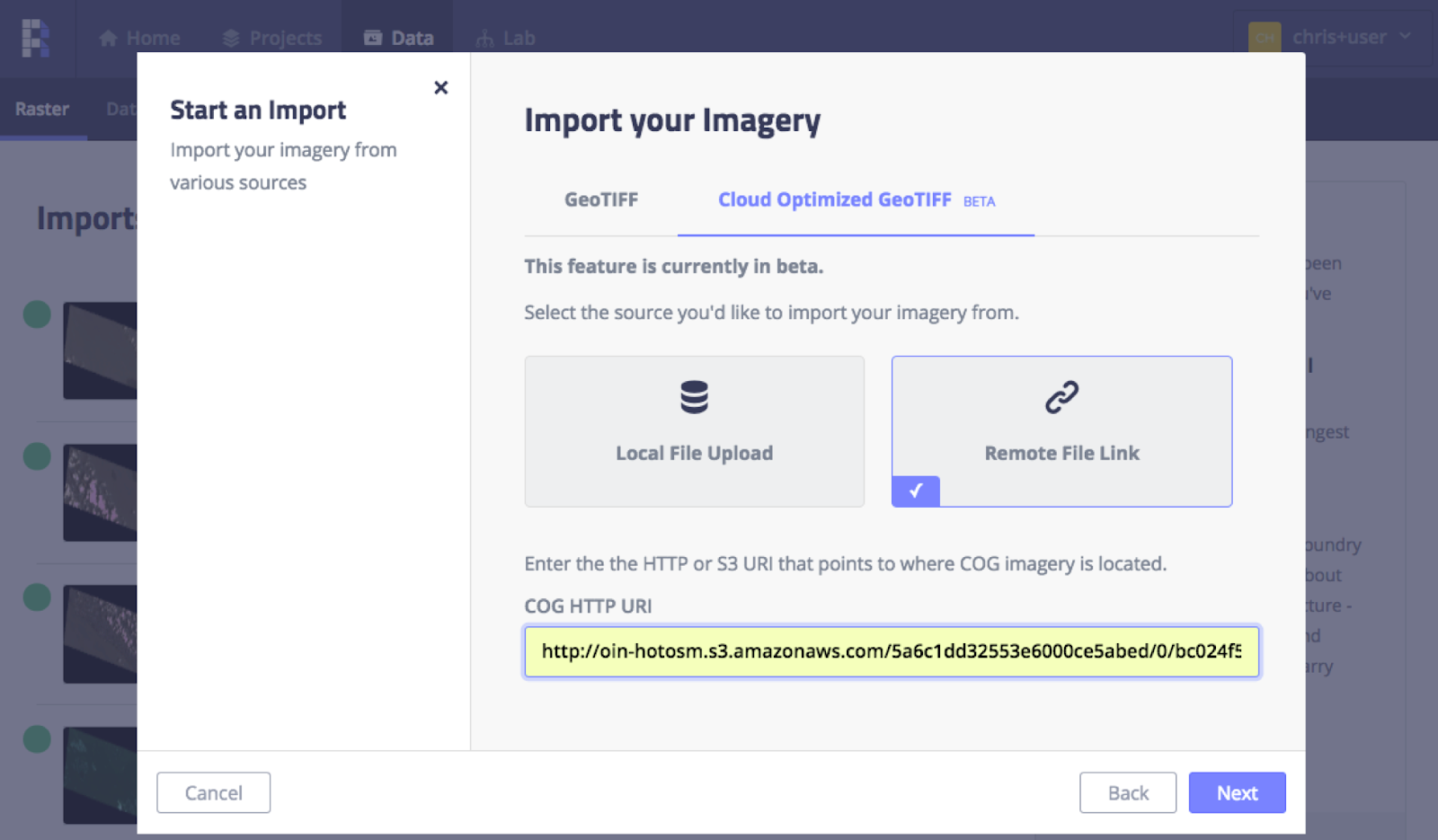
Screenshot from Raster foundry showing how to being in a Cloud Optimized GeoTIFF with a URL
Looking ahead
The establishment of open standards around the core building blocks for cloud native geospatial makes it easier to consume and produce data from and for diverse systems. This reduces the development time necessary to start a new analysis or tune a query for a specific data provider, reduces network traffic costs, and it reduces the overhead of data duplication.
COGs have already been implemented as a core component of GeoTrellis, making it easier to work with new datasets from any provider adopting the standard, including, notably Earth on AWS. GeoTrellis does not have feature support for STAC, but there is much promise. The anticipated workflow would be to provide access to large imagery catalogs that implement the STAC standard, describe the analysis through MAML, and then serve results through GeoTrellis Server. It will be possible to specify a unique query by region, time, cloud cover, etc. and generate a virtual layer mosaic (VLM) for analysis. We expect that there will a version of this analysis adapted to the browser for low latency data exploration and another version for performing batch jobs over large regions that will require more significant compute time.
The GeoTrellis project team is excited to be contributing to this broader vision for cloud native geospatial ecosystem. It is great to see so much development work happening in the open; both from the way the conversations about standards are occurring in public channels like GitHub, to the central role being played by open source tools. We are already seeing the benefit of the co-creation of shared standards when a diversity of voices and perspectives come together from the beginning.
About the Author
