GeoTrellis Adapts to Climate Change and Spark
GeoTrellis is a Scala project developed to support low latency geospatial data processing. GeoTrellis currently supports raster Map Algebra functions and transportation network features. It and used to both build fast, scalable web applications and perform batch processing of large data sets by supporting distributed and parallel processing that takes advantage of both multi-core processors and clusters of computing devices.
Over the past year the GeoTrellis project has undergone some significant changes. While many of these changes had been contemplated for a while, an opportunity to apply GeoTrellis to processing climate change data helped to accelerate their integration.
It’s About Time for Climate Data
A succession of hurricanes, typhoons, droughts and flooding in recent years has kept climate change on the front page for many communities and has underscored the need for improving local resilience to climate-related events. However, while climate impact at the planetary and continental scale are common news items, it is very difficult to translate this into specific actions that can be taken at the local or regional levels.
The conventional data sources for long-term climate forecasts are from the Intergovernmental Panel on Climate Change (IPCC) which releases climate forecasts every five years. These forecasts are the results of global circulation models (GCM) developed by leading climate research labs around the world. Each forecast includes approximately 100 years of projections for multiple temperature and precipitation variables. Each model is run based on the multiple carbon emission scenarios and more than thirty GCM models, each with daily and monthly output. The data released by the IPCC is not high resolution, but there are several efforts to "down-sample" this data to higher resolutions. Whether or not the climate forecasts are down-sampled, the climate forecast database can easily be up to dozens of terabytes in size.
GeoTrellis is designed for working with large geospatial databases, but the climate data is not simply geospatial. The data is usually available in the NetCDF format. Each NetCDF file contains monthly or daily forecasts for the next century (to 2099). One could think of this as a stack of spatial layers in which each day or month forecast is a separate slice. GeoTrellis was designed for working with large geospatial layers but not necessarily for data sets that combine space and time.
Apart from the climate data, the GeoTrellis framework had some additional objectives that were causing a reconsideration of its architecture. The GeoTrellis project implemented its distributed processing features using Akka, a Scala framework for building concurrent and distributed applications. After implementing some sophisticated geospatial data processing capabilities using the Akka framework, some new requirements began to emerge. These included support for caching, sharding of data sets across a storage cluster, and some more advanced fault tolerance features. It was feasible to build these features on top of our existing Akka-based work, but it was going to be a big project, so we took a look at other frameworks that might help us implement these features more rapidly, and the Spark project emerged as one of the better options.
Lighting a Spark in GeoTrellis
The Apache Spark project was originally developed by Matei Zaharia at UC Berkeley AMPLab to support fast cluster computing. It includes several components. The Spark Core implements distributed tasking, scheduling and basic I/O. Data is partitioned across machines using an abstraction called Resilient Distributed Datasets (RDDs). RDDs are then exposed via language-specific APIs. The developer manipulates the RDDs without having to worry about how the data is stored. The Spark ecosystem also includes Spark SQL for working with structured data, Spark Streaming for working with real-time streams of data, MLib for machine learning, and GraphX for graph data processing. While the ability to shard large data sets across nodes, support for a distributed file system and caching of intermediate results in memory were the key features that attracted us to Spark, the other work happening in the Spark ecosystem was also complementary and would likely have additional benefits in the future.
Nonetheless, integrating Spark in GeoTrellis was going to be a significant effort that would break all of the existing functionality. Further, it was clear that even after a Spark-based version of GeoTrellis was complete, it would require additional time to port all of the existing spatial data transformation functions to the new infrastructure. We decided to continue to support the existing Akka-based functionality while the Spark integration occurred in parallel and only deprecate the old architecture once all of the existing features could be supported.
Using Climate Change to Integrate Spark
In spring 2014, one of the companies supporting GeoTrellis development, Azavea, received a research grant from the U.S. Department of Energy to support fast computation of climate impact metrics for local and regional decision-makers. Over the past eight months, we have used the large climate forecast data sets and the climate impact metric calculation use case as the catalyst for making the shift to Spark. Along the way, we have had some incredible support from The Nature Conservancy, which has provided a well-organized set of climate forecasts in NetCDF format, assistance from Amazon Web Services (AWS) in the form of a Climate Research Grant, and a lot of hard work on the part of the GeoTrellis contributors. Spark has enabled us to add support for the Hadoop Distributed File System (HDFS). In addition, the large number of tiles that result from sharding tens of thousands of days of climate forecasts has led us to integrate support for Accumulo as a mechanism for efficiently indexing the tiles. This work is now largely complete and we are looking forward to a 0.10 release of GeoTrellis that will wrap up this significant re-architecture into a neat package.
Summary
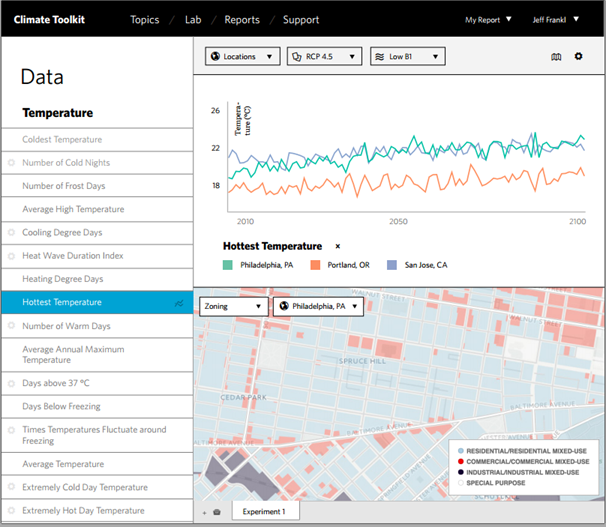
Working with climate data raised a number of key challenges that caused the GeoTrellis team to accelerate implementation of an otherwise daunting set of architectural changes. By integrating Spark, we have managed to maintain our focus on both lightning-fast spatial data processing and cluster-scale batch processing while also gaining several new features that lay a foundation for future growth in use of the GeoTrellis platform. In the process, we were also able to implement a prototype for a web application that will enable cities and regions to more effectively use the climate forecast data in ways that are relevant to their local circumstances.
Some of the work cited in this article was support by a grant from the U.S. Department of Energy (grant # DE-SC0011303).
Resources
- GeoTrellis on GitHub
- GeoTrellis Documentation
- Apache Spark
- Issue tracker for 0.10
- Down-sampled Climate Data on AWS
- IPCC Climate Data Distribution Centre
- IRC: #geotrellis on freenode
About the Authors
