Eclipse Microservices and Service Discovery
Introduction
Microservices are becoming increasingly important for enterprise applications in general and for the Java EE platform, which is a widely used platform. At first sight, it might look that building a microservice only requires packing a service into a standalone executable unit. However, it quickly becomes clear that a true microservice architecture is much more sophisticated and requires several building blocks, such as configuration, health checks, metrics, circuit breakers and other fault tolerance mechanisms, distributed logging, service discovery and other elements. All these pieces enable us to build resilient and scalable microservices.
In cloud-native architectures, microservices are usually combined with containers and container orchestration tools. Packing a microservice within a Docker container is a commonly accepted practice, whose potential is fully exploited when used within a container orchestration environment such as Kubernetes.
Executing microservices in such an environment provides several benefits. We do not have to execute the microservices manually. Instead, the container orchestration environment (aka Kubernetes) takes care of that. To achieve scalability, microservices can scale horizontally. This means, that we can execute several instances of the same microservice. We could do this manually, however Kubernetes can automate these tasks. We simply define the minimum and the maximum number of instances of a microservice (packed as Docker container) and Kubernetes will monitor the load and adjust the number of instances automatically. This way, we can achieve elasticity without manual intervention.
Kubernetes can also monitor the health of the instances and if it detects that a certain microservice container does not respond, it can automatically kill the container and replace it with a new instance. This can make applications more robust and less sensitive to failures [related: MicroProfile Health Check 1.0]. And things do not end here. Microservice architectures can monitor metrics [related: MicroProfile Health Metrics 1.0]. They can use circuit breakers to detect and limit the impact of failed microservice instances and so on. We will not go further into details here, as this is not the topic of this article. So, let us go back to the service discovery.
Service Discovery
In the previous section, we have briefly described how microservices can be dynamically created to achieve elasticity and monitored for health to improve resilience. When a new microservice, packed as Docker container, is instantiated, it gets an IP address assigned. When services are created and destroyed, the actual service addresses change all the time. Another important scenario are rapid deployments of new versions of microservices, which can run side-by-side with older versions.
All these scenarios show us that having the addresses of the microservices configured statically is undesirable; in some cases even impossible to manage. The number of microservice instances and their locations change. Since the addresses of microservices are unknown before instances are deployed, we need a way to discover their locations during runtime.
This brings us to service discovery. Service discovery allows microservice instances to register with a service registry. The clients that call the microservices can discover the microservices dynamically at runtime using a service registry. Although this approach sounds simple, it provides several benefits which we will describe in the next sections. And if some of you think that this is nothing new (even Java EE has JNDI for similar purposes), a closer look will show you that some important things are implemented in new, interesting ways (such as checking for services which are actually alive and omitting dead instances from the registry).
Registering Services
Let us look at typical scenarios with service discovery. The basic scenario would look like this:
- A Customer microservice registers itself with the registry at startup.
- A client wants to invoke the “list customers” operation, but first it must discover the Customer microservice. The client performs a lookup in the service registry.
- The registry responds with the location of the microservice.
- The client invokes the `getCustomers()` operation on the discovered service.
This is shown in the figure below:
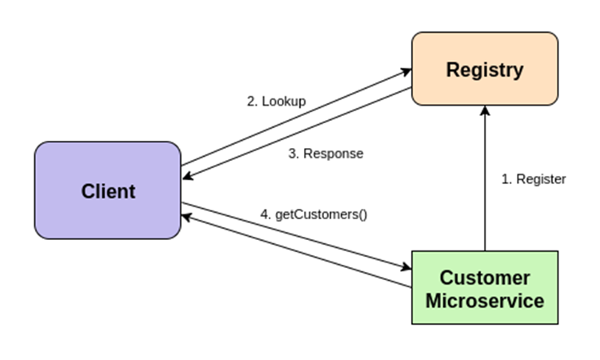
An important aspect for effective service discovery is the ability to detect the microservice instances, which do not exist anymore (because Kubernetes has destroyed them) or have become unresponsive (either due a failure or otherwise). This is usually solved in such a way that each microservice has to refresh its registered status by pinging the registry at a regular interval. If the service does not ping the registry, this means that it should not be registered anymore and the registry will remove the service key. Another way to achieve the same behavior is through health checks. The registry can use health checks on a microservice to determine if it is working correctly.
Multiple Instances and Load Balancing
We have already mentioned that to achieve elasticity we can horizontally scale microservices. This basically means that we run multiple instances of the same microservice. Multiple instances improve scalability and fault tolerance (if one instance fails, clients can use the other available instances).
Let us look at using multiple instances with service discovery. Multiple instances of the Customer microservice are registered in the registry. When the client looks up a microservice, one of the instances is picked. This way, we can achieve load balancing without the need of a dedicated load balancer. Load balancing can be done either by the client or by the service registry. Client side load balancing is often a better choice, because in this case a client can load balance each call to the microservice and pick a different instance on every invocation. This is shown on the figure below:
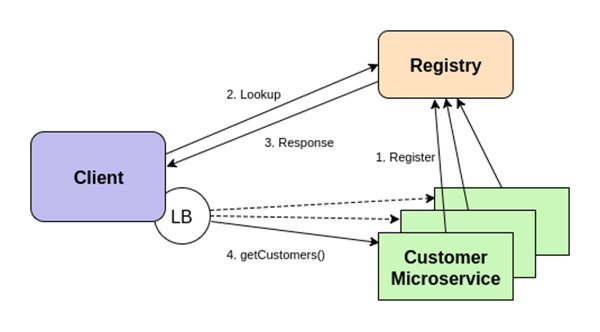
To minimize the number of registry lookups, service discovery is often implemented in such a way that the client caches service locations in its internal buffer and sets a watch on the registry. If a service is added or removed, the registry notifies the client about the changes.
API Gateways
Sometimes an API gateway is deployed between the client and the microservices. An API gateway provides several features, such as access control, rate limiting, policy enforcement, etc. In combination with service discovery, the scenario that includes the API gateway would look like this:
- Each instance of the Customer microservice registers itself to the registry at startup
- Client performs a lookup on the registry to discover the Customer microservice.
- The registry responds with the location of the API gateway.
- The client invokes an operation using the API gateway location.
- The API gateway processes the call and forwards it to the requested microservice service.
This is shown on the figure below:
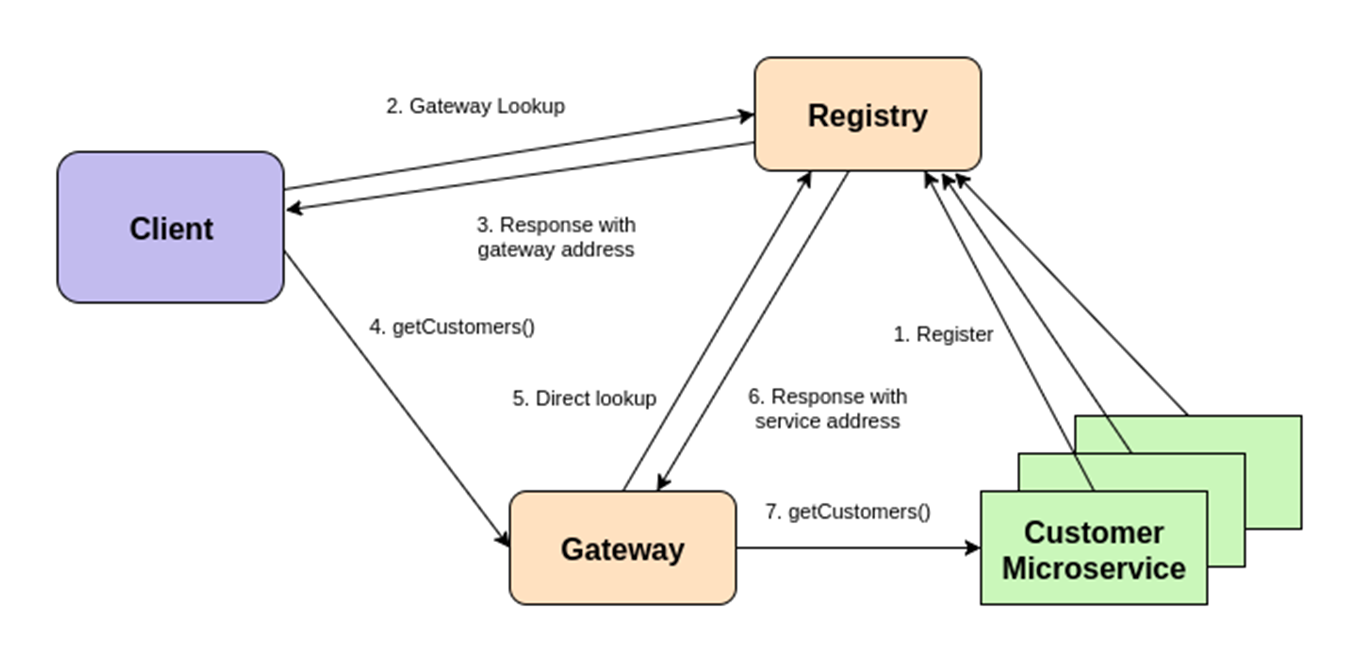
In the above scenario, both the API gateway address and the microservice instance addresses must be stored in the registry.
Kubernetes and Container Orchestration Environments
Running microservices in container orchestration environments such as Kubernetes introduces additional complexity. The goal is to enable outside clients to discover services in the cluster by their external address, which are exposed by Kubernetes (NodePort) and to enable services in cluster to discover each other by their internal address (Pod IP).
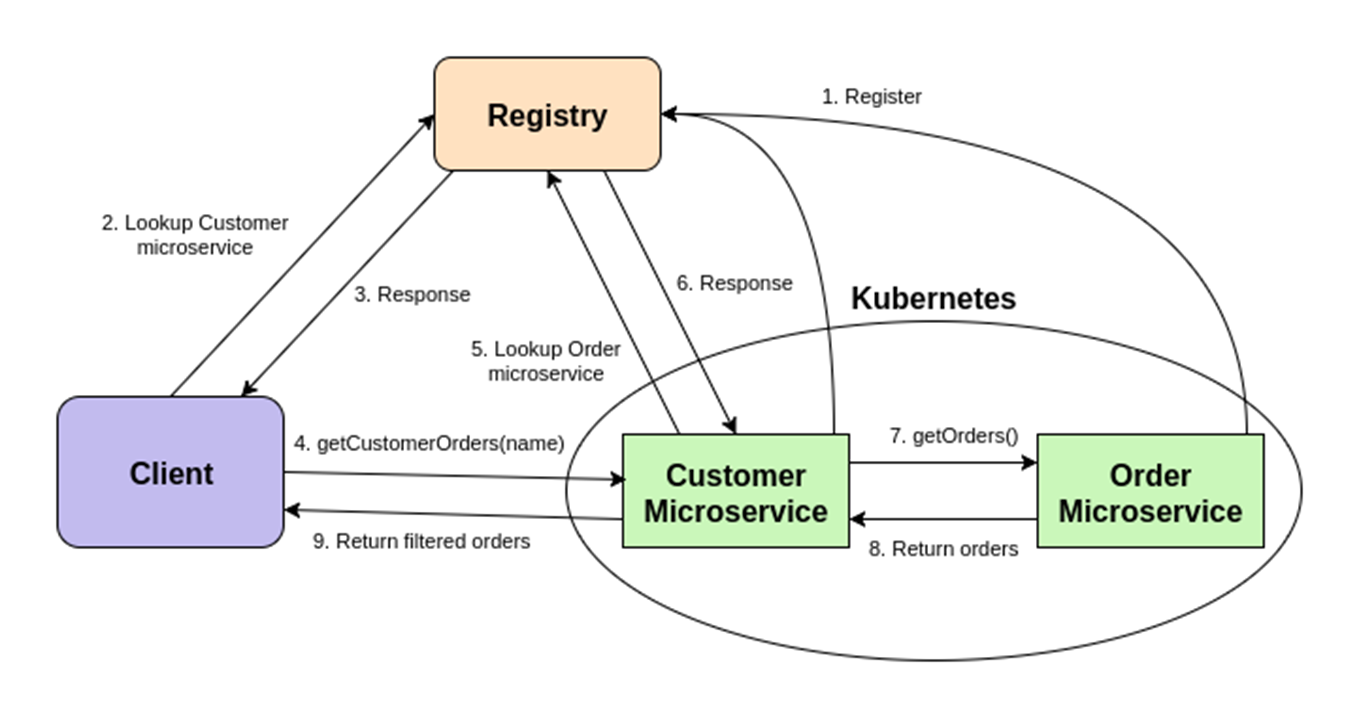
Consider the following scenario:
- The Customer microservice and the Order microservice, which are running inside the Kubernetes cluster, register themselves to the registry.
- A client, running outside the cluster, performs a lookup in the registry for the Customer microservice.
- The client receives the Customer microservice external address from the registry.
- The client invokes the `getCustomerOrders(name)` operation on the discovered service.
- The Customer microservice needs to get the list of orders from the Order microservice in order to complete client's request. It performs a lookup in the registry for the Order microservice.
- The registry responds with the internal address of the Order microservice (as this is a service to service call). If a client outside the cluster wants to discover the Order microservice, the service would be discovered by its external address.
- The Customer service invokes the `getOrders()` operation on the Order microservice.
- The Order service returns the result.
- The Customer service does the processing and returns the result to the client.
This is shown in the following figure:
Service Discovery in KumuluzEE
KumuluzEE is an open-source framework for developing Java EE based microservices. It has received the Java Duke’s Choice Award. KumuluzEE provides support for service discovery by introducing simple annotations for REST services.
To automatically register a service, we can use the @RegisterService annotation and put it on the Application class of a REST service. For example:
@RegisterService(value = "customer-service", environment = "dev", version = "1.0.0") @ApplicationPath("v1") public class CustomerApplication extends Application { }
To discover the service, the client can use the `@DiscoverService` to inject the reference. For example:
@Inject @DiscoverService(value = "customer-service", environment = "dev", version = "1.0.x") private URL url;
There are various arguments available, including the environment, version, etc., which can be provided in the annotation or as a part of configuration. These annotation also support API gateways, where we can use the accessType parameter to define, whether we which direct connection or a connection through the gateway:
@Inject @DiscoverService(value = "customer-service", environment = "dev", version = "1.0.x", accessType = AccessType.DIRECT) private URL url;
Kubernetes is also supported. For the above-mentioned Kubernetes scenario, the following configuration can be specified:
- We have to specify the ID of the Kubernetes cluster using the kumuluzee.discovery.cluster key.
- We specify the external address using the kumuluzee.server.base-url key. This address will be used for external connections. For internal connections, an internal address is obtained automatically when the service starts.
KumuluzEE currently supports two registries, etcd and Consul. etcd is a distributed reliable key-value store, which is natively used by Kubernetes. Consul architecture consists of standalone server nodes (similar to etcd nodes) and agents, which are deployed beside every service.
For more information regarding KumuluzEE Discovery, please refer to https://github.com/kumuluz/kumuluzee-discovery
Conclusion
Service discovery is an essential part of microservice architecture and becomes necessary when we start using containers and container orchestration mechanisms. In this article, we have described the most important scenarios for service discovery. We have also briefly mentioned the service discovery support in the KumuluzEE microservice framework, which is a member of the Microprofile.io and provides support for building microservices using Java EE.
Registries, used for service discovery are usually used for dynamic configuration as well. Besides storing the location of microservice instances, registries are an appropriate storage for configuration too. Particularly when dealing with a large number of instances, having a central configuration registry can be very valuable.
With Service Discovery being an important component of a Microservices Architecture, do you think MicroProfile should consider a Service Discovery specification? If so, join the MicroProfile Google Group and start (or contribute to) a discussion!
About the Authors

