6. Type System
6.1. Type Model and Grammar
The type model is used to define actual types and their relations (meta-model is defined by means of Xcore in file Types.xcore)
and also references to types (meta-model in TypeRefs.xcore). The type model is built via the N4JSTypesBuilder when a resource
is loaded and processed, and most type related tasks work only on the type model. Some types that are (internally) available
in N4JS are not defined in N4JS, but instead in a special, internal type language not available to N4JS developers, called N4TS
and defined in file Types.xtext.
The types are referenced by AST elements; vice versa the AST elements can be referenced from the types (see SyntaxRelatedTElement).
This backward reference is a simple reference to an EObject.
6.1.1. Type Model Overview
The following figure, Types and Type References, shows the classes of the type model and their inheritance relations, both the actual type definitions as defined in Types.xcore and the type references defined in TypeRefs.xcore. The most important type reference is the ParameterizedTypeRef; it is used for most user-defined references, for both parameterized and non-parameterized references. In the latter case, the list of type arguments is empty.
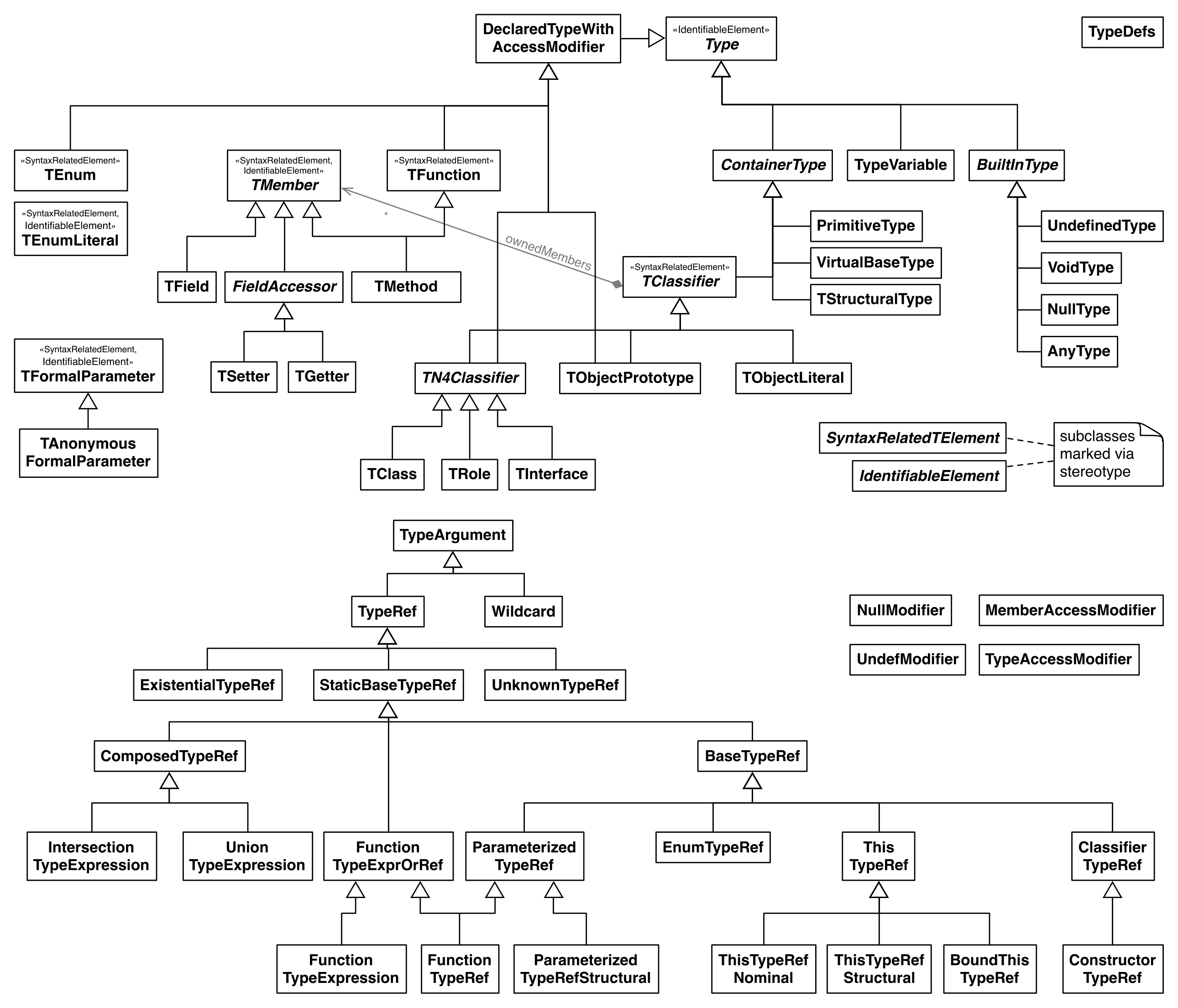
Most types are self-explanatory. TypeDefs is the container element used in N4TS. Note that not all types and properties of types are available in N4JS – some can only be used in the N4TS language or be inferred by the type system for internal purposes. Some types need some explanation:
-
TObjectPrototype: Metatype for defining built-in object types such asObjectorDate, only available in N4TS. -
VirtualBaseType: This type is not available in N4JS. It is used to define common properties provided by all types of a certain metatype. E.g., it is used for defining some properties shared by all enumerations (this was the reason for introducing this type).
We distinguish four kinds of types as summarized in Kind Of Types. Role is an internal construct for different kind of users who can define the special kind of type. The language column refers to the language used to specify the type; which is either N4JS or N4TS.
| Kind | Language | Role | Remark |
|---|---|---|---|
user |
N4JS |
developer |
User defined types, such as declared classes or functions. These types are to be explicitly defined or imported in the code. |
library |
N4JSD |
developer |
Type declarations only, comparable to C header files, without implementation. Used for defining the API of 3rd party libraries. These type definitions are to be explicitly defined or imported in the code. |
builtin |
N4TS |
smith |
Built-in ECMAScript objects interpreted as types. E.g., |
primitive |
N4TS |
smith |
Primitive ECMAScript (and N4JS ties), such as |
6.1.2. Built-in and Primitive Types
The built-in and primitive types are not defined by the user, i.e. N4JS programmer. Instead, they are defined in special
internal files using the internal N4TS language: builtin_js.n4ts, builtin_n4.n4ts, primitives_js.n4ts, primitives_n4.n4ts.
6.1.3. Type Model DSL
For defining built-in types and for tests, a special DSL called N4TS is provided by means of an Xtext grammar and generated
tools. The syntax is similar to n4js, but of course without method or function bodies, i.e. without any statements of expressions.
The grammar file is found in Types.xtext.
The following list documents some differences to N4JS:
-
access modifiers directly support
Internal, so no annotations are needed (nor supported) here. -
besides N4 classifiers such as classes, the following classifiers can be defined:
-
objectdefine classes derived from object (predefined object types) Special features:indexed defined what type is returned in case of index access
-
virtualBasevirtual base types for argument
-
-
primitiveprimitive types (number, string etc.) Special features:indexed defined what type is returned in case of index access
autoboxedType defines to which type the primitive can be auto boxed
assignmnentCompatible defines to which type the primitive is assignment compatible
-
types
any,null,void,undefined– special types.
Annotations are not supported in the types DSL.
6.2. Type System Implementation
The bulk of the type system’s functionality is implemented in packages org.eclipse.n4js.typesystem[.constraints|.utils].
Client code, e.g. in validations, should only access the type system through the facade class N4JSTypeSystem.
Each of the main type system functions, called "judgments", are implemented in one of the concrete subclasses of
base class AbstractJudgment. Internally, the type system is using a constraint solver for various purposes;
entry point for this functionality is class InferenceContext. All these classes are a good entry point into
the code base, for investigating further details.
Some type information is cached (e.g., the type of an expression in the AST) and the above facade will take care to read from the cache instead of re-computing the information every time, as far as possible. This type cache is being filled in a dedicated phase during loading and processing of an N4JS resource; see Type Inference of AST and N4JS Resource Load States for details.
6.3. Type Inference of AST
Most judgments provided by the facade N4JSTypeSystem and implemented by subclasses of AbstractJudgment are used
ad-hoc whenever client code requires the information they provide. This is applied, in particular, to judgments
-
subtype -
substTypeVariables -
upperBound/lowerBound
For judgment type footnote:type, not for expectedType,
but this may be changed in a future, further refactoring.], however, the processing is very different: we make
sure that the entire AST, i.e. all typable nodes of the AST, will be typed up-front in a single step, which
takes place during the post-processing step of an N4JSResource (see N4JS Resource Load States), which
also has a couple other responsibilities. By triggering post-processing when client code invokes the type judgment
for the first time for some random AST node (at the latest; usually it is triggered earlier), we make sure that
this sequence is always followed.
The remainder of this section will explain this single-step typing of the entire AST in detail.
6.3.1. Background
Originally, the N4JS type system could be called with any EObject at any given time, without any knowledge of the
context. While this looked flexible in the beginning, it caused severe problems solving some inference cases, e.g.,
the rule environment had to be prepared from the outside and recursion problems could occur, and it was also
inefficient because some things had to be recalculated over and over again (although caching helped).
It is better to do type inferencing (that is, computing the type of expressions in general) in a controlled manner. That is, instead of randomly computing the type of an expression in the AST, it is better to traverse the AST in a well-defined traversal order. That way, it is guaranteed that certain other nodes have been visited and, if not, either some special handling can kick in or an error can be reported. This could even work with XSemantics and the declarative style of the rules. The difference is that by traversing the AST in a controlled manner, the rules can make certain assumptions about the content of the rule-environment, such as that it always contains information about type variable bindings and that it always contains information about expected types etc.
In that scenario, all AST nodes are visited and all types (and expected types) are calculated up-front. Validation
and other parts then do not need to actually compute types (by calling the actual, Xsemantics-generated type system);
instead, at that time all types have already been calculated and can simply be retrieved from the cache (this is
taken care of by the type system facade N4JSTypeSystem).
This also affects scoping, since all cross-references have to be resolved in this type computation step. However, even for scoping this has positive effects: E.g., the receiver type in property access expressions is always visited before visiting the selector. Thus it is not necessary to re-calculate the receiver type in order to perform scoping for the selector.
The above refactoring was done in summer 2015. After this refactoring, we are still using Xsemantics to compute the
types, i.e. the type judgement in Xsemantics was largely kept as before. However, the type judgment is invoked
in a controlled traversal order for each typable AST node in largely one step (controlled by ASTProcessor and TypeProcessor).
The upshot of this one-step type inference is that once it is completed, the type for every typable AST node is known. Instead of storing this information in a separate model, this information will be stored and persisted in the type model directly, as well as in transient fields of the AST [1]. Currently, this applies only to types, not expected types; the inference of expected types could / should be integrated into the one-step inference as part of a future, further refactoring.
| Before | After |
|---|---|
ad-hoc type inference (when client code needs the type information) |
up-front type inference (once for entire AST; later only reading from cache) |
started anywhere |
starts with root, i.e. the |
Xsemantics rules traverse the AST at will, uncontrolled |
well-defined, controlled traversal order |
lazy, on-demand resolution of |
pro-active resolution of
|
6.3.2. Triggering
The up-front type inference of the entire AST is part of the post-processing of every N4JSResource and is thus triggered when post-processing is triggered. This happens when
-
someone directly calls
#performPostProcessing()on an N4JSResource -
someone directly calls
#resolveAllLazyCrossReferences()on an N4JSResource, -
EMF automatically resolves the first proxy, i.e. someone calls an EMF-generated getter for a value that is a proxy,
-
someone asks for a type for the first time, i.e. calls
N4JSTypeSystem#type(), -
…
Usually this happens after the types builder was run with preLinking==false and before validation takes place.
For details, see classes PostProcessingAwareResource and N4JSPostProcessor.
6.3.3. Traversal Order
The traversal order during post-processing is a bit tricky, as some things need to be done in a top-down order (only few cases, for now [2]), others in a bottom-up order (e.g. the main typing of AST nodes), and there is a third case in which several AST nodes are processed together (constraint-based type inference).
Figure Order in which AST nodes are being processed during post-processing. provides an example of an AST and shows in which order the nodes are processed. Green numbers represent top-down processing, red numbers represent bottom-up processing and blue numbers represent the processing of the surrounding yellow nodes in a single step.
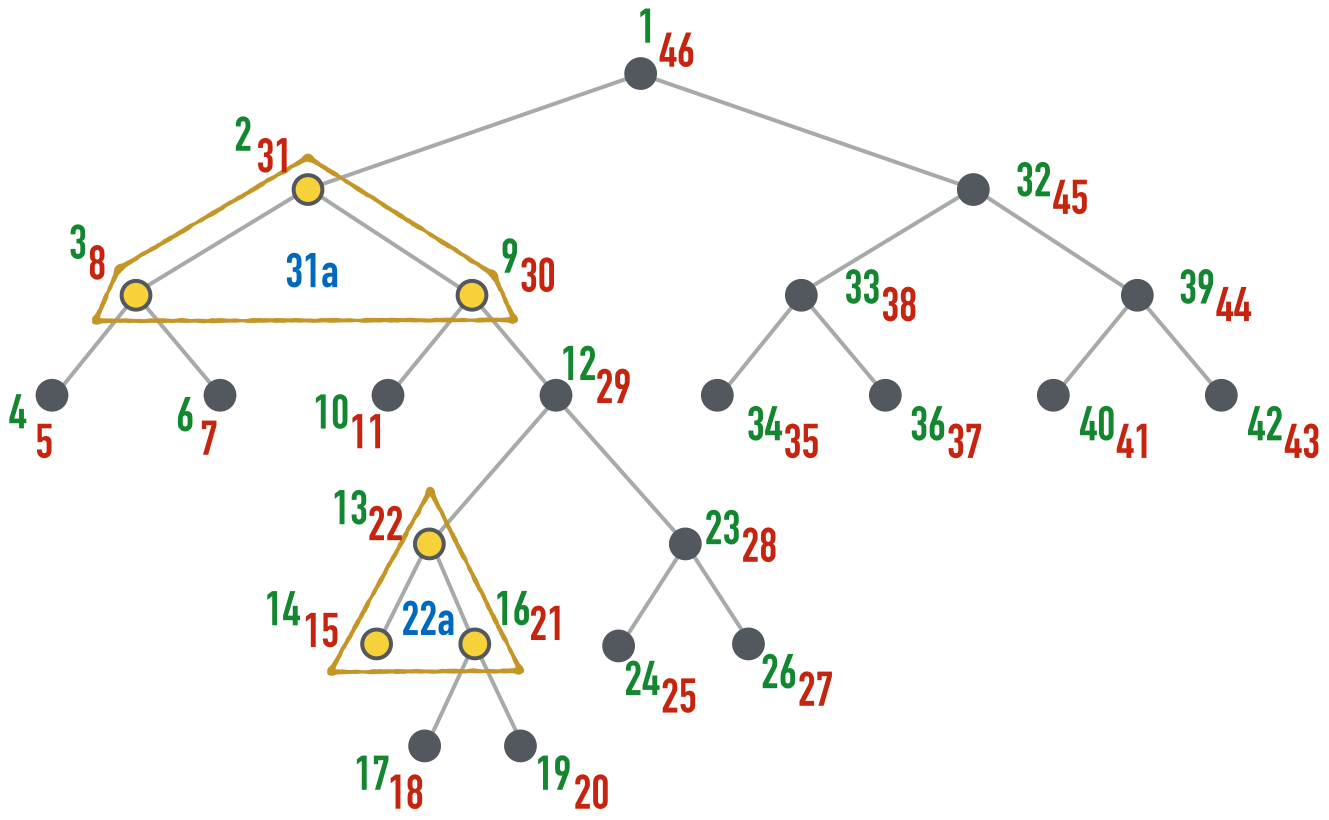
In the code, this is controlled by class ASTProcessor. The two main processing methods are
-
#processNode_preChildren(), which will be invoked for all AST nodes in a top-down order (so top-down processing should be put here), -
#processNode_postChildren(), which will be invoked for all AST nodes in a bottom-up order (so bottom-up processing should be put here).
The common processing of groups of adjacent yellow nodes (represented in the figure by the two yellow/brown
triangles) is achieved by PolyProcessor telling the TypeProcessor to
-
ignore certain nodes (all yellow nodes) and
-
invoke method
PolyProcessor#inferType()for the root yellow node in each group (only the root!). . For details, see the two methods#isResponsibleFor()and#isEntryPoint()inPolyProcessor.
6.3.4. Cross-References
While typing the entire AST, cross-references need special care. Three cases of cross-references need to be distinguished:
| backward reference |
= cross-reference within the same file to an AST node that was already processed
|
| forward reference |
= cross-reference within the same file to an AST node that was not yet processed
|
| references to other files |
|
Note that for references to an ancestor (upward references) or successor (downward references) within an AST, the classification as a forward or backward reference depends on whether we are in top-down or bottom-up processing. Figure Upward Downward illustrates this: the left and right side show the same AST but on the left side we assume a top down processing whereas on the right we assume a bottom up processing. On both sides, backward references are shown in green ink (because they are unproblematic and always legal) and forward references are shown in red ink. Now, looking at the two arrows pointing from a node to its parent, we see that it is classified as a backward reference on the left side (i.e. top down case) but as a forward reference on the right side (i.e. bottom down case). Conversely, an arrow from a node to its child is classified as a forward reference on the left side and as a backward reference on the right side. Arrows across subtrees, however, are classified in the same way on the left and right side (see the horizontal arrows at the bottom).

6.3.5. Function/Accessor Bodies
An important exception to the basic traversal order shown in Figure Order in which AST nodes are being processed during post-processing. is that the body of all functions (including methods) and field accessors is postponed until the end of processing. This is used to avoid unnecessary cycles during type inference due to a function’s body making use of the function itself or some other declarations on the same level as the containing function. For example, the following code relies on this:
let x = f();
function f(): X {
if(x) {
// XPECT noerrors --> "any is not a subtype of X." at "x"
return x;
}
return new X();
}Similar situation using fields and methods:
class C {
d = new D();
mc() {
// XPECT noerrors --> "any is not a subtype of D." at "this.d"
let tmp: D = this.d;
}
}
class D {
md() {
new C().mc();
}
}For details of this special handling of function bodies, see method ASTProcessor#isPostponedNode(EObject) and field
ASTMetaInfoCache#postponedSubTrees and the code using it. For further investigation, change isPostponedNode() to always
return false and debug with the two examples above (which will then show the incorrect errors mentioned in the XPECT
comments) or run tests to find more cases that require this handling.
6.3.6. Poly Expressions
Polymorphic expressions, or poly expressions for short, are expressions for which the actual type depends on the expected type and/or the expected type depends on the actual type. They require constraint-based type inference because the dependency between the actual and expected type can introduce dependency cycles between the types of several AST nodes which are best broken up by using a constraint-based approach. This is particularly true when several poly expressions are nested. Therefore, poly expressions are inferred neither in top-down nor in bottom-up order, but all together by solving a single constraint system.
Only a few types of expressions can be polymorphic; they are called poly candidates: array literals, object literals, call expressions, and function expressions. The following rules tell whether a poly candidate is actually poly:
-
ArrayLiteral— always poly (because their type cannot be declared explicitly). -
ObjectLiteral— if one or more properties do not have a declared type. -
CallExpression— if generic & not parameterized. -
FunctionExpression— if return type or type of one or more formal parameters is undeclared.
This is a simplified overview of these rules, for details see method #isPoly(Expression) in AbstractPolyProcessor.
The main logic for inferring the type of poly expressions is found in method #inferType() in class PolyProcessor.
It is important to note that this method will only be called for root poly expressions (see above). In short, the basic
approach is to create a new, empty InferenceContext, i.e. constraint system, add inference variables and constraints for
the root poly expression and all its nested poly expressions, solve the constraint system and use the types in the solution
as the types of the root and nested poly expressions. For more details see method #inferType() in class PolyProcessor.
So, this means that nested poly expressions do not introduce a new constraint system but instead simply extend their parent poly’s constraint system by adding additional inference variables and constraints. But not every nested expression that is poly is a nested poly expression in that sense! Sometimes, a new constraint system has to be introduced. For example:
-
child poly expressions that appear as argument to a call expression are nested poly expressions (i.e. inferred in same constraint system as the parent call expression),
-
child poly expressions that appear as target of a call expression are not nested poly expressions and a new constraint system has to be introduced for them.
For details see method #isRootPoly() in AbstractPolyProcessor and its clients.
6.3.7. Constraint Solver
The simple constraint solver used by the N4JS type system, mainly for the inference of poly expressions, is implemented
by class InferenceContext and the other classes in package org.eclipse.n4js.typesystem.constraints.
The constraint solving algorithm used here is largely modeled after the one defined in The Java Language Specification 8,
Chapter 18, but was adjusted in a number of ways, esp. by removing functionality not required for N4JS (e.g. primitive types,
method overloading) and adding support for specific N4JS language features (e.g. union types, structural typing).
For details see the API documentation of class InferenceContext.
6.3.8. Type Guards
During AST post-processing, the control and data flow analyses are performed.
This means, that first a flow graph is created and then traversed.
During the traversal, a type guard analysis is performed which saves information by evaluating instanceof expressions.
As a result, the analysis provides a reliable set of RHS expressions of instanceof expressions for each AST element of type IdentifierRef.
This set is evaluated in the TypeJudgments.java when typing IdentifierRef elements.
In case the set is not empty, the types of all elements is calculated.
The type of the IdentifierRef will then become the intersection of its original type and all types previously calculated.
6.4. Structural Typing
Structural typing as an optional subtyping mode in N4JS is implemented in StructuralTypingComputer, activated depending on
the value of property typingStrategy in ParameterizedTypeRef and its subclasses.