Home » Language IDEs » Java Development Tools (JDT) » Console input encoding
| Console input encoding [message #669807] |
Wed, 11 May 2011 15:18  |
 Christian Schroeder Christian Schroeder
Messages: 1
Registered: May 2011 |
Junior Member |
|
|
Hi all,
I am new to Eclipse, but have several years of Java experience. I have some problems with the encoding of the console when reading data.
I use Eclipse Helios in a Windows environment. I have set the text file encoding (Preferences -> General -> Workspace) to UTF-8. In the project's "Run/Debug" settings on the "Common" tab the encoding is set to "Default - inherited (UTF-8)". The default encoding for the JVM has not been set (i.e. no "-Dfile.encoding=..."), but that should not matter anyway.
I have written an application with the following test code:
byte[] buffer = new byte[1024];
int bytesRead = System.in.read(buffer);
for (int i = 0; i < bytesRead; i++)
System.out.printf("%X\n", buffer[i]);
I deliberately do NOT use a reader to avoid any decoding by the application. Instead, I just want to see the raw bytes that come from the input stream.
When I type the character "LATIN SMALL LETTER A WITH DIAERESIS" on my keyboard, I get the following bytes: C3 83 C2 A4. When I type the character "LATIN CAPITAL LETTER A WITH DIAERESIS", I get even five bytes: C3 83 E2 80 9E. I expected to see "C3 A4" and "C3 84", respectively.
Can anybody explain this behavior? Of course, when I try to decode the data using any encoding I just get rubbish.
Thanks for your help!
Christian
|
|
|
| Re: Console input encoding [message #880798 is a reply to message #669807] |
Sun, 03 June 2012 02:19  |
John Keck
Messages: 3
Registered: June 2012 |
Junior Member |
|
|
Hi Christian,
I'm having the same problem. I've pasted my sample code and output below. (Also posted here: stackoverflow.com/questions/10858643/how-to-read-unicode-greek-from-the-keyboard.)
This fellow (Michael Waldvogel, "org.eclipse.ui.console with UTF-8 ?! is getting something similar:
Quote:The problem is, that I try to input Japanese (Chinese and Korean does also not work) characters. They are shown right in the console view. I set the console encoding to UTF-8 in the Run configuration (Tab Common). When I read from the InputStream System.in I don't get my input UTF-8 encoded input string. I directly read the input from the InputStream to directly check the byte stream. Counterwise, all UTF-8 character output is being shown only as asteriks. (URL: www.eclipsezone.com/eclipse/forums/t73365.html;--I'm too new to post links.)
Apparently no one has answered you in the year since you posted, nor has anyone answered Mr. Waldvogel in the five years since he posted, nor can I find an answer on the web. It does seem however that since 2006, someone's cleaned up the output problem.
Like Mr. Waldvogel, I've set the coding for the class as UTF-8. The Greek text displays fine, it's just the input that's messed up, as you can see below.
I'm wondering if I should submit a bug report.
Here's my code:
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class GreekConsoleInputTest {
public static void main(String[] args) {
String word = "αβγδεζηθικλμνξοπρσςτυφχψω";
System.out.println("\n\n" + word + "\n");
String answer = getInput("Type the word above: ");
System.out.println("\nThis is what the computer took from the keyboard:");
printCharsAndCode(answer);
System.out.println("\nThis is what it should look like:");
printCharsAndCode(word);
}
private static String getInput(String prompt) {
System.out.print(prompt);
System.out.flush();
try {
BufferedReader in = new BufferedReader(new InputStreamReader(System.in, "UTF8"));
return in.readLine();
}
catch (Exception e) {
return "Error: " + e.getMessage();
}
}
/* prints the character and its (unicode) code */
public static void printCharsAndCode(String str) {
// int len = str.length();
char[] c = str.toCharArray();
System.out.println(str);
for (char d : c) {
System.out.print(" " + d + " ");
if (Character.getType(d) == 6) System.out.print(" "); //extra space to make combining diacritics display rightly (NON_SPACING_MARK)
}
System.out.println();
for (char d : c) {
int ic = (int) d;
System.out.printf("%1$#05x ", (int) d);
}
System.out.println();
}
}
This is the output:
αβγδεζηθικλμνξοπρσςτυφχψω
Type the word above: αβγδεζηθικλμνξοπρσςτυφχψω
This is what the computer took from the keyboard:
αβγδεζηθικλμνξοπÏ�σςτÏ...φχψω
Î ± Î ² Î ³ Î ´ Î µ Î ¶ Î · Î ¸ Î ¹ Î º Î » Î ¼ Î ½ Î ¾ Î ¿ Ï € Ï � Ï ƒ Ï ‚ Ï „ Ï ... Ï † Ï ‡ Ï ˆ Ï ‰
0x0ce 0x0b1 0x0ce 0x0b2 0x0ce 0x0b3 0x0ce 0x0b4 0x0ce 0x0b5 0x0ce 0x0b6 0x0ce 0x0b7 0x0ce 0x0b8 0x0ce 0x0b9 0x0ce 0x0ba 0x0ce 0x0bb 0x0ce 0x0bc 0x0ce 0x0bd 0x0ce 0x0be 0x0ce 0x0bf 0x0cf 0x20ac 0x0cf 0xfffd 0x0cf 0x192 0x0cf 0x201a 0x0cf 0x201e 0x0cf 0x2026 0x0cf 0x2020 0x0cf 0x2021 0x0cf 0x2c6 0x0cf 0x2030
This is what it should look like:
αβγδεζηθικλμνξοπρσςτυφχψω
α β γ δ ε ζ η θ ι κ λ μ ν ξ ο π ρ σ ς τ υ φ χ ψ ω
0x3b1 0x3b2 0x3b3 0x3b4 0x3b5 0x3b6 0x3b7 0x3b8 0x3b9 0x3ba 0x3bb 0x3bc 0x3bd 0x3be 0x3bf 0x3c0 0x3c1 0x3c3 0x3c2 0x3c4 0x3c5 0x3c6 0x3c7 0x3c8 0x3c9
Have you come across a solution? Or can anyone else out there in eclipse-land help with some guidance?
[Updated on: Sun, 03 June 2012 02:21] Report message to a moderator |
|
| | |
| Output of combining characters [message #886756 is a reply to message #885155] |
Fri, 15 June 2012 15:23 |
John Keck
Messages: 3
Registered: June 2012 |
Junior Member |
|
|
Thanks, Dani, for your reply. I appreciate it and look forward to the new version of Eclipse.
I hope this isn't too off-topic for this thread, but I've just noticed another couple issues with Unicode and the Eclipse console--has to do with display of "combining characters" (and Unicode normalization).
In this discussion, it's good to keep in mind the Unicode standard as described here: unicode.org/reports/tr15/. For ease of reference, here is Java 7's Normalizer class doc docs.oracle.com/javase/7/docs/api/java/text/Normalizer.html. (I still can't post links.)
Below I've pasted some code that shows the trouble, along with its output. (Again, I'm using polytonic Greek.) The first glyph in each grouping (before the colon) is how the following two should look. You can see how putting the breathing mark first after the letter makes the second glyph turn out properly, whereas putting the accent first makes it turn out wrong. (The macron case is special, because there are no single glyphs with macrons and accents/breathing marks.)
It appears to me that there are two closely related issues.
The first issue is that Java's Normalizer.normalize method doesn't follow the Unicode standard in displaying combining diacritics in whatever order as the same unitary glyph (as is evident from the codepoints beneath).
Quote:That process logically starts at the front of the string and systematically checks it for pairs of characters which meet certain criteria and for which there is a canonically equivalent composite character in the standard. Each appropriate pair of characters which meet the criteria is replaced by the composite character, until the string contains no further such pairs. This transforms the fully decomposed string into its most fully composed but still canonically equivalent sequence.
Failing to do that is no small breach! I'm reporting the bug to the Java folks.
The second issue is that Eclipse shows some orderings of combining characters as if they were part of the next character, and not part of the preceding character (as they should be). This happens in the editor and not only in the console. This would appear to be a problem with the way Eclipse displays and not with Java itself (though Java's problem might be implicated)-- at very least the messy diacriticals should appear over the proper glyph.
Actually, it might be impossible to disentangle the two issues for Eclipse. Nevertheless I would guess there is a workaround, as far as display is concerned, that would bypass Java's deficiencies. I could be wrong though.
What do you think?
import java.text.Normalizer;
/* Compare to Unicode standard at unicode.org/reports/tr15/
* Normalizer docs: docs.oracle.com/javase/7/docs/api/java/text/Normalizer.html
*
* NFD: 1[ἅ: ά̔ ἅ] 2[ἄ: ά̓ ἄ] 3[ἃ: ὰ̔ ἃ] 4[ἂ: ὰ̓ ἂ] 5[ᾁ: ᾁ ᾁ] 6[ἂ: ὰ̓ ἂ] 7[ἇ: ᾶ̔ ἇ] 8[ᾱ̔ . ἁ̄ ᾱ̔ ]
*/
public class DiacriticalTest {
/**
* Want to test how Eclipse displays diacriticals
* and how Java normalizes combining diacriticals
*
*
*/
public static void main(String[] args) {
/* 300/301 = grave/acute accent;
* 313/314 = soft/rough breathing mark;
* 342 = circumflex;
* 304 = macron
*/
String str =
"1[ἅ: α\u0301\u0314 α\u0314\u0301] " +
"2[ἄ: α\u0301\u0313 α\u0313\u0301] " +
"3[ἃ: α\u0300\u0314 α\u0314\u0300] " +
"4[ἂ: α\u0300\u0313 α\u0313\u0300] " +
"5[ᾁ: α\u0345\u0314 α\u0314\u0345] " +
"6[ἂ: α\u0300\u0313 α\u0313\u0300] " +
"7[ἇ: α\u0342\u0314 α\u0314\u0342] " +
"8[ᾱ̔ . α\u0314\u0304 α\u0304\u0314 ]";
printcombos(str);
}
private static void printcombos(String str) {
System.out.print("Raw string: ");
printStringAndCode(str);
System.out.println();
String str1 = Normalizer.normalize(str, Normalizer.Form.NFC);
System.out.print("NFC: ");
printStringAndCode(str1);
System.out.println();
String str2 = Normalizer.normalize(str, Normalizer.Form.NFD);
System.out.print("NFD: ");
printStringAndCode(str2);
System.out.println();
String str3 = Normalizer.normalize(str, Normalizer.Form.NFC);
System.out.println("NFC again: ");
printStringAndCode(str3);
System.out.println();
}
/* prints the character and its (unicode) code */
public static String printStringAndCode(String str) {
char[] c = str.toCharArray();
System.out.println(str);
StringBuilder out1 = new StringBuilder();
StringBuilder out2 = new StringBuilder();
for (char d : c) {
String cp = String.format("%x ", (int) d); // hex formatted codepoint of char d
out2.append(cp);
int len = cp.length() - 1;
String ch = String.format("%"+len + "s ", d);
out1.append(ch);
// insert extra space to make combining diacritics display alone (NON_SPACING_MARK)
// insert AFTER(?)
if (Character.getType(d) == 6) out1.append(" ");
}
out1.append("\n"); out2.append("\n");
String out = out1.append(out2).toString();
System.out.println(out);
return out;
}
}
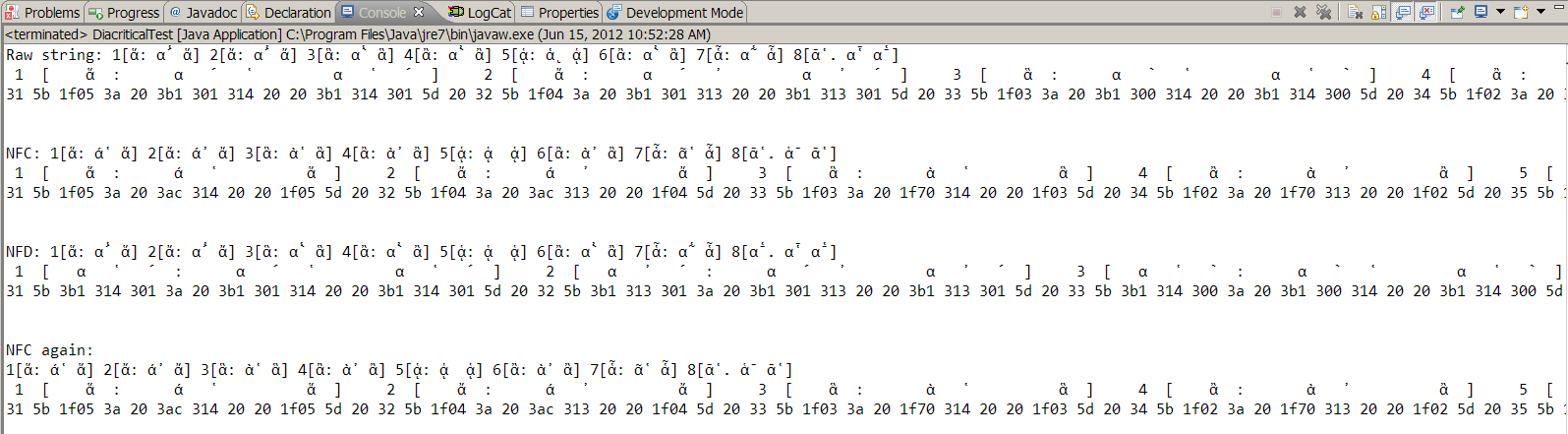
Here's the output, first as text, then as a graphic, in case the former doesn't work:
Raw string: 1[ἅ: ά̔ ἅ] 2[ἄ: ά̓ ἄ] 3[ἃ: ὰ̔ ἃ] 4[ἂ: ὰ̓ ἂ] 5[ᾁ: ᾁ ᾁ] 6[ἂ: ὰ̓ ἂ] 7[ἇ: ᾶ̔ ἇ] 8[ᾱ̔ . ἁ̄ ᾱ̔ ]
1 [ ἅ : α ́ ̔ α ̔ ́ ] 2 [ ἄ : α ́ ̓ α ̓ ́ ] 3 [ ἃ : α ̀ ̔ α ̔ ̀ ] 4 [ ἂ : α ̀ ̓ α ̓ ̀ ] 5 [ ᾁ : α ͅ ̔ α ̔ ͅ ] 6 [ ἂ : α ̀ ̓ α ̓ ̀ ] 7 [ ἇ : α ͂ ̔ α ̔ ͂ ] 8 [ ᾱ ̔ . α ̔ ̄ α ̄ ̔ ]
31 5b 1f05 3a 20 3b1 301 314 20 20 3b1 314 301 5d 20 32 5b 1f04 3a 20 3b1 301 313 20 20 3b1 313 301 5d 20 33 5b 1f03 3a 20 3b1 300 314 20 20 3b1 314 300 5d 20 34 5b 1f02 3a 20 3b1 300 313 20 20 3b1 313 300 5d 20 35 5b 1f81 3a 20 3b1 345 314 20 20 3b1 314 345 5d 20 36 5b 1f02 3a 20 3b1 300 313 20 20 3b1 313 300 5d 20 37 5b 1f07 3a 20 3b1 342 314 20 20 3b1 314 342 5d 20 38 5b 1fb1 314 20 2e 20 3b1 314 304 20 20 3b1 304 314 20 5d
NFC: 1[ἅ: ά̔ ἅ] 2[ἄ: ά̓ ἄ] 3[ἃ: ὰ̔ ἃ] 4[ἂ: ὰ̓ ἂ] 5[ᾁ: ᾁ ᾁ] 6[ἂ: ὰ̓ ἂ] 7[ἇ: ᾶ̔ ἇ] 8[ᾱ̔ . ἁ̄ ᾱ̔ ]
1 [ ἅ : ά ̔ ἅ ] 2 [ ἄ : ά ̓ ἄ ] 3 [ ἃ : ὰ ̔ ἃ ] 4 [ ἂ : ὰ ̓ ἂ ] 5 [ ᾁ : ᾁ ᾁ ] 6 [ ἂ : ὰ ̓ ἂ ] 7 [ ἇ : ᾶ ̔ ἇ ] 8 [ ᾱ ̔ . ἁ ̄ ᾱ ̔ ]
31 5b 1f05 3a 20 3ac 314 20 20 1f05 5d 20 32 5b 1f04 3a 20 3ac 313 20 20 1f04 5d 20 33 5b 1f03 3a 20 1f70 314 20 20 1f03 5d 20 34 5b 1f02 3a 20 1f70 313 20 20 1f02 5d 20 35 5b 1f81 3a 20 1f81 20 20 1f81 5d 20 36 5b 1f02 3a 20 1f70 313 20 20 1f02 5d 20 37 5b 1f07 3a 20 1fb6 314 20 20 1f07 5d 20 38 5b 1fb1 314 20 2e 20 1f01 304 20 20 1fb1 314 20 5d
NFD: 1[ἅ: ά̔ ἅ] 2[ἄ: ά̓ ἄ] 3[ἃ: ὰ̔ ἃ] 4[ἂ: ὰ̓ ἂ] 5[ᾁ: ᾁ ᾁ] 6[ἂ: ὰ̓ ἂ] 7[ἇ: ᾶ̔ ἇ] 8[ᾱ̔ . ἁ̄ ᾱ̔ ]
1 [ α ̔ ́ : α ́ ̔ α ̔ ́ ] 2 [ α ̓ ́ : α ́ ̓ α ̓ ́ ] 3 [ α ̔ ̀ : α ̀ ̔ α ̔ ̀ ] 4 [ α ̓ ̀ : α ̀ ̓ α ̓ ̀ ] 5 [ α ̔ ͅ : α ̔ ͅ α ̔ ͅ ] 6 [ α ̓ ̀ : α ̀ ̓ α ̓ ̀ ] 7 [ α ̔ ͂ : α ͂ ̔ α ̔ ͂ ] 8 [ α ̄ ̔ . α ̔ ̄ α ̄ ̔ ]
31 5b 3b1 314 301 3a 20 3b1 301 314 20 20 3b1 314 301 5d 20 32 5b 3b1 313 301 3a 20 3b1 301 313 20 20 3b1 313 301 5d 20 33 5b 3b1 314 300 3a 20 3b1 300 314 20 20 3b1 314 300 5d 20 34 5b 3b1 313 300 3a 20 3b1 300 313 20 20 3b1 313 300 5d 20 35 5b 3b1 314 345 3a 20 3b1 314 345 20 20 3b1 314 345 5d 20 36 5b 3b1 313 300 3a 20 3b1 300 313 20 20 3b1 313 300 5d 20 37 5b 3b1 314 342 3a 20 3b1 342 314 20 20 3b1 314 342 5d 20 38 5b 3b1 304 314 20 2e 20 3b1 314 304 20 20 3b1 304 314 20 5d
NFC again:
1[ἅ: ά̔ ἅ] 2[ἄ: ά̓ ἄ] 3[ἃ: ὰ̔ ἃ] 4[ἂ: ὰ̓ ἂ] 5[ᾁ: ᾁ ᾁ] 6[ἂ: ὰ̓ ἂ] 7[ἇ: ᾶ̔ ἇ] 8[ᾱ̔ . ἁ̄ ᾱ̔ ]
1 [ ἅ : ά ̔ ἅ ] 2 [ ἄ : ά ̓ ἄ ] 3 [ ἃ : ὰ ̔ ἃ ] 4 [ ἂ : ὰ ̓ ἂ ] 5 [ ᾁ : ᾁ ᾁ ] 6 [ ἂ : ὰ ̓ ἂ ] 7 [ ἇ : ᾶ ̔ ἇ ] 8 [ ᾱ ̔ . ἁ ̄ ᾱ ̔ ]
31 5b 1f05 3a 20 3ac 314 20 20 1f05 5d 20 32 5b 1f04 3a 20 3ac 313 20 20 1f04 5d 20 33 5b 1f03 3a 20 1f70 314 20 20 1f03 5d 20 34 5b 1f02 3a 20 1f70 313 20 20 1f02 5d 20 35 5b 1f81 3a 20 1f81 20 20 1f81 5d 20 36 5b 1f02 3a 20 1f70 313 20 20 1f02 5d 20 37 5b 1f07 3a 20 1fb6 314 20 20 1f07 5d 20 38 5b 1fb1 314 20 2e 20 1f01 304 20 20 1fb1 314 20 5d
|
|
|
| Re: Output of combining characters [message #887199 is a reply to message #886756] |
Sat, 16 June 2012 07:27 |
Dani Megert
Messages: 3802
Registered: July 2009 |
Senior Member |
|
|
On 15.06.2012 17:23, John Keck wrote:
> Thanks, Dani, for your reply. I appreciate it and look forward to the new version of Eclipse.
>
> I hope this isn't too off-topic for this thread, but I've just noticed another couple issues with Unicode and the Eclipse console--has to do with display of "combining characters" (and Unicode normalization).
Please file bug a bug report against Platform Debug and cc me.
Dani
>
> In this discussion, it's good to keep in mind the Unicode standard as described here: unicode.org/reports/tr15/. For ease of reference, here is Java 7's Normalizer class doc docs.oracle.com/javase/7/docs/api/java/text/Normalizer.html. (I still can't post links.)
>
> Below I've pasted some code that shows the trouble, along with its output. (Again, I'm using polytonic Greek.) The first glyph in each grouping (before the colon) is how the following two should look. You can see how putting the breathing mark first after the letter makes the second glyph turn out properly, whereas putting the accent first makes it turn out wrong. (The macron case is special, because there are no single glyphs with macrons and accents/breathing marks.)
>
> It appears to me that there are two closely related issues.
>
> The first issue is that Java's Normalizer.normalize method doesn't follow the Unicode standard in displaying combining diacritics in whatever order as the same unitary glyph (as is evident from the codepoints beneath).
>
> Quote:
>> That process logically starts at the front of the string and systematically checks it for pairs of characters which meet certain criteria and for which there is a canonically equivalent composite character in the standard. Each appropriate pair of characters which meet the criteria is replaced by the composite character, until the string contains no further such pairs. This transforms the fully decomposed string into its most fully composed but still canonically equivalent sequence.
>
> Failing to do that is no small breach! I'm reporting the bug to the Java folks.
>
> The second issue is that Eclipse shows some orderings of combining characters as if they were part of the next character, and not part of the preceding character (as they should be). This happens in the editor and not only in the console. This would appear to be a problem with the way Eclipse displays and not with Java itself (though Java's problem might be implicated)-- at very least the messy diacriticals should appear over the proper glyph.
>
> Actually, it might be impossible to disentangle the two issues for Eclipse. Nevertheless I would guess there is a workaround, as far as display is concerned, that would bypass Java's deficiencies. I could be wrong though.
>
> What do you think?
>
>
> import java.text.Normalizer;
>
> /* Compare to Unicode standard at unicode.org/reports/tr15/
> * Normalizer docs: docs.oracle.com/javase/7/docs/api/java/text/Normalizer.html
> *
> * NFD: 1 2 3 4[ἂ: á½°Ì“ ἂ] 5[á¾
|
|
|
Goto Forum:
Current Time: Thu Apr 25 06:02:03 GMT 2024
Powered by FUDForum. Page generated in 0.04077 seconds |
") ]
]  Search
Search Help
Help Register
Register Login
Login Home
Home





