pattern maxInteger(value : java Integer) {
value == java Integer::MAX_VALUE;
}New and Noteworthy
This page includes detailed information about the various releases of VIATRA, including major new features and notes of migration between various versions.
VIATRA 2.8
- Release date
-
2023-10-20
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.8.0
New and Noteworthy
VIATRA 2.8 is mainly a bugfix and maintenance release, the most important fix is an update for the pattern language tools to work with Guice 7.0, and thus compatibility with new dependency versions in SimRel 2023-09.
This version is the last version of the framework to work with Java 8. The next version of VIATRA will require Java 11, and will increase the required minimum versions of its dependencies, such as Eclipse Platform, Xtext accordingly.
VIATRA 2.7
- Release date
-
2022-03-16
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.7.0
New and Noteworthy
In addition to bugfixes, VIATRA 2.7 introduces two new language features: the capability to reference Java constants, and the use of eval unwinding.
For the first case, Java constants more precisely, public static final fields of Java classes from pattern specifications everywhere where variables or constant literals can be used.
Eval unwinding allows the processing of collections inside pattern bodies: by writing a specific eval expression with the marked with the unwind keyword, the returned Set is processed one by one (as separate matches). This feature is useful for extracting data from otherwise unstructured information, e.g. multiple URLs from a specific documentation field.
/* Match set are the tuples <value=2>, <value=3> and <value=5>*/
incremental pattern firstThreePrimes(value : java Integer) {
value == eval unwind (newHashSet(2, 3, 5));
}Migrating to VIATRA 2.7
As the eval unwinding feature introduces the unwind keyword to the language, metamodels providing features named the same need to be escaped.
VIATRA 2.6
- Release date
-
2021-09-15
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.6.0
New and Noteworthy
VIATRA 2.6 is mostly a bugfix and maintenance release, in addition to a few bugfixes most changes were related to the make sure VIATRA is correctly building in the current Eclipse build infrastructure. Furthermore, together with the release, the documentation of the CPS demonstrator application was restructured and a new transformation implementation was added.
VIATRA 2.5
- Release date
-
2020-12-16
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.5.0
Migrating to VIATRA 2.5
Updated logging configuration
In order to simplify log output, the default logging configuration was updated to remove unnecessary duplication and ensure everything uses the same configuration.
Old output:
0 [main] DEBUG org.eclipse.viatra.query.runtime.util.ViatraQueryLoggingUtil.org.eclipse.viatra.query.runtime.api.ViatraQueryEngine.1361289747 - Scaffold: patternbody build started for org.example.Range
146 [main] DEBUG org.eclipse.viatra.query.runtime.util.ViatraQueryLoggingUtil.org.eclipse.viatra.transformation.evm.api.Agenda.1525919705 - INACTIVE -- CREATE --> CREATED on org.eclipse.viatra.transformation.evm.api.Activation{atom=Match<org.example.Range>{"start"=0, "end"=30}, state=CREATED}New output:
0 [main] DEBUG org.eclipse.viatra.query.runtime.api.ViatraQueryEngine.1361289747 - Scaffold: patternbody build started for org.example.Range
272 [main] DEBUG org.eclipse.viatra.transformation.evm.api.Agenda@4567f35d - CREATED -- FIRE --> FIRED on org.eclipse.viatra.transformation.evm.api.Activation{atom=Match<org.example.Range>{"start"=0, "end"=30}, state=FIRED}The new configuration uses org.eclipse.viatra as a common prefix, thus it is possible to turn on all debug messages with a single configuration both for the VIATRA query and transformation runtimes, while it is still possible to do it selectively by using a more specific class names in the configuration. For users who use customized log4j configurations should update them to match the new scheme.
VIATRA 2.4
- Release date
-
2020-06-17
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.4.0
New and Noteworthy
Fixed Custom Java Support in Pattern Parser
The pattern parser infrastructure did not provide access to classes ouside the default classpath of the language runtime plugin, e.g. classes defined in plugins VIATRA does not depend on in Eclipse environments. To solve this issue, VIATRA 2.4 allows specifying a classloader for the pattern parser that gets used.
class PatternParserTest {
static def boolean checkName(String name) {
return name.startsWith("abc")
}
def void parse() {
val String pattern = '''
import "http://www.eclipse.org/emf/2002/Ecore";
import java org.eclipse.viatra.query.examples.PatternParserTest;
pattern javaCallTest(c : EClass) {
EClass.name(c, name);
check(PatternParserTest.checkName(name));
}
'''
val parser = new PatternParserBuilder()
.withInjector(new EMFPatternLanguageStandaloneSetup().createStandaloneInjector)
.withClassLoader(PatternParserTest.classLoader)
.build
val uri = URI.createFileURI("b.vql")
val results = parser.parse(pattern, uri)Migrating to VIATRA 2.4
VIATRA 2.4 removes support for older versions of its dependencies. When updating to VIATRA 2.4, ensure the required dependencies are updated to at least as follows:
-
Eclipse Platform 2019-06 or newer for the query editing support
-
Xtext version 2.20
-
This resulted in increased Guava minimum version 27.1.0
-
Eclipse Collections version 10.2
VIATRA 2.3
- Release date
-
2019-12-18
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.3.0
New and Noteworthy
Dependency Cleanup
Starting with version 2.3, both the query and transformation runtime works without relying on Guava. This allows avoiding various issues in standalone applications where other users may add a different Guava version than the one used by VIATRA itself. However, there are two important cases to consider:
-
The generated pattern matcher code may still depend on Guava if the queries themselves are including
checkorevalexpressions. For this reason, query projects are still generated with a Guava dependency; but they can be manually removed if unused. -
The infrastructure used to parse VQL files still requires Guava to function.
Code Generator Updates
Starting with this version, it is possible to disable query group generation (and the validation rules related to it) via customizing the language configuration module. The built-in standalone parser modules disables query group generation, but by default this functionality will stay enabled. The simplest way to rely on this updated generator is the following:
val String pattern = '''
import "http://www.eclipse.org/emf/2002/Ecore";
pattern b(c : EClass) {
EClass.name(c, "someName2");
}
'''
val parser = new PatternParserBuilder()
.withInjector(new EMFPatternLanguageStandaloneSetup().createStandaloneInjector)
.build
val uri = URI.createFileURI("b.vql")
val results = parser.parse(pattern, uri)Base Index Profiler
In order to measure the effects of VIATRA, version 2.3 includes a simple profiler for the base index itself that measures the time spent inside the adapters VIATRA uses to initialize the indexes and keep them up-to-date. Given the use of the profiler results in reduced performance, it is turned off by default, but can be enabled with the appropriate base index option.
Usage:
// Initialized profiling during model load
BaseIndexOptions options = new BaseIndexOptions()
.withIndexProfilingEnabledMode(ProfilerMode.ENABLED);
NavigationHelper baseIndex = ... ;
val profiler = new BaseIndexProfiler(baseIndex)
doTasks(baseIndex);
long count = profiler.getNotificationCount();
long time = profiler.totalMeasuredTimeInMS);Migrating to VIATRA 2.3
The viatra-query-runtime and viatra-transformation-runtime Maven modules do not add any version of Guava to the classpath anymore. If the actual project using VIATRA depends on Guava, it can be added as dependency.
VIATRA 2.2
- Release date
-
2019-06-19
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.2.0
New and Noteworthy
License change to EPL v2.0
Starting with version 2.2, VIATRA will use EPL v2.0 as its license. For details about this change look at https://www.eclipse.org/legal/epl-2.0/
Code Mining in Query Editor
VIATRA 2.2 introduces a set of code minings to provide extra inline information about the developed patterns. Currently, two information sources are enabled:
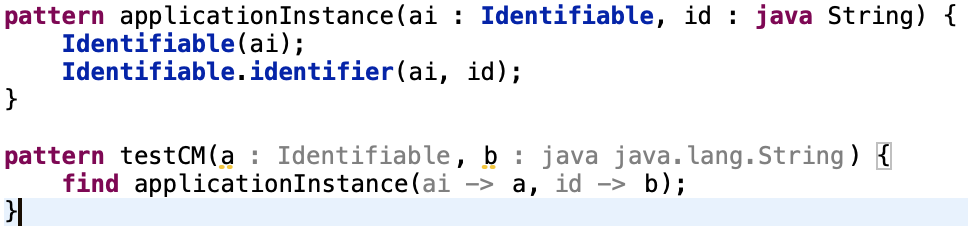
-
Inferred parameter types are displayed if missing. It is still recommended to always specify the parameter types (e.g. using the appropriate quick fixes to generate them), but displaying the missing values might still be helpful.
-
In case of pattern calls the names of the called parameters is also displayed, making it easier to understand more complex calls, especially ones with unnamed variables.
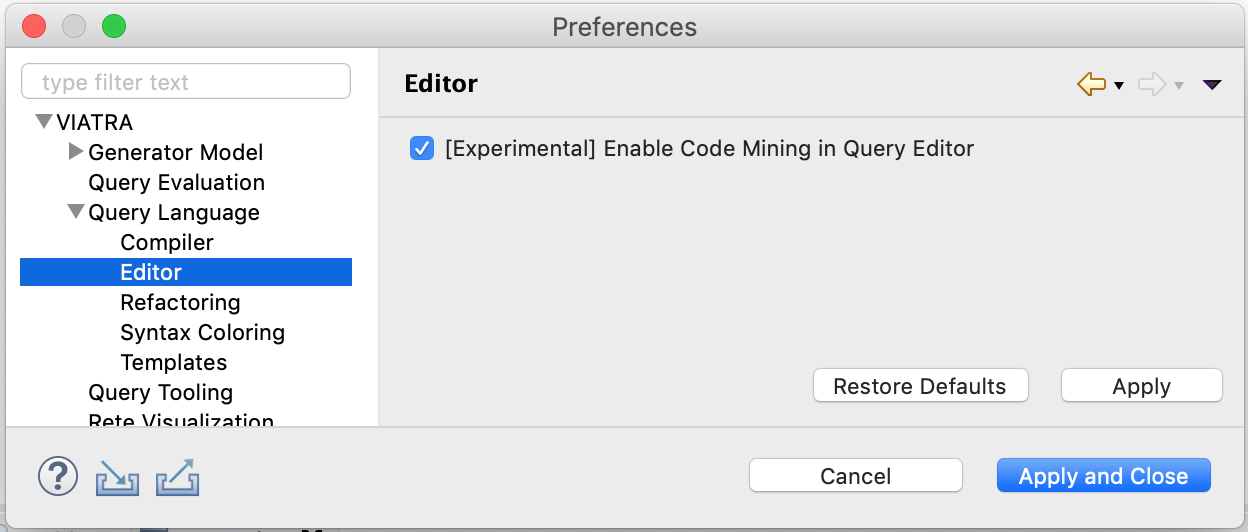
Code minings are only available if Eclipse Photon or newer is used; however, for version 2.2, we consider code minings experimental: in future versions we might update when minings are presented, both for performance and usability concerns. Because of this reason, code minings are by default turned off; in case of interest they can be turned on using an appropriate preference setting.
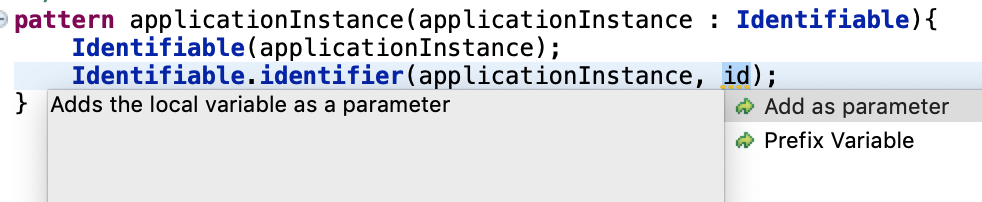
Easier Parameter Creation in Query Editor
To ease the modification previously created patterns, the editor makes it easier to convert existing local variables to parameters easily by appropriate content assist and quick fix-based enhancements.

Batch Transformation API Refresh
The batch transformation API was updated to provide better support for transformations that are almost exclusively controlled by data dependencies. The control flow for these transformations is usually trivial - the rules are executed one by one until there are no more matches left. This behavior is very similar to event-driven transformation with the main difference that these transformations are not executed on changes in the underlying model but are triggered manually.
The API received multiple small enhancements to support such transformations:
-
New statement variants were introduced that can handle transformation groups or all rules of the transformations.
-
A new statement type
hasCurrentwas added that returns whether a given set of rules can be fired. -
The handling of rule filters was updated to handle default filters that can be overridden by the transformation statements.
Migrating to VIATRA 2.2
Batch Transformation API
Prior to version 2.2, the filter settings of batch transformation rules were ignored by mistake, and only filters defined in statements were taken into account. In version 2.2, filters are handled the following way:
-
If neither the transformation rule nor the statement define a filter, all matches of the pattern are considered.
-
If either the transformation rule or the statement define a filter (but not both), that filter is used.
-
If both the transformation rule and the statement defines a filter, the filter defined by the statement overrides the default filter.
This behavior might change the behavior of existing transformations when transformation rule filters were defined but filterless statements were used: in such case, the default rule filters will be applied. In such cases, the unnecessary default filters should be removed; or if necessary, a new filter could be used to override the default filter when activating the rule.
API break in the query test framework
Prior to version 2.2, the main test class ViatraQueryTest had a field accessMap for storing the mapping of plain Java types to their handler objects for snapshot creation. In version 2.2, the encouraged way of providing this and further serialization information is in form of a single SnapshotHelper instance, initialized at the same time when the test case is created.
Details:
The field accessMap and the API method withClasses for updating the mapping have been removed. Instead, a SnapshotHelper can (and should) be provided while calling the first method, test, for test case initialization. Accordingly, test has a new signature now, which accepts a SnapshotHelper instance. For example, very often, a helper might be created on spot when the test case gets initialized:
ViatraQueryTest.test(SomeQuerySpecification.instance, new SnapshotHelper(accessMap, customEMFSerializerMap))VIATRA 2.1
- Release date
-
2018-12-19
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.1.0
New and Noteworthy
Graphical Query Editor
VIATRA 2.1 includes an experimental graphical editor for model queries based on Sirius. The queries created by the graphical editor are translated to the existing textual syntax, then handled with the existing runtime and IDE features. See the documentation page for details.
Other Language Features
The severity of missing variable types is increased to warning. The reason for this change is that explicitly declaring parameter types helps increases readability of patterns and helps precise error localization in case of type errors. However, to avoid breaking existing pattern declarations, such missing types are not considered as errors. However, in a future release such missing declarations might be considered as erroneous, so it is recommended to add the missing declarations (e.g. using the appropriate quick fix functionality).
Updated Headless Pattern Parser
The headless pattern parser component of VIATRA has been updated to be able to maintain an updatable set of query specifications, useful for integrating custom query evaluation functionality in modeling tools, where the queries are updated.
Migrating to VIATRA 2.1
Conflict Resolution between Transformation Rules
The default rule priority in InvertedDisappearancePriorityConflictResolver was changed in version 2.1 from 0 to 1. This change was motivated by the fact that in case of 0 priority additions and deletions would have the same priority that is in contrast with the goal of the resolver.
This is a breaking change as transformations using both priority '0' and '1' might change their internal behavior. To avoid this, it is recommended not to use priority '0' at all with this conflict resolver.
Updated transformation rule creation
Before version 2.1 the createRule methods of the classes BatchTransformationRuleFactory and EventDrivenTransformationRuleFactory were parameterless and the query specification was provided in the precondition method. This worked fine when using JVM-based languages with advanced type inference, such as Xtend or Kotlin for writing transformation, but when transformations were created in Java, it became cumbersome, as some type casting was required to initialize the rules properly.
To fix this, new createRule methods were created that expect the query specification input as parameters, thus replacing both the old createRule and precondition methods. To consolidate this API, the old calls are marked as deprecated, but are still available in VIATRA 2.1.
Changed hybridization behaviour in the Local Search Query Backend
To make behaviour more predictable, the default configuration of the Local Search query engine no longer allows hybrid pattern matching in conjuction with the incremental query backend across pattern calls, i.e. if the caller pattern is evaluated with LS, so will the callee pattern during the same matcher invocation. To enable hybrid matching, where the local search backend may request results of called patterns from the incremental backend (in case the callee is declared incremental pattern), use configurations that explicitly enable this, such as LocalSearchHints.getDefaultGenericHybrid().
Query Runtime UI Project introduced
To support reusing model connectors without tooling dependencies, the IModelConnector interface and all its uses have been moved to a new org.eclipse.viatra.query.runtime.ui plugin, and it has been renamed accordingly. All adapters provided by VIATRA were updated to provide the new interface, the few existing users should request instances of org.eclipse.viatra.query.runtime.ui.modelconnector.IModelConnector instead. The new implementation behaves in exactly the same way than before.
Facet Editor Integration Removed
VIATRA included for a few years a component to make sure our IDE features such as the Query Results view work well with the Facet Editor, originally provided by the EMF Facet project than later the MoDisco project. Given these editors are only used sparingly, and MoDisco leaves the simultaneous release, we have decided not to support this editor anymore.
VIATRA 2.0
- Release date
-
2018-06-27
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/2.0.0
New and Noteworthy
New Language Features
Starting with version 2.0 it is possible to calculate both the transitive closure and the reflexive transitive closure of the matches of a given pattern. Using this construct, the following two patterns are equivalent:
/** Old syntax, using transitive closure and multiple bodies */
pattern superclassOrSelf1(cl : Class, sup : Class) {
cl == sup;
} or {
find superclass+(cl, sup);
}
/** New syntax, note the '*' symbol in the find constraint */
pattern superclassOrSelf2(cl : Class, sup : Class) {
find superclass*(cl, sup);
}Another new feature is a simplified syntax for pattern calls if the called pattern only contains a single constraint. This is useful for easier negation, transitive closure calculation and aggregation as well. The following examples showcase where this feature can be used to reduce the complexity of existing patterns:
pattern simpleNegation(i : Identifiable) {
Identifiable(i); // not necessary, only added for readability
neg HostInstance(i); // note there is no `find` keyword here
}
pattern applicationTypeWithoutHostedInstance(at : ApplicationType, hi : HostInstance) {
neg HostInstance.applications.type(hi, at);
}
pattern countHostInstances(n : java Integer) {
n == count HostInstance(_);
}
pattern sumAvailableCPU(n : java Integer) {
n == sum HostInstance.availableCpu(_, #c);
}
pattern reachableStates(s1 : State, s2 : State) {
State.outgoingTransitions.targetState*(s1, s2);
}VIATRA 2.0 also introduces a new aggregator for calculating the average of numbers found in pattern matches. As an example, the following pattern can be used to calculate the average number of CPU values over a set of instances.
pattern avgCPU(n : java Double) {
n == avg find availableCPU(_, #v);
}
private pattern availableCPU(host : HostInstance, value : java Integer) {
HostInstance.availableCpu(host, value);
}Query Editing
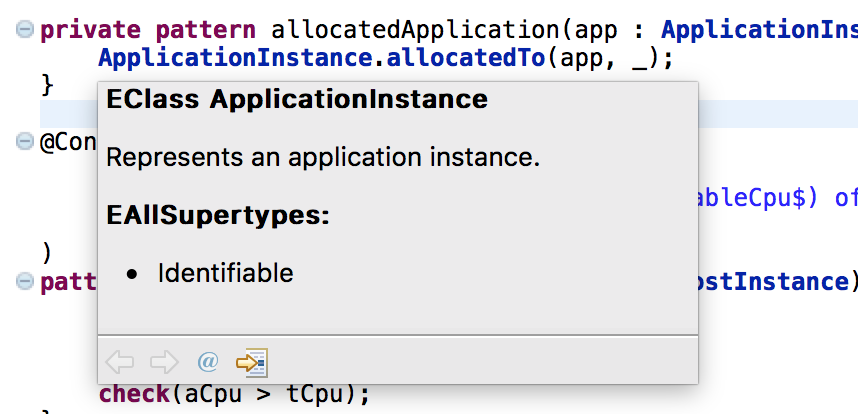
Hover help support was enhanced in VIATRA 2.0, specifically, a lot of elements now display hover that previously did not, including EClass and EReference types and variable references. Furthermore, calculating these hovers should be more efficient now, resulting in better performance in case of large number of patterns and/or complex metamodel hierarchies.


Updated pattern matcher API
The pattern matcher API was updated to rely on Java 8 features such as Streams and Optionals. This allows functional-style processing of the pattern matches.
String applicationIdentifiers = ApplicationTypesMatcher.on(engine)
.streamAllMatches()
.map(ApplicationTypesMatch::getAT)
// Calculate the identifier
.map(ApplicationType::getIdentifier)
//Provide a comma separated string of identifiers
.collect(Collectors.joining(", "));The VIATRA Query engine also supports setting the default search-based and default caching backend instances, allowing further customization of the runtime behavior of the engine. The new feature is available through the previously used ViatraQueryEngineOptions class.
Improved UI Support for Recursive Query Evaluation
For users who want to evaluate recursive queries via the Query Result View, we proudly report that the delete and rederive (DRED) evaluation mode can now be selected on the UI (specifically the Preferences page for the VIATRA Query Explorer).
p2 repository structure update
The removal of various features in this release made us reconsider the contents of our p2 repository. Previously we used a composite repository with all of our releases, but the features removed from version 2.0 show up in its earlier version that can be confusing. In order to handle this case better (and also for better performance), we have introduced a /latest p2 repository, and simplified the categorization instead.
With regards to these changes, the download page was also updated.
Migrating to VIATRA 2.0
Dependency updates
VIATRA 2.0 updates the minimum required version of sevaral of its dependencies. This allowed to clean up some code, but might require updating target requirements. The most important updates:
-
Minimum Java version: Java 8 (previously Java 7 was required)
-
Minimum Eclipse Platform version: 4.5 - Mars (previously version 3.7 - Indigo was used)
-
Minimum Xtext version: 2.12 (previously verion 2.9 was used)
Code generator updates
In VIATRA 2.0, the default behavior of query code generator was updated to reduce the number of generated files. This means, no .util package is generated, match and matcher code is generated as embedded subclasses, and match processors are not generated anymore.
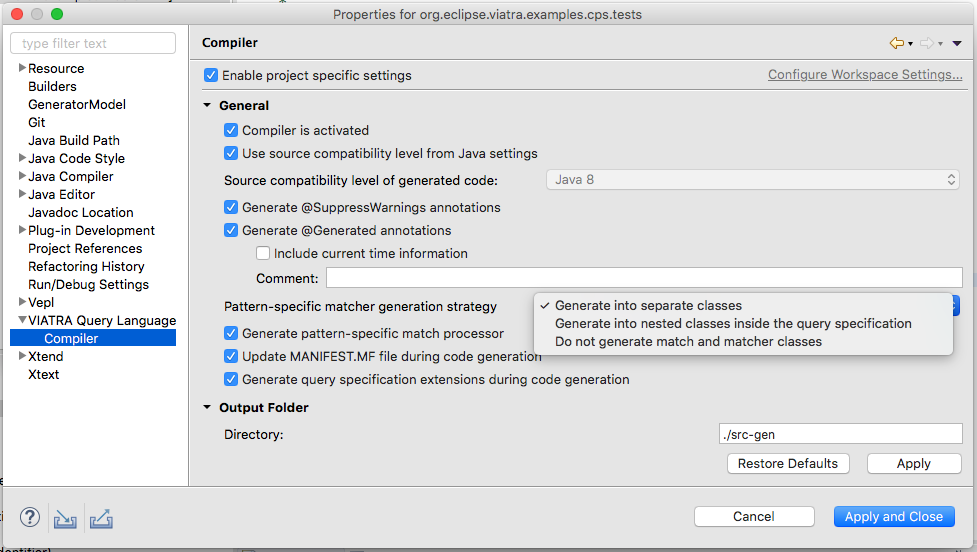
If necessary, the old generator behavior can be set by relying on the VQL Compiler settings.
Deprecated code removal
All code marked as deprecated has been removed from the codebase. Additionally, further components were removed
-
CEP has been removed
-
Xcore integration has been removed
-
C++ local search implementatation has been removed
-
Query-by-example has been removed
-
EVM-JDT integration has been removed
Removal of EMF-independent pattern language project
VIATRA 2.0 removes support for query languages not relying on EMF metamodels but retaining the structure of the VQL language. This feature is not used at all, but increases language maintenance costs significantly. Most users of the VIATRA framework should not be affected at all, but all related API changes are listed below.
-
The projects
org.eclipse.viatra.patternlanguage,org.eclipse.viatra.patternlanguage.uiandorg.eclipse.viatra.patternlanguage.testswere merged with their EMF-specific counterparts, respectivelyorg.eclipse.viatra.patternlanguage.emf,org.eclipse.viatra.patternlanguage.emf.uiandorg.eclipse.viatra.patternlanguage.emf.tests. -
The EMF models representing the ASTs have been merged into a simple EMF model, and moved to a new package:
-
The metamodel is available with the nsURI of
http://www.eclipse.org/viatra/query/patternlanguage/emf/PatternLanguage -
All generated classes are available from the package
org.eclipse.viatra.query.patternlanguage.emf.vql -
The generated class structure is the same as previous versions.
-
The extensions
org.eclipse.viatra.patternlanguage.annotationsandorg.eclipse.viatra.patternlanguage.whitelistwas moved into the patternlanguage.emf project, thus it’s IDs were updated toorg.eclipse.viatra.patternlanguage.emf.annotationsandorg.eclipse.viatra.patternlanguage.emf.whitelist, respectively. -
The classes
CorePatternLanguageHelperandEMFPatternLanguageHelperwere merged into a sharedPatternLanguageHelperclass.
Reduction of Guava uses
There were a few cases, where Guava types such as Functions or Predicates were visible in the API. In VIATRA 2.0, the trivial method calls were removed (to be handled via direct method references), while the remaining ones were replaced by the alternatives built-in to the Java 8 standard library. The following classes and methods were affected:
-
PQueries#parameterDirectionPredicate: returns Java 8 predicate -
PQueries#queryNameFunction: can be replaced by a method reference ofPQuery::getFullyQualifiedName -
PQueries#parameterNameFunction: can be replaced by a method reference ofPParameter::getName -
PQueries#queryOfReferenceFunction: can be replaced by a method reference ofIQueryReference::getReferredQuery -
PQueries#directlyReferencedQueriesFunction: returns a Java 8 function -
PQueries#queryStatusPredicate: returns a Java 8 predicate -
CorePatternLanguageHelper#getReferencedPatternsTransitiveaccepts a Java 8 predicate as a parameter -
ConflictSetIteratoraccepts a Java 8 predicate as a constructor parameter -
BatchTransformationStatements#fireUntilaccepts a Java 8 predicate as a condition -
RecordingJobdoes not record all created commands in a Table anymore; if the created commands are to be accessed, the RecordingJob should be initialized with a new command recorder instance that will be notified with each command after it was executed -
The
QueryResultMultimapandEVMBasedQueryResultMultimapclasses provided a Multimap interface for query matches; given they limited uses through the years, were simply removed.
Removal of unnecessary Xtend library dependencies
The transformation API used the Pair class from the Xtend standard library to rely the → (mapped to) operator to define filters based on name mappings. In version 2.0, the underlying code was changed to rely on Map.Entry classes from the Java standard library.
The following methods were affected by this change:
-
MatchParameterFilteraccepts an array of Map Entries instead of Xtend Pairs -
BatchTransformationStatementsaccepts an array of Map Entries instead of Xtend Pairs as parameters on various methods -
EventDrivenTransformationBuilder#filteraccepts an array of Map Entries instead of Xtend Pairs
To migrate your code, you can do one of the following:
If you are using Xtend code, and the "name" → value syntax does not compile anymore, add the following import declaration in the header: import static extension org.eclipse.viatra.transformation.runtime.emf.transformation.TransformationExtensions.
* If you are not using Xtend, or you don’t want to rely on the mapped to operator, simply instantiate these entries with the call new SimpleEntry<>("name", value).
Null parameters and return values
A few APIs in VIATRA returned null if no possible values could be found. Given VIATRA 2.0 depends on Java 8, such APIs were reworked to return Optional values instead.
The affected methods are the following:
-
PQueryHeader#getFirstAnnotationByName
-
CorePatternLanguageHelper#getFirstAnnotationByName
-
CorePatternLanguageHelper#getParameterByName
-
ViatraQueryMatcher#getOneArbitraryMatch
If the old behavior of returning null values is necessary the Optional.orElse call can be used, e.g. query.getFirstAnnotationByName("Constraint").orElse(null);
The constructor of the QueryEvaluationHint class was updated: previously it was instantiated with a Map of settings and an optional query backend (that could be null). Starting with version 2.0, the constructor does not accept null for the query backend, but provides an alternative constructor where it can be selected via a new enum which default backend should be selected instead. This change was necessitated by the new search- and caching backend settings in ViatraQueryEngineOptions.
IMatchProcessor removal
All usage of the IMatchProcessor interface was replaced with references to the Consumer type. Generated match processors (if enabled), also implement the Consumer interface.
Exception handling consolidation
Before VIATRA 2.0, the various APIs of the Query component threw a set of different checked exceptions: ViatraQueryException, ViatraBaseException and QueryProcessingException (and specialized versions of them). For version 2.0, these exceptions were updated in two ways:
-
All of them are now runtime exceptions, making it unnecessary to explicitly catch them. This makes it easier to put query processing code into lambda expressions, however, makes it entirely the developers responsibility to handle these exceptions as they happen.
-
All of them have now a common base exception called ViatraQueryRuntimeException - this class can be used anywhere in catch blocks if appropriate.
Dependency updates in query runtime
In this version, the dependencies of the org.eclipse.viatra.query.runtime plug-in had been reorganized. This should not cause any issues for users who deploy the query runtime with the org.eclipse.viatra.query.runtime.feature (in Eclipse environment) or the viatra-query-runtime feature (available from the Maven repository), as they will deploy all required plug-ins.
In other cases, if backend-specific code is used, the org.eclipse.viatra.query.runtime.rete and the org.eclipse.viatra.query.runtime.localsearch plugins might be necessary to add as additional dependencies to the developed code; and if necessary (e.g. in a non-Equinox OSGi environment), ViatraQueryEngineOptions#setSystemDefaultBackends() might need to be called with explicitly adding the corresponding entries.
API break in Transitive Closure Library
This API breaking change affects users of the org.eclipse.viatra.query.runtime.base.itc Java library for incremental transitive closure computation over custom graph data sources.
Not affected:
-
users of the transitive closure language element in vql.
-
users of
TransitiveClosureHelperproviding transitive closure of EMF references.
Details:
We have internally rewritten several algorithm and data structure classes of the transitive closure service to be more memory efficient. In particular, we changed the way how the multiset of incoming/outgoing graph edges is represented, as visible in interfaces IGraphDataSource and IBiDirectionalGraphDataSource (the graph observer interface is unchanged.).
The old interfaces (since 1.6) used java.util.Map with vertices as keys, and positive integers representing the count of parallel edges as values, while in the new version, multisets are encoded as org.eclipse.viatra.query.runtime.matchers.util.IMemoryView. For easier migration of legacy clients and implementors, conversions between the old and new representations are available at org.eclipse.viatra.query.runtime.matchers.util.IMemoryView#asMap and org.eclipse.viatra.query.runtime.matchers.util.IMemoryView#fromMap.
VIATRA 1.7
- Release date
-
2017-12-13
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/1.7.0
Optimizations in Query Runtime
The memory usage of the query engine was optimized in several ways during VIATRA 1.7, ensuring the new version requires up to 50% less stable memory to index its contents. This reduction was mainly achieved by using compact collections provided by the Eclipse Collections framework and creating custom tuple implementations.
Further changes also helped to reduce the temporary objects created during search-based pattern matching or provide faster responses in transformation by smarter preconditions checking.
Updated generated code structure
Traditionally, VIATRA generates four different Java classes for each query: (1) a query specification class, (2) a matcher class, (3) a match class and (4) a match processor class, each into a separate file. In case of projects with many pattern definitions, generating these files can get expensive.
In order to reduce the number of files generated, VIATRA 1.7 provides two new code generation option that creates only a single java file for each pattern:
-
Generate into nested classes: the match, matcher and match processor classes are generated as nested classes of the query specification; the query specification is renamed to have the same qualified name as the original pattern.
-
Do not generate match and matcher classes: no pattern-specific match, matcher and match processor classes are generated, but a generic implementation is reused. This mode is only recommended if the queries are not queried directly from code but used only in generic frameworks such as VIATRA Validation.
In VIATRA 1.7, for backward compatibility a third setting is used by default called Generate into separate classes that uses the previous structure. For VIATRA 2.0 it is planned to use nested classes as a default selection. This setting can be checked in the VIATRA Query Language compiler settings (available both as a global Eclipse Preference page or a Project Property page).
Additionally, the generation of pattern-specific match processors can be disabled if they are not used. This turns off the generation regardless whether it is generated into nested or separate classes.
CPS Demonstrator Application
VIATRA 1.7 includes a demonstrator application that can be used to see most features of the transformation framework in action. The application includes an example project and transformations included in editors.
-
The application can be downloaded for multiple platforms: Windows (64 bit), macOS, Linux (GTK 64 bit)
Additional issues
For a complete list of fixed issues for VIATRA 1.7 consult https://projects.eclipse.org/projects/modeling.viatra/releases/1.7.0/bugs
Migrating to VIATRA 1.7
One of the reasons for the better memory usage are the compact collections provided by Eclipse Collections framework. For this reason, all users of VIATRA has to have these classes available on the classpath. In case of dependencies managed via Maven or p2 this should require no additional steps, as this transitive dependency should be handled automatically.
VIATRA 1.6
- Release date
-
2017-06-28
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/1.6.0
Model Query Evaluation
VIATRA 1.6 provides a few new features that aim for better compatibility in a wider range of use cases. In general, VIATRA should work out of the box the same way it worked before, but there are some settings that allow a more finely tuned behaviour for certain situations.
Custom implementations of the EMF API (e.g. when generated code is manually modified) may violate EMF API contracts, and send incorrect notifications (e.g. duplicate model deletion events); similar situations can arise e.g. if there are custom EMF adapters that throw exceptions. In previous versions of VIATRA, this resulted in strange exceptions being thrown from the query backend. In version 1.6, the model indexer identifies most of these cases and provides a more precise error message describing what happens. It is also possible to tell the indexer to ignore (more specifically, log only) these incorrect notifications by turning the strict notification mode off, as shown below.
BaseIndexOptions options = new BaseIndexOptions().withStrictNotificationMode(false);
ResourceSet rSet = new ResourceSetImpl();
EMFScope scope = new EMFScope(rSet, options);
ViatraQueryEngine engine = ViatraQueryEngine.on(scope);In case of the query scope is set to a subset of the entire model (e.g only one EMF resource within the resource set), model elements within the scope of the engine may have references pointing to elements outside the scope; these are called dangling edges. Previous versions of VIATRA made the assumption that the model is self-contained and free of dangling edges; the behavior of the query engine was unspecified (potentially incorrect match sets) if the model did not have this property. In VIATRA 1.6, this behavior was cleaned up by adding a new indexer mode that drops this assumption, and (with a minor cost to performance) always checks both ends of all indexed edges to be in-scope. To avoid surprises, the new behaviour is used by default, but if necessary, the old behavior can be accessed by manually changing the corresponding base index option as below. For new code we suggest to use the option to drop the dangling-free assumption, as it provides more consistent and intuitive results in a lot of cases; in a future VIATRA release this will be the new default.
BaseIndexOptions options = new BaseIndexOptions().withDanglingFreeAssumption(false);
ResourceSet rSet = new ResourceSetImpl();
EMFScope scope = new EMFScope(rSet, options);
ViatraQueryEngine engine = ViatraQueryEngine.on(scope);The advanced query API now includes a feature that lets users temporarily "turn off" query result maintenance in the incremental query backend. During such a code block, only the base model indexer is updated, query results remain stale until the end of the block. The advantage is that it is possible to save significant execution time when changing the model in a way that partially undoes itself, e.g. a large part of the model is removed and then re-added.
AdvancedViatraQueryEngine engine = ...
engine.delayUpdatePropagation(new Callable<Void>() {
@Override
public Void call() throws Exception {
// perform extensive changes in model that largely cancel each other out
return null;
}
});Finally, VIATRA 1.6 includes the Delete and REDerive (DRed) algorithm as an experimental opt-in choice for evaluating recursive queries. Formerly, recursive queries were only fully supported under the condition that there can be circular dependencies between VQL patterns (or a pattern and itself), but not between individual matches of these patterns. Such circularity could lead to incorrect result maintenance after changes, even if all involved pattern calls are positive (simple find constraints). This restriction can now be relaxed by enabling DRed. With a small penalty in execution time, DRed guarantees correct result maintenance for arbitrary recursive pattern structures as long as all recursive calls are positive (i.e. no negation or aggregation along cycles of recursion). Note that for the very common special case of transitive closures, the dedicated language element (transitive pattern call) is still likely to be more efficient. DRed is still in an experimental phase, and is turned off by default; it can be manually enabled using the query evaluation hint ReteHintOptions.deleteRederiveEvaluation.
Code generator updates

For users targeting other environment than Eclipse plug-ins, it is now possible to disallow the updating of MANIFEST.MF and plugin.xml files. The bundle manifest is updated to ensure all packages that contain query specifications are exported, while plugin.xml files are used by the query specification registry to load all patterns during runtimes.
This setting is available as a workspace-level preference or a per-project setting. By default, these settings are turned on (so both files are updated on each build), maintaining compatibility with previous releases.
The other major change relates to the handling of private patterns. Given private patterns are not expected to be used outside calling them from patterns in the same vql file, the generated code does not need all the type-safe wrappers generated. However, to make private patterns testable using the query test API, the generated QuerySpecification classes were moved to a dedicated package were they could be made public without exporting them to all users of the query bundles.
In complex metamodels described in Ecore and genmodel files there are often cross-references between files with absolute or workspace-relative urls. When compiling VIATRA queries using the maven compiler, these urls cannot be resolved automatically. EMF uses URI converters to define a mapping between such source and target model elements. Starting with VIATRA 1.6, you can now specify the location of metamodels referred to via platform:/resource URIs with the uriMappings configuration element. See this wiki page for more details.
Query Test Framework updates
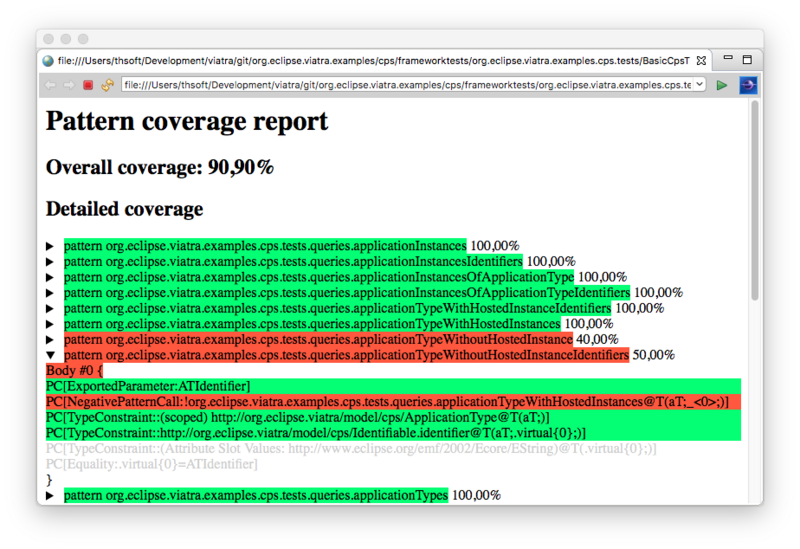
The query testing capabilities of VIATRA were extended to support a wider range of models and queries. This required new customization options for the test definition DSL, including support for non-default EMF resources as models and using more generic Java types in the query result snapshots. For a more detailed definitions of these features look at the documentation.
When testing your patterns, you can measure their test coverage (similar to what EclEmma does to Java code). This means you can see which constraints described in the patterns were used during the evaluation of the queries. The coverage can be reported as an HTML file which immediately shows which patterns need more testing. See the feature’s documentation for details.
Documentation updates

To make it easier to get started with VIATRA, a tutorial is added that presents an example for query and transformation development. In order to make the tutorial available for even more users, this documentation is also included in the platform help.
A few error messages in the query editor related to enumerable and non-enumerable references had been reported to hard to understand. In this version the error messages have been updated, and a quick fix was also added that updates a detailed explanation for the message. In future versions we plan to extend this support to make other error messages more understandable.
GEF5-based visualization

The graph-based components, specifically the Rete visualizer, Local search debugger and the graph visualization support of Viewers, were updated to rely on the latest GEF version 5.0 (available with Eclipse Oxygen). This results in an updated, JavaFX based display and further bugfixes available for these components by default.
Following the dependencies of GEF5 to use these features in the future, JavaFX (available from Java 8) and e(fx)clipse is required to be installed.
Complex Event Processing
VIATRA CEP has previously supported event parameters for atomic events only. From now on, complex events can also be parameterized, with full support for event composition. Furthermore, query events are parameterized as well, the parameters being directly derived from the parameters of the referenced query.
For example, see these sample events from here. Given the following query:
pattern hasContainer(contained: EClass, container: EClass) = {
EClass.eStructuralFeatures(container, ref);
EReference.containment(ref, true);
EReference.eType(ref, contained);
}We can define a parameterized query event and compose it into a parameterized complex event:
queryEvent addContainer(contained:EObject, container:EObject)
as hasContainer(contained, container) found
complexEvent addContainer2(cned:EObject, container1:EObject, container2:EObject) {
as (addContainer(cned, container1) -> addContainer(cned, container2))
}Design Space Exploration
VIATRA-DSE got a few incremental updates and bug fixes.
A new exploration algorithm called best-first search has been added that will eventually explore the whole design space (if it is finite of course) always continuing with the best possible choice. It can be instantiated with Strategies.createBestFirstStrategy(int maxDepth). It also has two configuration possibilities: continueIfHardObjectivesFulfilled() (so it won’t backtrack if a solution is found) and goOnOnlyIfFitnessIsBetter() (so it won’t explore equally good states immediately, only better ones). Currently it is implemented without multithreading.
The utility function DesignSpaceExplorer.saveModels() will save all solutions as EMF models. See API doc for details.
DepthHardObjective has been introduced that provides minimum and maximum depth criteria for solutions. Can be instantiated with Objectives.createDepthHardObjective().
Performance has been improved by a better backtracking mechanism: when an exploration strategy resets to an other trajectory for exploring other areas of the design space and if the new and the old trajectory start with the same rule applications, then it will only backtrack to their last common state.
Additional issues
For a complete list of fixed issues for VIATRA 1.6 consult https://projects.eclipse.org/projects/modeling.viatra/releases/1.6.0/bugs
Migrating to VIATRA 1.6
Recommended new indexing option for handling dangling edges
A a new filter option was introduced in this release regarding dangling edges (i.e. references pointing to objects outside the scope of the query engine). The old version made the assumptions that there are no such dangling edges whatsoever, and thus did not apply a filter to reject query matches that would involve such a dangling edge. This led to surprising results in some cases. For more predictable results and more straightforward semantics, we now allow the user to turn off this assumption, so that the appropriate checks will be performed (at a slight cost in performance).
For new code, and for any existing users that experienced problems with the unpredictability of dangling edges, we suggest to use the newly introduced option to drop the dangling-free assumption. In a future VIATRA release this will be the new default.
BaseIndexOptions options = new BaseIndexOptions().withDanglingFreeAssumption(false);
ResourceSet rSet = new ResourceSetImpl();
EMFScope scope = new EMFScope(rSet, options);
ViatraQueryEngine engine = ViatraQueryEngine.on(scope);API break in Transitive Closure Library
This API breaking change affects users of the org.eclipse.viatra.query.runtime.base.itc Java library for incremental transitive closure computation over custom graph data sources.
Not affected:
-
users of the transitive closure language element in vql.
-
users of
TransitiveClosureHelperproviding transitive closure of EMF references. -
users of the graph representation
org.eclipse.viatra.query.runtime.base.itc.graphimpl.Graph.
Details:
We have changed the way how the multiset of incoming/outgoing graph edges is represented in interfaces IGraphDataSource and IBiDirectionalGraphDataSource. The old interface used a java.util.List of vertices (parallel edges represented as multiple entries in the list), while the new interface uses java.util.Map with vertices as keys, and positive integers representing the count of parallel edges as values. The graph observer interface is unchanged.
Dependency changes related to Guava
In the Oxygen release train, multiple versions of Guava are available. In order to ensure VIATRA uses a single Guava version, all framework projects now import Guava with package imports, and set the corresponding ''uses'' constraints for all packages where Guava packages are exported.
For projects using the VIATRA framework everything should work as before. However, if there are issues with multiple Guava versions colliding, check whether any of your classes have Guava types on its API (e.g. check superclasses, parameter and return types; most common candidates are Predicate and Function instances). If any such case is available, the following steps are required to ensure the single Guava version:
-
Replace required bundle declarations of
com.google.guavawith appropriate package imports declarations. -
For each package export declaration that includes Guava classes on its API, add a uses constraints as follows:
org.eclipse.viatra.query.runtime.emf; uses:="com.google.common.collect",
For more details about the issue, and uses constraint violations in general, look at http://blog.springsource.com/2008/10/20/understanding-the-osgi-uses-directive/
VIATRA 1.5
- Release date
-
2016-12-21
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/1.5.0
Support for more number literals in query language
All number literals supported by Xtend (see documentation for details) are now directly supported by the VIATRA Query language.
pattern circleConstantDiameter1(c : Circle) {
Circle.diameter(c, 3l);
Circle.area(c, 9.42f);
}Performance improvements
Performance tuning with functional dependencies
Version 1.5 introduces greatly improved inference of functional dependencies among pattern variables, which may significantly influence query evaluation performance.
One can now also use the @FunctionalDependency annotation to manually specify additional dependency rules, in order to express domain-specific insight. See below for examples of the syntax:
// Here the first annotation is superfluous, as it is inferred automatically anyway
// The second annotation expresses valuable domain knowledge though
@FunctionalDependency(forEach = house, unique = street, unique = houseNumber)
@FunctionalDependency(forEach = street, forEach = houseNumber, unique = house)
pattern address(house: House, street: Street, houseNumber: java Integer) {
Street.houses(street, house);
House.number(house, houseNumber);
}
// Houses are either on a Street or on a Road, but not both at the same time;
// however Viatra is not smart enough (yet) to figure that out.
// In disjunctive patterns, all dependencies have to be specified manually!
@FunctionalDependency(forEach = house, unique = location)
pattern locatedOnThoroughfare(house: House, location: Thoroughfare) {
Street.houses(location, house);
} or {
Road.houses(location, house);
}More details available here.
Further optimizations in the incremental query evaluator
Constant values (more precisely constant-value filtering) within patterns are now handled more efficiently in many cases. In a proprietary code base, specifically for entire query packages where this feature is heavily used, we have observed a reduction between 15-30% in the memory footprint of Rete.
As an additional minor memory improvement, the results of eval/check expressions are no longer cached in Rete by default. In case some such expressions involve particularly expensive computations, one can restore the original caching behaviour either globally or on a per-pattern basis using the appropriate hint option introduced into the ReteHints class.
Remote debugging support added to the VIATRA model transformation debugger
The VIATRA model transformation debugger (introduced in VIATRA 1.3.0) has undergone a series of architectural and backend-related changes. The current, 0.15.0 version of the debugger now enables the user to connect to remote VIATRA model transformations, while maintaining the user experience introduced in the previous version. This way, model transformations running on remote JVM instances can be analysed much more straightforward way.
Using project dependencies in Query Maven plugin
You can now use ''useProjectDependencies'' in your configuration instead of adding metamodels as Maven dependencies. This is especially useful when the metamodels are not available as Maven artifacts.
<source lang="xml">
<configuration>
<!-- in addition to existing configuration -->
<useProjectDependencies>true</useProjectDependencies>
<configuration>
</source>For more details, see the following wiki page.
Migration to VIATRA 1.5
Internal API changes
VQL abstract syntax
The IntValue and DoubleValue EClasses were removed from the patternlanguage metamodel. Its functionality is provided by the new NumberValue EClass that references Xbase number literals.
Hint system compatibility break
The hint system was changed again in version 1.5. If you only used hints through the LocalSearchHints convenience class and the QueryEvaluationHint instances created by that class, then your existing code should remain compatible with version 1.5.
The main change is that query evaluation hints options are no longer identified by Strings, but rather by static instances of the type-safe QueryHintOption. Such hint options can be defined by query evaluator backends (see ReteHintOptions and LocalSearchOptions), and there can be options shared by multiple backends in the future.
Along with the change, the following previously deprecated methods and fields have been entirely removed:
-
LocalSearchRuntimeBasedStrategy.plan(PBody, Logger, Set, IQueryMetaContext, IQueryRuntimeContext, Map) -
IQueryBackendHintProvider.getHints(PQuery) -
IQueryBackendHintProvider.DEFAULT
Furthermore, the following classes and methods have been newly deprecated:
-
LocalSearchHintKeys -
QueryEvaluationHint(IQueryBackendFactory, Map) -
QueryEvaluationHint.getBackendHints() -
QueryPerformanceTest.getQueryBackendFactory()
VIATRA 1.4
- Release date
-
2016-09-30
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/1.4.0
Local search support during query evaluation
In version 1.4 the previously introduced local search support was greatly enhanced: several bugs and performance issues were fixed, while better integration is provided with the rest of VIATRA Query. In version 1.4 the planner and runtime is considered ready for production use, while future enhancements are still planned for future versions.
For this version, we already have performance benchmark that shows that local search based pattern matching can provide comparable performance during model transformation to Rete while requiring much less memory.
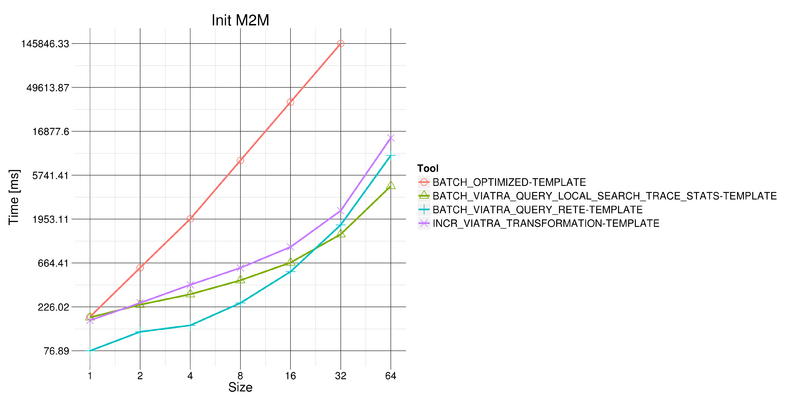
For more detailed documentation see http://wiki.eclipse.org/VIATRA/Query/UserDocumentation/API/LocalSearch
Query language improvements
Java type references
The query language now allows Java type constraints, both as parameter types and as variable type constraints in pattern bodies. The recommended use case is that query parameters that are a result of (a) an eval() or (b) aggregation expression should be annotated with their Java types. Java type names can be referenced by prefixing them with the keyword java, and of course namespace imports are available. So, for example, a query parameter may be typed as follows: no: java Integer. Usage basics are explained in the query language syntax guide.
pattern cpus(hi : HostInstance, no : java Integer) {
HostInstance.availableCpu(hi, no);
}Aggregators
In addition to the previously supported count keyword, there are now several new aggregators available (including sum, min and max, as well as an API for user-defined aggregators) to compute an aggregated value from matches of a called pattern. Usage basics are explained in the query language syntax guide.
pattern sumCPUs(s : java Integer) {
s == sum find cpus(_hi2, #_);
}Parameter direction support
Parameters can optionally be marked as incoming (in), outgoing (out). Incoming parameters must be bound when the pattern matcher initializes, while outgoing parameters must not. For backwards compatibility, unmarked parameters are neither incoming nor outgoing: they might be either bound or unbound when called. In version 1.4, parameter directions are ignored by the Rete engine, but used by the local search engine to decide the set of plans to create during matcher preparation.
pattern cpus(in hi : HostInstance, out no : java Integer) {
HostInstance.availableCpu(hi, no);
}Search engine declaration
Patterns can optionally be declared either local search-only (search) or Rete-only (incremental), providing hints to the runtime what pattern matcher should be initialized for this pattern. If undefined, the default hints of the engine is used (by default, Rete); and can be redefined using the advanced query engine API.
It is important to note that the Query Engine may override these declarations, e.g. if they cannot be executed.
search pattern minCPUs(n : java Integer) {
n == min find cpus(_hi1, #_);
}
incremental pattern sumCPUs(s : java Integer) {
s == sum find cpus(_hi2, #_);
}Query development environment improvements
We have graduated the completely new query development views that replace the Query Explorer. These views were introduced as part of VIATRA 1.3 (blog post with video) together with the Transformation Development perspective. For this release, we aimed to include all important features in the new views that were only available through the Query Explorer before (bug 499995 lists the relevant issues). If you already have the perspective opened, we recommend resetting it (right click on the perspective icon and select "Reset") as we have moved the views around to make more sense.
The most important new features are as follows:
-
Show location works for queries, matchers, matches and parameter values
-
Improved labeling in the tree (reuse domain specific icons for EMF model elements)
-
Match set filtering is possible through the Properties view

-
Drag-and-drop and double click for loading from Query Registry into Query Results
-
HiDPI icons for high-resolution, scaled displays.
-
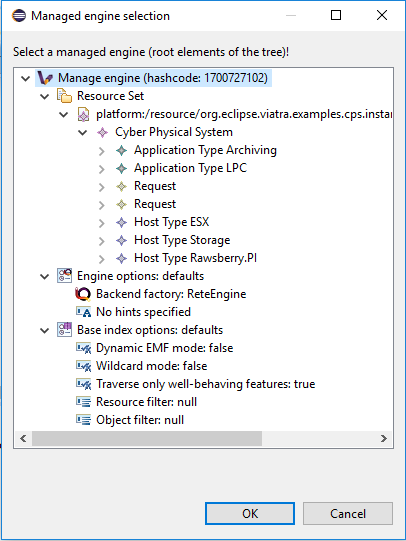
Load existing managed query engines into the Query Results view

-
Tree view for engine details including the model, engine options, base index options
-
Remove individual matchers from Query Results
Base indexer enhancements
In version 1.4, the Base Indexer was enhanced in a few ways:
-
Wildcard mode can be set up later than construction: an existing base indexer can now be asked to index everything in the model
-
Statistical indexing: instead of indexing model instances, Base can now only store model statistics. This is highly beneficial for local search, as for plan generation these statistics are very useful, but require less memory.
These enhancements are mostly useful in the query runtime (and were motivated by the requirements of local search), but are available for external uses as well.
Design Space Explorer enhancements
-
Method for setting the logging level:
OFF,WARN,BASIC,VERBOSE_STRATEGYandVERBOSE_FULL -
If the exploration is started asynchronously, it can be stopped by these methods: stopExploration(), stopExplorationAsync(), waitForTerminaition().
-
The evolutionary exploration strategy now can run on with multiple threads.
-
Depth first search strategy can continue exploration from a solution.
-
Minor performance enhancements.
-
Updated documentation on the wiki and also in the code: https://wiki.eclipse.org/VIATRA/DSE/UserGuide/API
Other issues
Version 1.4 also features a large number of under-the-hood changes, the most important is an updated hint system to enable fine-grained parametrization of the query engines. Usually, this change should be invisible for existing users; for possible migration issues see the Migration Guide below.
In total more, than 70 issues were fixed in this release, see https://projects.eclipse.org/projects/modeling.viatra/releases/1.4.0/bugs for details.
Migrating to VIATRA 1.4
Language updates
The query language introduced some new keywords, namely in, out, search and incremental. Variables and types with this name has to be escaped using the ^ symbol. On the opposite side, count is not a keyword anymore, so for future versions its references does not need to be escaped.
User interface updates
The query development UI is greatly updated. It might be worth checking out the new VIATRA perspective; for existing users of the perspective it may make sense to reset the perspective as it has been redesigned in version 1.4.
Internal engine API changes
LocalSearch internal API changes
The method LocalSearchPlanner.initializePlanner(PQueryFlattener, Logger, IQueryMetaContext, IQueryRuntimeContext, PBodyNormalizer, LocalSearchRuntimeBasedStrategy, POperationCompiler, Map<String,Object>) has been removed. The initialization is performed by the constructor, which has the following signature: LocalSearchPlanner(LocalSearchBackend, Logger, PlannerConfiguration).
Hint system refactor
In VIATRA 0.9 a preliminary hint system was introduced, where it was possible to provide hints for query evaluation. In version 1.4, this hint system was extended; however, VIATRA 1.4 cannot handle hints for queries generated with older versions of VIATRA. Please, regenerate your queries with 1.4 if you want to use hints.
Updated runtime context API
The IQueryRuntimeContext interface was extended with a few new methods, related to the usage of Base indexer. For the future, it is recommended that implementors do not implement this class directly, but rely on the new AbstractQueryRuntimeContext base class instead.
DSE API breaks
The three DSE plug-ins (dse.api, dse.base, dse.designspace) has been restructured to a single plug-in: org.eclipse.viatra.dse. Manifest files should be updated accordingly.
VIATRA 1.3
- Release date
-
2016-07-07
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/1.3.0
Neon compatibility
Previous versions of VIATRA were not 100% compatible the Eclipse Neon release for multiple reasons:
-
VIATRA 1.3 is the first version to be compatible with Xtext 2.10.
-
JFace data binding in Neon requires Java 1.8. However, in order to be compatible with older releases as well, VIATRA is compiled with older versions, but is ensured it is compatible with the current release.
However, VIATRA is still compatible with older platform versions up to the Indigo release.
Query development environment update
We have introduced a Transformation Development perspective to make it easier for VIATRA users to focus on developing queries and transformations. The perspective opens and lays out the most important views and contains view and new wizard shortcuts for all VIATRA related functionality.
We are also working on a new approach for query development that will replace the monolithic functionality of the current Query Explorer. You can install the separate feature VIATRA Query Browser (Incubation) to try out the new Query Registry and Query Results views.
-
Both views are connected with the Properties view to provide additional information about selected elements.
-
The Query Registry view shows all registered and workspace queries without the need to load them from the pattern editor directly.
-
Models and queries can be loaded into the Query Results view similarly to the Query Explorer.
Query by Example: create queries based on selected model elements
Query by Example (QBE), a new feature to ease query development, was included in this version. This new tool is primarily aimed at users who want to define queries, but are only familiar with the concrete syntax of a modeling language (i.e. the view presented through a graphical or textual editor), not the intricate details of its abstract syntax (metamodel, EPackgage).
Instead of manually writing .vql files, QBE allows the user to specify a query using an ''example'' - a selection of EMF instance objects highlighted in a model editor or viewer (both EMF tree editors and graphical editors are supported). The QBE tool will discover how the selected elements are related to each other in the model, and generate a .vql query that will find groups of model elements that are arranged similarly.
The newly introduced Query by Example view allows the user to control the process of (a) identifying elements selected in an open model file as the example, (b) fine-tuning the options of interpreting the example, and (c) exporting the resulting query to .vql code. The exported query can be loaded into the Query Explorer (or the new Query Results view) for evaluation and testing; if necessary, adjustments can still be made in the Query by Example view (e.g. adding or removing additional constraints).
The feature can be installed by selecting the VIATRA Query-by-Example (Incubation) addon from the VIATRA repository. For further details, check the paper from CMSEBA'14 Graph Query by Example.
Model transformation debugger prototype
VIATRA 1.3.0 now features the first prototype of a Model Transformation Debugger, which aims at helping the development and debugging of VIATRA-based model transformations. The debugger supports the following main features:
-
Allows the transformation developer to observe the inner state of the given VIATRA transformation and the associated model instances.
-
Displays the model instances associated with the transformation in a tree view with Properties support.
-
Displays the active activations of the model transformation using a contemporary Eclipse view.
-
Displays the precondition parameters of the next activation to be executed using the Eclipse Variables view.
-
-
Allows the transformation developer to control the execution of the VIATRA model transformation.
-
Supports the definition of various VIATRA transformation specific breakpoints, which integrate with the Eclipse Debug framework.
-
The user can control the execution of the transformation via the standard Eclipse Debugging controls (Step over (F6), Resume (F8)).
-
The user can define which transformation rule activaton should be executed next, overriding the default decision bade by the transformation.
-
-
Integrates with the Eclipse Debug framework.
It should be noted, in its current state, the debugger only handles VIATRA transformations that run in the same JVM as the debugger itself. Inter-JVM communication will be introduced in future versions.
A detailed user’s guide is part of the main VIATRA documentation and can be accessed via the following link: http://static.incquerylabs.com/projects/viatra/viatra-docs/ViatraDocs.html#_viatra_debugger
Other issues
Version 1.3 also features a large number of under-the-hood changes, the most important is a rewritten type inferrer that works largely the same, but provides more precise error messages. Usually, this change should be invisible for existing users; for possible migration issues see the Migration Guide below.
Another important area of such changes are enhancements for local search. A number of issues were fixed related to incorrect planning or plan execution in various areas; and for the next version further enhancements are planned in this area.
In total more, than 70 issues were fixed in this release, see https://projects.eclipse.org/projects/modeling.viatra/releases/1.3.0/bugs for details.
Migrating to VIATRA 1.3
Query specification registry
We have introduced a completely new Query Specification Registry and deprecated the old version.
Users of the org.eclipse.viatra.query.runtime.extensibility.QuerySpecificationRegistry class should read the JavaDoc for details on how to migrate to the new org.eclipse.viatra.query.runtime.registry.QuerySpecificationRegistry implementation.
Read http://wiki.eclipse.org/VIATRA/Query/UserDocumentation/API/Advanced#Query_specification_registry for details on the new registry.
Type inferrer in pattern language
The type inferrer of the VIATRA Query Language was rewritten; in most cases, it should behave exactly the same as the previous version, with the following differences:
-
If some data types, such as strings or integers, are returned, sometimes the old inferrer calculated Object as its return type. The new version calculates now the correct type. This behavior is presented by the calculation QualifiedName derived feature of UML Classifiers: in version 1.2, the name parameter returned Object, while in 1.3 it is correctly calculated as String.
-
The variables of patterns are required to have a single, identifiable type during type inference. If required, the closest common supertype is calculated, however, if that is not unique for a parameter, an error is thrown. The old inferrer implementation in case of complex inheritance hierarchies sometimes did not detect that this closest common supertype is not unique, but selected one. In such cases, the new inferrer throws an error, requiring the parameter type to be declared manually. For these cases, a quick fix is available to insert any of the possible types manually.
-
Known issue: in case of patterns with multiple check and eval expressions, the type inferrer is sometimes incapable of inferring the return types of eval expressions correctly inside other expressions. The error messages are a bit misleading, as the it is perfectly legit to enter an Object into a check expression, so only by an incorrectly typed expression is the issue detected.
The problem can be worked around using a typecast in the expression. See the following (artificial) example:
pattern t4_erroneous(n) {
check(n > 2); //Error 1: '> cannot be resolved'; Error 2: 'Check expression must return boolean'
n == eval(2);
}
pattern t4_fixed(n) {
check((n as Integer)> 2);
n == eval(2);
}VIATRA 1.2
- Release date
-
2016-04-28
- More information
-
https://projects.eclipse.org/projects/modeling.viatra/releases/1.2.0
Combined EMF-IncQuery and VIATRA
VIATRA 1.2 includes both the high-performance query engine of EMF-IncQuery and includes an event-driven transformation engine. This shared stack supports the development of various tasks, including batch and event-driven transformations, complex event processing and design space exploration concepts.
Having all elements in a single project allows a very tight integration between the various components, providing a better user experience.
Graduation of the transformation engine
In VIATRA 1.2 the transformation API supporting both batch and event-driven transformations have graduated: the API has been stabilized, usage documentation was added. For details, see https://wiki.eclipse.org/VIATRA/Transformation.
Other issues
Not counting the merge of EMF-IncQuery, VIATRA 1.2 is mainly a bugfix release, with 80+ different issues fixed, resulting a more stable environment to write model queries and transformations.
Migrating from EMF-IncQuery 1.1 to VIATRA 1.2
From version 1.2 EMF-IncQuery is merged into the Viatra project as Viatra Query. The merge involves the complete removal of org.eclipse.incquery namespace, thus making all code depending on EMF-IncQuery incompatible with Viatra Query API. Furthermore, during the merging the existing codebase was cleaned up, removing all existing deprecated code, and a few classes were renamed to be consistent with the new naming conventions.
The migrator tool
To ease the migration process, a migrator tool is included in Viatra 1.2 to reduce manual refactoring as much as possible.
Usage
The tool can be accessed in the 'Configure' context menu on Java/EMF-IncQuery projects where it is applicable.
-
Update Viatra Query Project: Migration of query projects (EMF-IncQuery 0.8.0-1.1.0)
-
Updates project dependencies
-
Updates query description files
-
Updates query specification extensions
-
Updates usage of EMF-IncQuery API
-
Important: this item is not available in projects that are already VIATRA Query projects
-
-
Replace EMF-IncQuery API Usage: Migration of Java and Xtend projects
-
Updates usage of EMF-IncQuery API
-
Safe to be called multiple times
-
Remaining manual tasks after migration
-
Maven builds are not migrated.
-
Deprecated API in EMF-IncQuery 1.1.0 are removed in 1.2.0. These API usages have to be migrated manually; look for the version 1.1 javadoc for hints on updating.
-
Deprecated pattern annotations and annotation parameters were removed from the language; they need either to be updated or removed manually from query definitions.
-
Generated plugin extensions other than query specifications are regenerated, but the old ones are not removed. These shall be removed manually.
-
The class name of static method calls and enum literals shall be renamed manually, e.g.
AdvancedIncQueryEngine.createUnmanagedEngine()→AdvancedViatraQueryEngine.createUnmanagedEngine()orIncQueryActivationStateEnum.UPDATED→CRUDActivationStateEnum.UPDATED -
Renamed methods and fields are not migrated by the tool: (incomplete list; in general references to IncQuery were changed; in case of compile errors look for similarly named methods in content assist)
-
Schedulers.getIQEngineSchedulerFactory→ `Schedulers.getQueryEngineSchedulerFactory^ -
ExecutionSchemas.createIncQueryExecutionSchema→ExecutionSchemas.createViatraQueryExecutionSchema -
IncQueryActivationStateEnum.APPEARED→CRUDActivationStateEnum.CREATED -
IncQueryActivationStateEnum.DISAPPEARED→CRUDActivationStateEnum.DELETED
-
A detailed list of changes
The changes done during the merging are documented in a spreadsheet; here we describe the main changes.
Project renaming
Projects from EMF-IncQuery projects were (a) moved from the org.eclipse.incquery to the org.eclipse.viatra namespace; and (b) subcomponents were introduced to split up into the new components of the VIATRA project to make it easier to understand. Projects with bold names in the spreadsheet had some non-trivial renames.
Class renaming
In addition to moving all projects into the org.eclipse.viatra namespace, a few classes were also renamed for several reasons:
-
All occurrences of EMF-IncQuery or IncQuery were renamed to meet the new project name.
-
Some classes in EVM related to match events were generalized into a CRUD-style event model. The semantic is the same as in previous versions, they were renamed only to suggest they can be reused in other domains.
Pattern language updates
The file extensions used by languages were updated from eiq to vql (VIATRA Query Language), and eiqgen to 'vqgen'. The migrator tool updates these file extensions automatically. Furthermore, a few deprecated annotations and annotation parameters were removed:
-
The
@PatternUIannotation is removed, use@QueryExplorerinstead. -
Instead of the
displayparameter of the@QueryExplorerannotation only thecheckedparameter is available. -
The
locationparameter of the@Constraintannotation is replaced with thekeyparameter.
VIATRA Databinding Addon
As detailed in the following bug, DatabindingAdapter and GenericDatabindingAdapter classes have been removed. Their functionality has been replaced by the MatcherProperties class. It has a set of static methods that enable the creation of observable values and value properties based on a query specification.