@Constraint(
key = {key1, sk1, sk2},
severity = "error",
symmetric = {sk1, sk2},
symmetric = {sp1, sp2},
message = "Some message $key1$ and $param$ and $sp2$"
)
pattern myPattern(key1, sk1, sk2, sp1, sp2, param) {...}Addons and Integrations
In addition to these components, VIATRA also provides a set of addons built over the query and transformation capabilities of VIATRA to (1) demonstrate the capabilities of the framework, (2) provide reusable features and (3) help integration to other editors and tools.
VIATRA Validation Framework
VIATRA provides facilities to create validation rules based on the pattern language of the framework. These rules can be evaluated on various EMF instance models and upon violations of constraints, and the processed, e.g. markers can automatically be created in the Eclipse Problems View.
Main concepts
Constraint specification
A constraint specification represents a well-formedness or structural validation rule that is specified with concepts from metamodels and can be evaluated over instance models.
E.g. a constraint specification is "A terminated data port cannot be the end of a port connection", where "terminated", "data port", "port connection" and "connection end" are concepts in the metamodel.
The constraint specification contains:
-
the converting mechanism for creating the location information for a violation
-
the format message that is used to create the message of a violation
-
the severity level (e.g. error, warning)
When constraint specifications are represented by VIATRA patterns, the corresponding query specification is stored.
Constraint
We differentiate between Constraint Specification that represents the validation rule and Constraint that represents an instance of a constraint specification on a validation engine.
Each constraint stores its specification and refers to a validation engine. It provides capabilities for:
-
listing the set of violations
-
registering listeners for notifications on the changes in the violation set and other events related to the life cycle of the constraint.
For constraints specified by VIATRA patterns, the corresponding matcher is stored.
Violation
A violation is set of model elements in an instance model that satisfy the specification of a constraint.
E.g. for the above constraint, a violation is a port P which is terminated and a port connection PC with "PC.end = P".
Each violation has:
-
a corresponding constraint
-
a location (one or more model elements that are relevant for the violation (e.g. the port and the port connection in the example)
-
a formatted message.
The violation should provide capabilities for registering listeners for notifications on life cycle events, e.g. a change in the message.
For violation of constraints based on VIATRA patterns, the match is also stored.
Validation Engine
A validation engine is responsible for managing the constraints existing in the scope of a VIATRA Query Engine (e.g. resource set) for a set of constraint specifications added to the validation engine.
The validation engine provides capabilities for
-
adding constraint specifications
-
listing the set of constraints
-
registering listeners for notifications on the changes in the constraint set and other events related to the life cycle of the validation engine.
Validation Manager
The validation manager is singleton that serves as a single entry point for using the validation that provides capabilities for
-
accessing the constraint specifications registered through extensions (see VIATRA
@Constraintannotation) -
initializing a new validation engine
Creating constraints from graph patterns
The validation framework provides a @Constraint annotation that is used to provide the extra information required to create constraints from the pattern definition.
The parameters of the constraint annotation
- key
-
(list of parameter names as strings) The keys of a constraint represent the parameters that together identify a given violation. Multiple matches of the same constraint pattern with the same parameter values for keys will be considered as a single violation. Non-key parameters can be accessed as tuples by the API.
- message
-
(format string): The message to display when the constraint violation is found. The message may refer the key variables between $ symbols, or their EMF features, such as in $keyParam1.name$.
- severity
-
(string) "info", "warning" or "error"
- targetEditorId
-
(string) An Eclipse editor ID where the validation framework should register itself to the context menu. Use * as a wildcard if the constraint should be used always when validation is started.
- symmetric
-
(possibly multiple list of parameter names as strings) Parameters listed as symmetric are considered to correspond to the same violation for matches where the values are in a different permutation. Symmetric parameters can be either keys or non-keys, mixing is not allowed.
Example annotation
Validation API
Once you specified your constraints with patterns and the @Constraint annotation, you can either use the marker based validation as before, or use the API to process violations yourself:
ResourceSet myModel; // already initialized
Logger myLogger; // Log4J logger, use Logger.getLogger(this.class) if you need one
IConstraintSpecification constraintSpec = new MyPatternNameConstraint0(); // generated for pattern called MyPatternName
ValidationEngine validationEngine = new ValidationEngine(notifier, logger);
IConstraint constraint = validationEngine.addConstraintSpecification(constraintSpecification);
validationEngine.initialize();
Collection<IViolation> violations = constraint.listViolations();
for(IViolation violation : violations) {
System.out.println(violation.getMessage());
Map<String, Object> keyMap = violation.getKeyObjects()
for(String key : keyMap.keySet()){
System.out.println("Key " + key + " is " + keyMap.get(key));
}
}
// you can filter violations
Collection<IViolation> filteredViolations = constraint.listViolations(new IViolationFilter(){
public boolean apply(IViolation violation){
return violation.getMessage().contains("MyFilterWord");
}
});
// you can add listeners on IConstraint to get notified on violation list changes
constraint.addListener(new ConstraintListener(){
public void violationAppeared(IViolation violation){
System.out.println("Appeared: " + violation.getMessage());
}
public void violationDisappeared(IViolation violation){
System.out.println("Disappeared: " + violation.getMessage());
}
});
// or on IViolations to get notified of message and parameter changes
violations.iterator().next().addListener(new ViolationListener(){
public void violationEntryAppeared(IViolation violation, IEntry entry){
System.out.println("Entry appeared: " + entry);
}
public void violationMessageUpdated(IViolation violation){
System.out.println("Message updated: " + violation.getMessage());
}
public void violationEntryDisappeared(IViolation violation, IEntry entry){
System.out.println("Entry disappeared: " + entry);
}
});
// you can also remove constraint specifications from an engine
validationEngine.removeConstraintSpecification(constraintSpecification);
// and dispose it when no longer needed
validationEngine.dispose();Derived feature support
Derived features in EMF models represent information (attribute values, references) computed from the rest of the model, such as the number of elements in a given collection or the set of elements satisfying some additional conditions. Such derived features can ease the handling of models significantly, as they appear in the same way as regular features. However, in order to achieve complete transparency for derived features, the developer must ensure that proper change notifications are sent when model modifications cause changes in the value of the derived feature as well. Finally, since the value of the derived feature might be retrieved often, complete recalculation of the value may impact application performance. Therefore, it is better to keep a cached version of the value and update it incrementally based on changes in the model.
Usually, developers who use derived features in EMF have to manually solve each of these challenges for each derived feature they introduce into their model. Furthermore, although the derived features almost always represent the result of a model query (including type constraints, navigation, aggregation), they are implemented as imperative Java code.
In order to help developers in using derived features, VIATRA supports the definition of model queries that provide the results for the derived feature value calculation and includes out-of-the-box change notification and incremental maintenance of results. Additionally, the automatic generation of the Ecore annotations or glue code between the EMF model code and VIATRA offers easy integration into any existing EMF application.
VIATRA supports the definition of efficient, incrementally maintained, well-behaving derived features in EMF by using advanced model queries and incremental evaluation for calculating the value of derived features and providing automated code generation for integrating into existing applications.
Main scope of query-based features
-
Integrate model query results into EMF applications as structural features
-
Replace low performance derived feature implementations with incrementally evaluated model queries
-
Provide a flexible interlinking method for fragmented models
-
Support declarative definition of high-performance computed features with automatic code generation and validation
Well-behaving structural features
The incremental approach of the VIATRA queries relies on change notifications from every object and every feature in the model that is used in the query definitions. Therefore, a regular volatile feature that has no field, therefore there it does not store the current value of the feature and usually does not send proper change notifications (e.g. SET oldValue to newValue). Such features are ignored by VIATRA, unless there is an explicit declaration, that the feature implementation sends proper change notifications at all times. These are called well-behaving structural features.
If your application uses volatile (and often derived) features, you provide proper notifications for them and would like to include them in query definitions, you can explicitly tell VIATRA that the feature is well-behaving. There are two ways to do this:
-
extend the
org.eclipse.viatra.query.runtime.base.wellbehaving.derived.featuresextension point as described here -
provide a surrogate query, see later
-
register your feature directly into the
org.eclipse.viatra.query.runtime.base.comprehension.WellbehavingDerivedFeatureRegistryusing the variousregisterXmethods. Warning: you must call this method before executing any queries (i.e. before the firstgetMatcher()orgetEngine()call), since VIATRA checks the registry when it traverses the model.
Query-based Features
For demonstration, we will use the BPM metamodel from the examples repository.
Other examples include the Simulink model in Massif uses query based features for supporting library blocks, model references, port filtering and many more.
User documentation
VIATRA only provides the back-end for derived features, the developer must define the feature itself in the metamodel first. Once that is complete, the developer creates the query in a regular VIATRA query project in a query definition file and adds a specific annotation with the correct parameters to have the derived feature implementation generated. These steps are detailed in the following:
Definition of the derived feature
-
In the Ecore model (.ecore file), create the desired EAttribute or EReference in the selected EClass and set the name, type and multiplicity information correctly.
-
Use the following configuration for the other attributes of the created EStructuralFeature:
-
derived = true (to indicate that the value of the feature is computed from the model)
-
changeable = false (to remove setter methods)
-
transient = true (to avoid persisting the value into file)
-
volatile = true (to remove the field declaration in the object)
-
-
In the Generator model (.genmodel), right-click on the top-level element and select Reload, click Next, Load, and Finish to update the Generator model with the changes done in the Ecore model.
-
Right-click on the top-level element and select Generate Model Code to ensure that the getters are properly generated into the EMF model code. You can regenerate the Edit and Editor code as well, though those are not necessary here.
Definition of the model query
-
Create a VIATRA query project and query definition (.vql) file as described in the cheat sheet or this tutorial.
-
Make sure that you imported your metamodel into the query definition. Create the VIATRA generator model, if necessary (.vqlgen file).
-
Make sure that the project containing the Ecore model or generated code is in the same workspace as the VIATRA query project.
-
Create the query corresponding to your derived feature. For example, the tasks corresponding by identifiers to a given job feature would look like this:
package org.eclipse.viatra.examples.bpm.queries.system
import "http://process/1.0"
import "http://system/1.0"
@QueryBasedFeature(feature = "tasks")
pattern JobTaskCorrespondence(Job : Job, Task : Task) = {
Job.taskIds(Job,TaskId);
Task.id(Task,TaskId);
}
-
When you save, the VIATRA query builder runs automatically and places the setting delegate annotations in the Ecore model.
-
If new query-based feature queries were introduced or the fully qualified name of the pattern for a given feature has changed, the EMF Generator must be invoked. This is needed since the generator uses the setting delegate annotations to create the model code.
Note that the first parameter of the pattern is the source of the derived feature and the second is the target. Although not mandatory, is is good practice to use the (This : EClass, Target) format to ease understanding. The @QueryBasedFeature annotation indicates to the code generator that it should create the setting delegate annotations in the Ecore model.
Saving the query definition initiates the code generation. After it completes, you can open the Ecore model to ensure that the new annotations were correctly created. Note that a well-behaving derived feature extension is also generated into the plugin.xml of the VIATRA Query project to indicate that the given derived feature correctly sends change notifications if the project is loaded.
Once the annotations are generated and the EMF Generator is invoked, you can use the derived features by including the VIATRA Query project into your runtime together with the model project.
Annotation parameters
The @QueryBasedFeature annotation uses defaults for each possible parameters, which allows developers to avoid using any parameters if the query is correctly written.
In short, parameters are not needed, if the following conditions are satisfied:
-
The name of the pattern is the same as the name of the derived feature (comparison uses String.equals())
-
The first parameter is the defining EClass and its type is correctly given (e.g. This : Course)
-
The second parameter is the target of the derived feature
-
The derived feature value is a single EObject or a collection of EObjects
If the derived feature and its query does not satisfy the above conditions, the following parameters can be used in the annotation:
-
feature ="featureName"(default: pattern name) - indicates which derived feature is defined by the pattern -
source ="Src"(default: first parameter) - indicates which query parameter (using its name) is the source EObject, the inferred type of this parameter indicates which EClass generated code has to be modified -
target ="Trg"(default: second parameter) - indicates which query parameter (using its name) is the target of the derived feature -
kind ="single/many/counter/sum/iteration"(default: feature.isMany?many:single) - indicates what kind of calculation should be done on the query results to map them to derived feature values
Common issues
Code generation fails for derived feature query
Ensure that the .ecore file is available and writeable in the same workspace as the VIATRA query project with the query definitions.
Multiple results for a query used in a single (upper bound = 1) feature
If you define a query for a single feature that returns multiple results for a given source model element, the value of the derived feature will in most cases be the value from the last match that appeared. However, it is possible to change the values in a way that the feature will have no value, even though it might have exactly one. Therefore, it is important to define the queries for the feature in a way that only one result is possible. You can either make assumptions on your models and use other ways to ensure that there is only one match, or you can explicitly declare in the pattern, that it should only match once for a given source element. Additionally, you can use the Validation framework of VIATRA to create feedback for the user when the query would have multiple results indicating that the model is invalid.
The following is an example for a validated, ensured single feature:
@QueryBasedFeature
pattern singleFeature(This : SourceType, Target : TargetType){
find internalQuery(This, Target);
1 == count find internalQuery(This, Target);
}
private pattern internalQuery(This : SourceType, Target : TargetType){
// actual query definition
}
@Constraint(location = "This", severity = "error",
message="Multiple values for $This.name$.singleFeature!")
pattern singleFeatureInvalid(This : SourceType){
1 < count find internalQuery(This, _Target);
}Overview of the implementation
To support query-backed features captured as derived features, the outputs of the VIATRA query engine need to be integrated into the EMF model access layer at two points: (1) query results are provided in the getter functions of derived features, and (2) query result deltas are processed to generate EMF Notification objects that are passed through the standard EMF API so that application code can process them transparently.
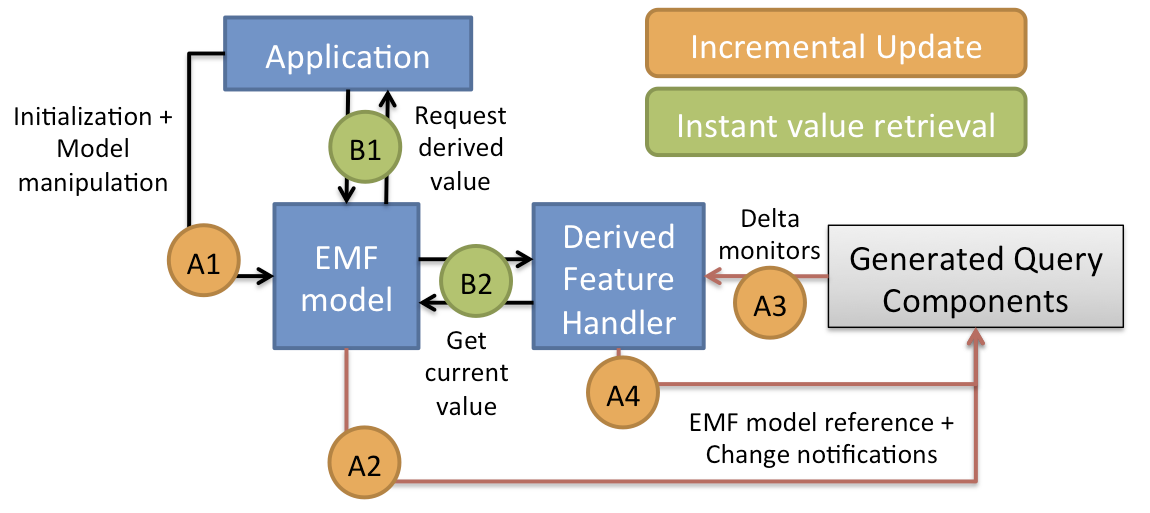
The application accesses both the model and the query results through the standard EMF model access layer — hence, no modification of application source code is necessary. In the background, our novel derived feature handlers are attached to the EMF model plugin that integrate the generated query components (pattern matchers). When an EMF application intends to read a soft link (B1), the current value is provided by the corresponding handler (B2) by simply retrieving the value from the cache of the related query. When the application modifies the EMF model (A1), this change is propagated to the generated query components of VIATRA along notifications (A2), which may update the delta monitors of the handlers (A3). Changes of derived features may in turn trigger further changes in the results sets of other derived features (A4).
Using setting delegates
The Query-based features relies on setting delegates instead of overwriting the generated code. Setting delegates are the recommended way of integrating derived feature computation into EMF models. This means that only the Ecore file is modified when the pattern definitions are changed, however that the code generation from the genmodel will have to be invoked as well.
To set up setting delegates, the generator automatically puts annotations on the EPackage and EStructuralFeatures
-
on the EPackage, to declare which setting delegates to use:
<eAnnotations source="http://www.eclipse.org/emf/2002/Ecore"> <details key="settingDelegates" value="org.eclipse.viatra.query.querybasedfeature"/> </eAnnotations>
-
on the EStructuralFeature which is a query-based feature:
<eAnnotations source="org.eclipse.viatra.query.querybasedfeature"> <details key="patternFQN" value="querypackage.patternName"/> </eAnnotations>
The setting delegate factory is registered by the query-based feature runtime plug-in and EMF will use the factory to create the setting delegate for query-based derived features.
Surrogate queries for derived features
Query-based features capture the definition of well-behaving derived features of Ecore models by queries, and allow the use of such derived features in the body of other queries. But when an Ecore model is not allowed to be modified, you could not use derived features in query bodies in the past. EMF-IncQuery 1.0.0 introduced surrogate queries for derived features, where a derived feature used in a query is replaced by a subpattern call during query execution time (runtime).
Usage
@Surrogate
pattern superClass(self : Classifier, super : Classifer) {
Classifier.generalization(self, generalization);
Generalization.general(generalization, classifier);
}In order to create a surrogate query, simply add a @Surrogate annotation for a pattern and the generator will take care of defining the correct extension points. When the query plug-in is included in the host, the VIATRA Query runtime will automatically replace path expressions including the feature with a subpattern call. In addition, if the plug-in is available in the host or target platform, the warning for a derived feature usage will be different (instead of warning about not representable feature, it will include the fully qualified name of the surrogate query). So the following will work correctly during runtime:
pattern superClassWithName(self : Classifier) {
Classifier.superClass(self, superClass);
Classifier.name(superClass, "mySuperClass");
}Important information on developing surrogate queries
Surrogate queries defined in workspace projects are not yet visible to the Query Explorer, so loading queries that use those derived features will result in incorrect match results. If you want to try such queries in the Query Explorer, do the following:
-
If the surrogate query definition and the pattern using it are in different projects, simply start a runtime Eclipse where at least the defining query is included.
-
If the surrogate query definition and the pattern using it are in the same project, simply use a subpattern call (find) instead.
Example
The UML metamodel used in EMF-UML contains a large number of derived features (see UML support for VIATRA for details), most of which are not well-behaving, which significantly complicated the definition of patterns over UML models in the past.
Consider the following pattern:
pattern superClassWithQualifiedName(self : Classifier) {
Classifier.superClass(self, superClass);
Classifier.qualifiedName(superClass, "my::favorite::package::SuperSuperClass");
}Both Classifer.superClass and NamedElement.qualifiedName are derived features, therefore
-
the pattern editor will display a warning about these features are not amenable to incremental evaluation;
-
the runtime will index the value of these features and no matches will be returned.
Since the value of these feature can be computed from the rest of the model, users often manually defined helper patterns, for example:
pattern superClass(self : Classifier, super : Classifer) {
Classifier.generalization(self, generalization);
Generalization.general(generalization, classifier);
}
pattern superClassWithQualifiedName(self : Classifier) {
find superClass(self, superClass);
Classifier.qualifiedName(superClass, "my::favorite::package::SuperSuperClass");
}However, this approach has several drawbacks:
-
Reinventing the wheel: derived features are redefined over and over again.
-
Error-prone definition: you can easily overlook some detail in the computation and get unexpected results.
-
Disallowed use in patterns: the derived feature cannot be used directly in other pattern bodies, you need to explicitly call the helper pattern (by the ''find'' construct).
Surrogate queries are introduced to help overcome these issues.
Technical details
Surrogate query support includes the @Surrogate annotation in the pattern editor, the corresponding code generator fragment, the runtime loading and usage of surrogate query registry, the runtime replacement of derived feature usage in queries. However, when running outside of Eclipse, some additional setup is required.
Definition of surrogate queries
The @Surrogate annotation has a single, optional parameter feature which specifies the name of the EStructuralFeature that the surrogate query replaces. If omitted, the name of the pattern must match the name of the feature. The first parameter of the pattern is always the source, and the second parameter is the target.
Let us assume you want to surrogate a derived feature someExternalModelFeature in EClass ExternalClass with type OtherExternalClass.
You can choose between:
@Surrogate(feature = "someExternalModelFeature")
pattern mySurrogatePattern(this : ExternalClass, target : OtherExternalClass) {
[...] // pattern body
}and:
@Surrogate
pattern someExternalModelFeature(this : ExternalClass, target : OtherExternalClass) {
[...] // pattern body
}The annotation is defined by the querybasedfeatures.runtime plug-in together with a validator (also provided by the same plug-in), which checks several things:
-
the pattern has exactly two parameters
-
the feature specified by the pattern name or the parameter of the annotation exists in the source EClass
-
the target type of the feature is compatible with the second parameter of the pattern
-
there is only one Surrogate annotation for a pattern or each of them define different features
The code generator fragment is defined by the querybasedfeatures.tooling plug-in and it simply creates an extension for the surrogate query extension point in the plugin.xml:
<extension id="extension.surrogate.mySurrogates.mySurrogatePattern" point="org.eclipse.viatra.query.patternlanguage.emf.surrogatequeryemf">
<surrogate-query-emf class-name="ExternalClass" feature-name="someExternalModelFeature" package-nsUri="external.ecore.uri"
surrogate-query="org.eclipse.viatra.query.runtime.extensibility.PQueryExtensionFactory:mySurrogates.MySurrogatePatternQuerySpecification"/>
</extension>Runtime behavior
During runtime, the surrogate queries are loaded into a surrogate query registry (defined in the ''runtime.matchers'' plug-in) by reading the extension registry of Eclipse. When a given pattern is loaded into an engine, path expressions including derived features with defined surrogate queries are replaced in the PSystem representation.
This means that the surrogate queries are only used if they are available and registered. Additionally, for query backends that can handle non well-behaving derived features (e.g. the local search backend), this rewriting is skipped.
Usage outside of Eclipse
Since the extension registry is not available when running outside of Eclipse, users have to manually register surrogate queries before they can be used for query evaluation.
In addition to basic infrastructure, the following setup is required for each surrogate query:
SurrogateQueryRegistry.instance().registerSurrogateQueryForFeature(
new EStructuralFeatureInstancesKey(ExternalPackage.Literals.EXTERNAL_CLASS_SOME_EXTERNAL_MODEL_FEATURE),
MySurrogatePatternQuerySpecification.instance.getInternalQueryRepresentation());See the VIATRA UML standalone setup for an example.
Displaying Query Results in the User Interface
As far as the visualization of VIATRA pattern matching results is concerned, the VIATRA framework provides two approaches:
-
VIATRA Data Binding Addon: Using this addon, VIATRA pattern matches can be directly incorporated in newly developed applications that utilize JFace Data Binding.
-
VIATRA Viewers Addon: The VIATRA Viewers component helps developing model-driven user interfaces by filling and updating model viewer results with the results of model queries. The implementation relies on (and is modeled after) the Event-driven Virtual Machine and JFace Viewers libraries.
VIATRA Data Binding
VIATRA provides a simple data binding facility that can be used to bind pattern matches to UI elements. The feature is mainly intended to be used to integrate VIATRA queries to newly developed user interfaces. In order to utilize this functionality, the source patterns need to be annotated, and the used UI components need to be bound to the Observables provided by the data binding API. In the following sections an example is shown which uses VIATRA Data Binding.
Required annotations
-
@ObservableValue: allows the developer to customize the appearance of a match. It defines an observable value (as defined in JFace Data Binding) which can be bound to an Eclipse/JFace UI.
-
name (String): the name of the parameter
-
expression (String): the attribute to be observed definition without '$' marks. For example
@ObservableValue(name = "id", expression = "host.identifier") -
labelExpression: this annotation makes it possible to create observable string properties, which are useful when presenting relations between objects inside a JFace viewer component.
-
@ObservableValue(name = "id", expression = "host.identifier")
@ObservableValue(name = "node_ip", expression = "host.nodeIp")
@ObservableValue(name = "current_cpu", expression = "host.availableCpu")
@ObservableValue(name = "current_hdd", expression = "host.availableHdd")
@ObservableValue(name = "current_ram", expression = "host.availableRam")
@ObservableValue(name = "total_cpu", expression = "host.totalCpu")
@ObservableValue(name = "total_hdd", expression = "host.totalHdd")
@ObservableValue(name = "total_ram", expression = "host.totalRam")
pattern hostInstances(host: HostInstance) {
HostInstance(host);
}
@ObservableValue(name = "id", expression = "app.identifier")
@ObservableValue(name = "state", expression = "app.state")
@ObservableValue(name = "db_user", expression = "app.dbUser")
@ObservableValue(name = "db_pass", expression = "app.dbPassword")
@ObservableValue(name = "allocatedTo", expression = "app.allocatedTo")
pattern applicationInstances(app: ApplicationInstance) {
ApplicationInstance(app);
}Listening to change via an Observable
There are some usecases where you don’t want to follow every change of a pattern’s match, just gather them together and process them when you’re ready. VIATRA Query provides several means of doing this, but we recommend using JFace databinding for basic purposes. To this end, the ViatraObservables utility class can transform the result set of your matcher into an observable list or set that can be tracked and even data bound easily.
For headless (or non-UI thread) execution, please use the simple DefaultRealm implementation provided in the example (and invoke it on the appropriate thread).
// (+) changes can also be tracked using JFace Databinding
// this approach provides good performance, as the observable callbacks are guaranteed to be called
// in a consistent state, and only when there is a relevant change; anything
// can be written into the callback method
// (-) * the databinding API introduces additional dependencies
// * is does not support generics, hence typesafe programming is not possible
// * a "Realm" needs to be set up for headless execution
DefaultRealm realm = new DefaultRealm(); // this is necessary for headless execution (or when you
// wish to execute outside of the UI thread. make sure to invoke it on the appropriate thread!
IObservableSet set = ViatraObservables.observeMatchesAsSet(matcher);
set.addSetChangeListener(new ISetChangeListener() {
@Override
public void handleSetChange(SetChangeEvent event) {
for (Object _o : event.diff.getAdditions()) {
if (_o instanceof EPackageMatch) {
results.append("\tNew EPackage found by changeset databinding: " + ((EPackageMatch)_o).getP().getName()+"\n");
}
}
});Using data binding to populate a table
//Initialize VIATRA query engine
ViatraQueryEngine engine = ViatraQueryEngine.on(new EMFScope(resourceSet));
//Get the matcher for the query to be observed (HostInstances pattern)
HostInstancesMatcher matcher = HostInstancesMatcher.on(engine);
//Create a generic data binding adapter for the query specification
//It is responsible for creating observable value properties based on the annotations of the pattern
GenericDatabindingAdapter adapter = new GenericDatabindingAdapter(HostInstancesMatcher.querySpecification());
//Bind the matches to the given TableViewer
ViewerSupport.bind(
tableViewer,
//Get the matching results as an observable list
ViatraObservables.observeMatchesAsList(matcher),
//Specify observed proeprties
new IValueProperty[] {
adapter.getProperty("id"),
adapter.getProperty("node_ip"),
adapter.getProperty("current_cpu"),
adapter.getProperty("current_hdd"),
adapter.getProperty("current_ram"),
adapter.getProperty("total_cpu"),
adapter.getProperty("total_hdd"),
adapter.getProperty("total_ram") });Master - detail data binding with a list
The following code fragment is responsible for binding a list to the results of a VIATRA query, and also displays match details in text boxes. (Uses Master-detail binding)
//Create new data binding context
//It will be used for binding the pattern match details
DataBindingContext dataBindingContext = new DataBindingContext();
//Initialize VIATRA query engine
ViatraQueryEngine engine = ViatraQueryEngine.on(new EMFScope(resourceSet));
//Get the matcher for the query to be observed (ApplicationInstances pattern)
ApplicationInstancesMatcher matcher = ApplicationInstancesMatcher.on(engine);
//Create a generic data binding adapter for the query specification
//It is responsible for creating observable value properties based on the annotations of the pattern
GenericDatabindingAdapter adapter = new GenericDatabindingAdapter(ApplicationInstancesMatcher.querySpecification());
//Bind the matches to the given ListViewer
ViewerSupport.bind(listViewer, ViatraObservables.observeMatchesAsSet(matcher), adapter.getProperty("id"));
//At this point, the results of the given pattern will appear in the list Viewer, the details however still need to be implemented
//Define target observable values for both textboxes
IObservableValue dbUserTarget = WidgetProperties.text().observe(dbUser);
IObservableValue dbPassTarget = WidgetProperties.text().observe(dbPass);
//Observe the changes in the list selection
IViewerObservableValue listSelection = ViewerProperties
.singleSelection().observe(listViewer);
//Use the data binding context to bind the text property of the target textbox and the given property of the matcher.
dataBindingContext.bindValue(
//Target textbox observable value
dbPassTarget,
//Get the source observable value from the adapter
adapter.getProperty("db_pass").observeDetail(listSelection),
//Define EMF update value strategy
//In this case its one directional
new EMFUpdateValueStrategy(UpdateValueStrategy.POLICY_NEVER),
new EMFUpdateValueStrategy());
dataBindingContext.bindValue(dbUserTarget, adapter.getProperty("db_user").observeDetail(listSelection),
new EMFUpdateValueStrategy(UpdateValueStrategy.POLICY_NEVER),
new EMFUpdateValueStrategy());VIATRA Viewers
The VIATRA Viewers component can bind the results of queries to various JFace Viewers: JFace ListViewer and TreeViewers are currently supported. Additionally, by installing extra features from the extra update site GraphViewers (based on GEF4 Zest) are also supported. In the following example, and during the lab excersize as well, usage of GraphViewers will be presented. These GraphViewers are capable of displaying query results as graphs.
Usage
In order to use the VIATRA Viewers addon the following steps need to be undertaken:
-
Annotate VIATRA query patterns with the @Item, @ContainsItem and @Edge annotations
-
@Item will be represented as a graph node
-
@ContainsItem will be represented as a node and an edge (edge is between the parent and child nodes)
-
@Edge will be displayed as an edge (targeted)
-
-
Initialize the Viewers based UI component
Pattern Annotations
//Host Type objects will be nodes of the displayed graph
@Item(item = host, label = "$host.identifier$")
//Format options can be set using the @Format annotation
@Format(color = "#0033CC", textColor = "#FFFFFF")
pattern hostTypes(host) {
HostType(host);
}
//Host types contain host instances
//Displayed as nodes which have common edges with their parents
@ContainsItem(container = type, item = instance)
pattern connectTypesAndInstancesHost(type, instance) {
HostType.instances(type,instance);
}
//Host instances can communicate with each other
//Displayed as an edge between the two nodes
@Edge(source = i1, target = i2, label = "comm")
pattern communications(i1, i2) {
HostInstance.communicateWith(i1,i2);
}Initializing a viewer programmatically
-
Add a dependency to
org.eclipse.viatra.addon.viewers.runtime(andorg.eclipse.viatra.addon.viewers.runtime.zestif necessary) to your plug-in. -
Create a
ViewerStateinstance from a group of query specification. Useful (static) helper methods are available in theViatraViewerDataModelclass, that require a collection of query specifications; a data filter and the required features.-
Collection of query specifications: only the query specifications with the corresponding Viewers annotations will be used; other specifications will be ignored.
-
ViewerDataFilter: it is used to filter the result of the queries by its parameters. For each pattern a separate filter can be initialized, that binds some of its parameters.
-
Required features: The ViewerStateFeature enum can be used to list the features required by the visualization. List viewers need no specific features; tree viewers require containment relations; Zest viewer requires edge relations (and possibly containment relations). Features not required will not create
-
-
Use the corresponding bind methods from
ViatraViewersorViatraGraphViewersclasses on a manually createdViewertogether with theViewerStateand your instance model.-
The
ViewerStateinstance can be re-used between different viewers. -
If the filters added to the
ViewerStateare changed, all the viewers will become obsolete, and have to be recreated.
-
//Create the graph viewer component and add it to the containing SWT control
GraphViewer viewer = new GraphViewer(parent, SWT.None);
//Create a new Viewer state based on the created VIATRA query engine and a set of annotated VIATRA query specifications
ViewerState state = ViatraViewerDataModel.newViewerState(getEngine(), getSpecifications(), ViewerDataFilter.UNFILTERED,
ImmutableSet.of(ViewerStateFeature.EDGE, ViewerStateFeature.CONTAINMENT));
//This method of binding supports isolated nodes
ViatraGraphViewers.bindWithIsolatedNodes(viewer, state, true);
//Define layout algorithm
viewer.setLayoutAlgorithm(new SpaceTreeLayoutAlgorithm());
//Apply layout
viewer.applyLayout();Examples
UML visualization
To illustrate the approach, a simple example was prepared in the examples repository of the VIATRA project based on UML class diagrams. The examples are relying on the notion of example classes: UML classes that do not have operations or properties (neither in their parent classes).
To present most features of the framework, four specific patterns are used (for the entire implementations visit the git repository):
-
pattern emptyClass (cl : Class)- for listing all empty classes in the model -
pattern nonEmptyClass(cl : Class)- for listing all classes in the model, that are not empty -
pattern superClass(sub : Class, sup : Class)- for listing all direct superclass relations between classes -
pattern transitiveSuperClass(sub : Class, sup : Class)- for listing all indirect superclass relations between classes (but not the direct ones)
The visualizer illustrations below correspond to the test model in the repository.
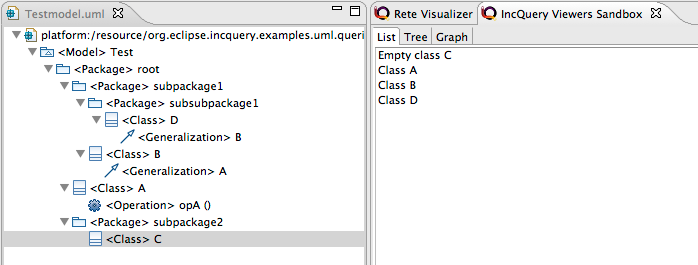
JFace List Viewer example
List Viewers can be used to display a collection of elements as a list. To define the list, only the Item annotation is used. Its item parameter selects a pattern parameter, representing the data to display, while its label parameter is used to define a label string (with the same syntax as the label features of Data Binding or the labels of Validation Framework.
@Item(item = cl, label="Empty class $cl$")
pattern emptyClass(cl : Class) {
...
}
@Item(item = cl, label = "Class $cl$")
pattern nonEmptyClass(cl : Class) {
...
}
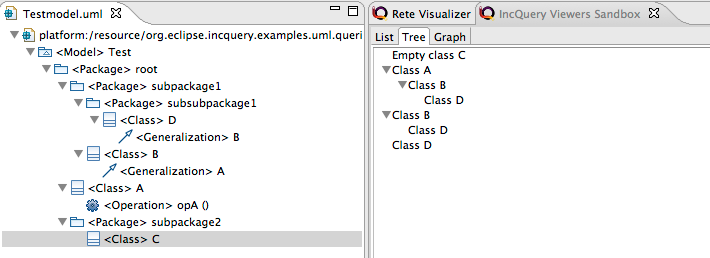
Binding contents to a JFace Tree Viewer
To support binding elements to a JFace Tree Viewer, in addition to the list of items, a set of containment relations needs also be specified using the <code>ContainsItem</code> annotation, that describes the container and contained items as pattern parameters. A containment reference is only displayed if both ends of the match result are present as Items in the viewer - otherwise it is simply ignored.
A unique property of the Tree Viewer support is that a single Item of the Viewers framework may appear multiple times in the tree. This happens if an element has multiple parents.
@ContainsItem(container = sup, item = sub)
pattern superClass(sub : Class, sup : Class) {
...
}
@Item(item = cl, label="Empty class $cl$")
pattern emptyClass(cl : Class) {
...
}
@Item(item = cl, label = "Class $cl$")
pattern nonEmptyClass(cl : Class) {
...
}
Additional notes
-
In addition to basic binding support where all items appear both as root and child items as needed, it is possible to limit Items to appear only as root or only as child positions using the hierarchy parameter.
-
If creating a TreeViewer binding programmatically, and an item appear in multiple places, make sure you set up the
useHashLookupproperty of your TreeViewer, otherwise the update of the TreeViewer would fail.
Zest Graph Viewer example
The definition of graph viewers requires a set of Items and a set of Edges. Edges are connecting two different Items; edges where the end points are not Items are not displayed. As opposed to the Tree Viewer support, a single item only appears once.
Additionally, based upon the formatting capabilities of Zest some basic display options are available in the form of Format annotation. The various parameters can be used to depict colors, line width, etc. If a selected format is not applicable for the current element, it is simply ignored.
@Edge(source = sup, target = sub, label = "direct")
@Format(color = "#7f004b", lineWidth = 2)
pattern superClass(sub : Class, sup : Class) {
...
}
@Edge(source = sup, target = sub)
pattern transitiveSuperClass(sub : Class, sup : Class) {
...
}
@Item(item = cl, label="Empty class $cl$")
@Format(color="#3770d7", textColor = "#ffffff")
pattern emptyClass(cl : Class) {
...
}
@Item(item = cl, label = "Class $cl$")
pattern nonEmptyClass(cl : Class) {
...
}
Ecore visualization
We have developed another demonstrating example in the context of the headless example. As the queries of the headless example match against .ecore models (that is, EMF metamodels), the visualization example below can be used to visualize metamodels and containment relationships in a simple way. This example is focused mainly on the 2D graph visualization supported by the GEF5 Zest framework.
Specification
The example defines two graph node types and three graph edge types (code):
-
Nodes are EPackage and EClass instances
-
Edges are classes contained in a package, subpackage relationships, and a special transitive containment relationship between packages and classes classes in a package hierarchy that enumerates all classes that are contained by a root package or some subpackage (transitively) below this root.
@Item(item = p, label = "P: $p.name$")
@Format(color = "#791662", textColor = "#ffffff")
pattern ePackage(p : EPackage) { EPackage(p); }
@Item(item = ec, label = "EC: $ec.name$")
@Format(color = "#e8da2c")
pattern eClass(ec : EClass) { EClass(ec); }
@Edge(source = p, target = ec, label = "classIn")
pattern classesInPackage(p : EPackage, ec: EClass) { EPackage.eClassifiers(p,ec); }
@Edge(source = p, target = sp, label = "sub")
pattern subPackage(p: EPackage, sp: EPackage){ EPackage.eSubpackages(p,sp); }
@Edge(source = rootP, target = containedClass, label = "classIn+")
@Format(color = "#0033ff")
pattern classesInPackageHierarchy(rootP: EPackage, containedClass: EClass)
{
find classesInPackage(rootP,containedClass);
} or {
find subPackage+(rootP,somePackage);
find classesInPackage(somePackage,containedClass);
}The visualization of a simple test model (file)
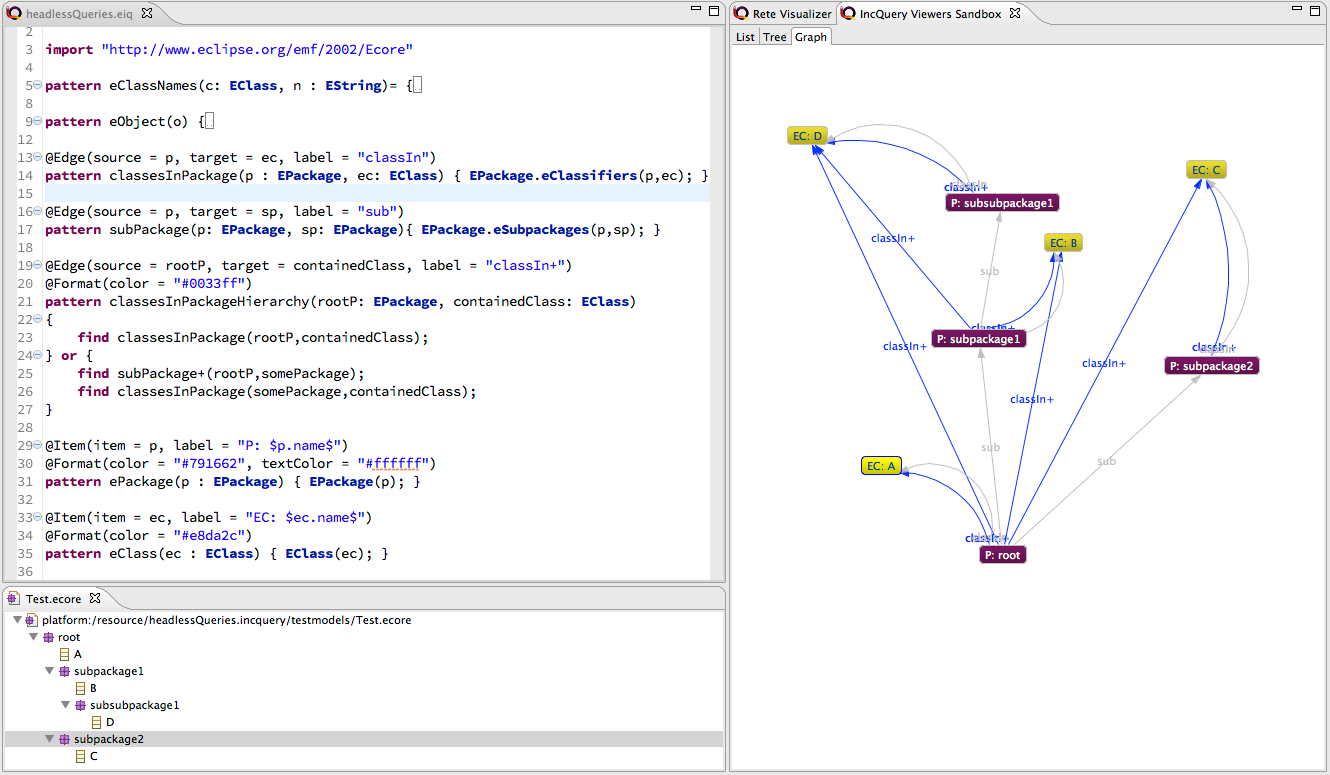
Observe the following details:
-
EPackages and EClasses are shown in purple and yellow, respectively
-
direct relationships (subpackage and contained packages) are shown in grey
-
inferred transitive containment relationships are shown in blue
UML support for VIATRA
In order to work seamlessly with UML editors, VIATRA provides two relevant integration features: (1) The GMF integration feature is required for the Query Result view to work with GMF-based editors such as Papyrus; and (2) a set of surrogate queries for the UML metamodel. Both of these features are available from the VIATRA update sites.
Surrogate queries for UML derived features
The EMF metamodel for UML 2 contains several derived features which are not supported in VIATRA patterns by default. This optional integration component provides support for them via defining appropriate surrogate queries.
-
Add the ''org.eclipse.viatra.integration.uml'' plugin to your dependencies.

-
Now you can use most of the derived features like every other feature.
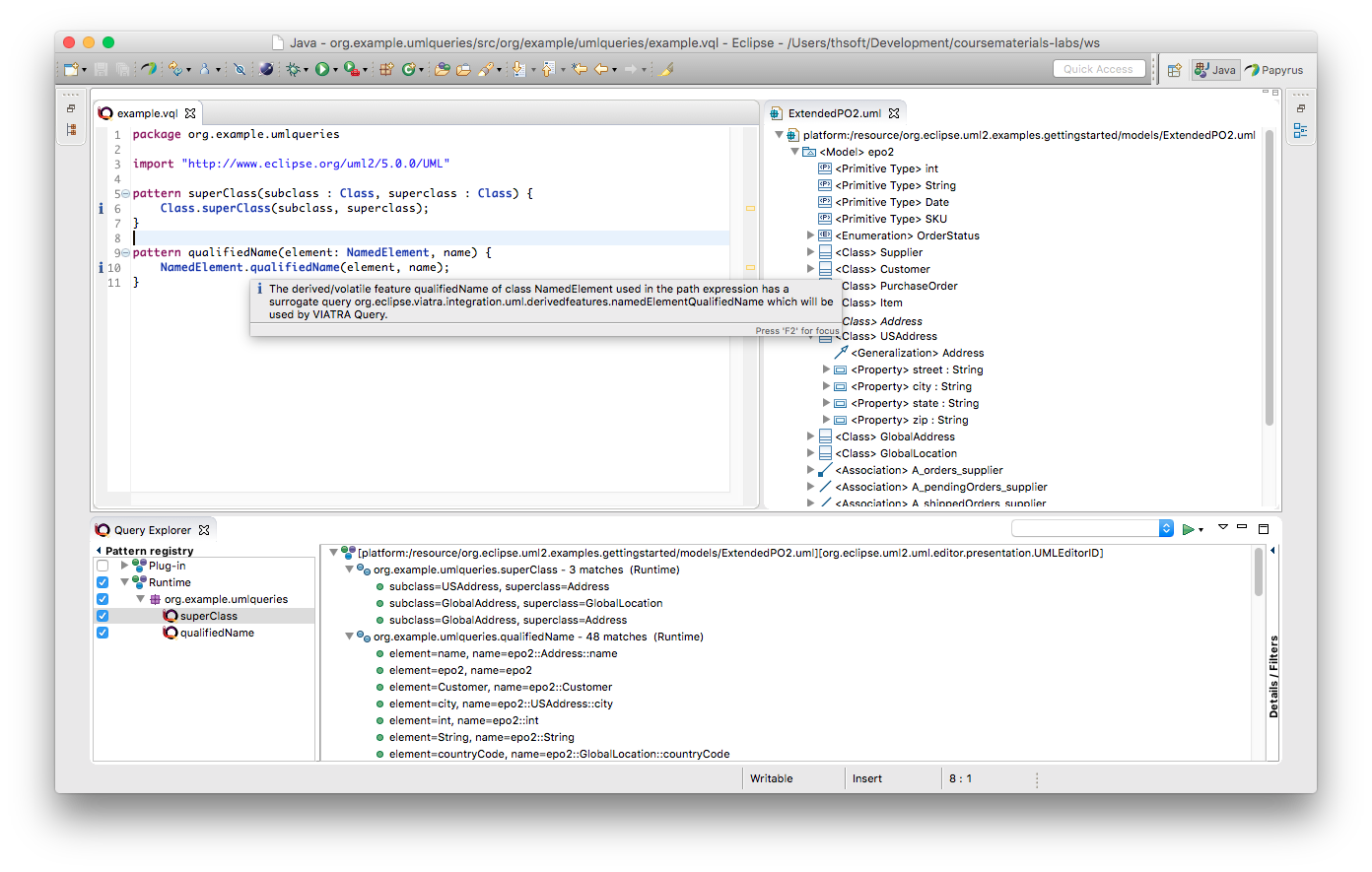
As of version 1.7.0, VIATRA does not provide support for all derived features defined in the UML model. In the following, the current status is detailed.
| Derived feature | Status | Remark |
|---|---|---|
Action.context |
Done |
Since 1.1.0 |
Action.input |
Done |
Since 1.0.0 |
Action.output |
Done |
Since 1.0.0 |
Activity.group |
Done |
Since 1.0.0 |
Activity.node |
Done |
Since 1.0.0 |
ActivityEdge.inGroup |
Done |
Since 1.0.0 |
ActivityGroup.containedEdge |
Done |
Since 1.0.0 |
ActivityGroup.containedNode |
Done |
Since 1.0.0 |
ActivityGroup.inActivity |
Done |
Since 1.1.0 |
ActivityGroup.subgroup |
Done |
Since 1.0.0 |
ActivityGroup.superGroup |
Done |
Since 1.0.0 |
ActivityNode.activity |
Done |
Since 1.1.0 |
ActivityNode.inGroup |
Done |
Since 1.0.0 |
Association.endType |
Done |
Since 1.0.0 |
Behavior.context |
Done |
Since 1.1.0 |
Class.extension |
TODO |
Buggy in 1.0.0, disabled in 1.1.0 (implementation checks Metaclass stereotype application, so it will be incorrect if used on classes that are not metaclasses) |
Class.superClass |
Done |
Since 1.0.0 |
Classifier.attribute |
Done |
Since 1.0.0 |
Classifier.feature |
Done |
Since 1.0.0 |
Classifier.general |
Done |
Since 1.0.0 |
Classifier.inheritedMember |
TODO |
|
Component.provided |
TODO |
|
Component.required |
TODO |
|
ConnectableElement.end |
Done |
Since 1.0.0 |
Connector.kind |
Done |
Since 1.0.0 |
ConnectorEnd.definingEnd |
TODO |
|
DeploymentTarget.deployedElement |
Done |
Since 1.0.0 |
DirectedRelationship.source |
Done |
Since 1.0.0 |
DirectedRelationship.target |
Done |
Since 1.0.0 |
Element.ownedElement |
Done |
Since 1.0.0 |
Element.owner |
Done |
Since 1.0.0 |
EncapsulatedClassifier.ownedPort |
Done |
Since 1.0.0 |
Extension.isRequired |
TODO |
|
Extension.metaclass |
Done |
Since 1.0.0 |
Feature.featuringClassifier |
Incorrect |
Since 1.0.0, known problems (opposite of Classifier.feature according to specification, but implementation gives different result in some corner cases involving signals) |
Message.messageKind |
Done |
Since 1.0.0 |
MultiplicityElement.lower |
TODO |
|
MultiplicityElement.upper |
TODO |
|
NamedElement.clientDependency |
Done |
Since 1.0.0 |
NamedElement.namespace |
Done |
Since 1.0.0 |
NamedElement.qualifiedName |
Done |
Incorrect in 1.0.0, fixed in 1.1.0 |
Namespace.importedMember |
Incorrect |
Since 1.0.0, known problems (imported members of Profiles are not fully correct) |
Namespace.member |
Incorrect |
Since 1.0.0, known problems (inherited class members are not included) |
Namespace.ownedMember |
Done |
Since 1.0.0 |
OpaqueExpression.result |
Done |
Since 1.0.0 |
Operation.isOrdered |
TODO |
|
Operation.isUnique |
TODO |
|
Operation.lower |
TODO |
|
Operation.type |
TODO |
|
Operation.upper |
TODO |
|
Package.nestedPackage |
Done |
Since 1.0.0 |
Package.nestingPackage |
Done |
Since 1.1.0 |
Package.ownedStereotype |
Done |
Since 1.0.0 |
Package.ownedType |
Done |
Since 1.0.0 |
Parameter.default |
TODO |
|
Port.provided |
TODO |
|
Port.required |
TODO |
|
Property.default |
TODO |
|
Property.isComposite |
Done |
|
Property.opposite |
TODO |
|
ProtocolTransition.referred |
Done |
Since 1.0.0 |
RedefinableElement.redefinedElement |
Done |
Since 1.0.0 |
RedefinableElement.redefinitionContext |
Done |
Since 1.0.0 |
RedefinableTemplateSignature.inheritedParameter |
Done |
Since 1.0.0 |
Relationship.relatedElement |
Done |
Since 1.0.0 |
State.isComposite |
Done |
Since 1.0.0 |
State.isOrthogonal |
Done |
Since 1.0.0 |
State.isSimple |
TODO |
|
State.isSubmachineState |
TODO |
|
Stereotype.profile |
TODO |
|
StructuredClassifier.part |
Done |
Since 1.0.0 |
StructuredClassifier.role |
Done |
Since 1.0.0 |
Type.package |
Done |
Since 1.0.0 |
Vertex.incoming |
Done |
Since 1.0.0 |
Vertex.outgoing |
Done |
Since 1.0.0 |
| When using UML in a headless environment, make sure to call ViatraQueryUMLStandaloneSetup.doSetup() to ensure everything is registered. |
Static profile support
If you have an EMF-UML profile, you can query over applications of its stereotypes and their tagged values as if they were ordinary EClasses and EAttributes. As of 1.1.0, VIATRA only supports static profiles, so you have to define one as described in this blog post.
On the example below continuing the blog post, in the started runtime Eclipse, we created a pattern that matches <tt>ExampleStereotype</tt> applications, and as we can see in the Query Explorer, it has matches on a simple UML instance model:
Note for Papyrus users: it is recommended to also register your profile with Papyrus. To accomplish this, add an extension for the org.eclipse.papyrus.uml.extensionpoints.UMLProfile extension point, pointing to the UML model file containing your profile. For more information, refer to this thread.
The code for this example can be found in this repository.