Loading Huge Volumes of Data With Jakarta EE Batch
Processing huge volumes of data creates challenges for every enterprise system. The Jakarta Batch project, which continues the standardization work of Java Specification Request 352 (JSR-352), provides a good approach to resolving these challenges.
Before I describe how to implement a typical batch processing use case, here’s a closer look at the need for batch processing and the requirements associated with it from the JSR-352 specification.
“Batch processing is a pervasive workload pattern, expressed by a distinct application organization and execution model. It is found across virtually every industry, applied to such tasks as statement generation, bank postings, risk evaluation, credit score calculation, inventory management, portfolio optimization, and on and on. Nearly any bulk processing task from any business sector is a candidate for batch processing.
Batch processing is typified by bulk-oriented, non-interactive, background execution. Frequently long-running, it may be data or computationally intensive, executed sequentially or in parallel, and may be initiated through various invocation models, including ad hoc, scheduled, and on-demand.
Batch applications have common requirements, including logging, checkpointing, and parallelization. Batch workloads have common requirements, especially operational control, which allow for initiation of, and interaction with, batch instances; such interactions include stop and restart.”
A Typical Use Case for Batch Processing
One of the typical use cases for batch workloads is the need to import data from different sources and formats into an internal database.
To demonstrate how well structured an application that performs this import can be, I’ve created a sample application that imports data from json and xml files into a database.
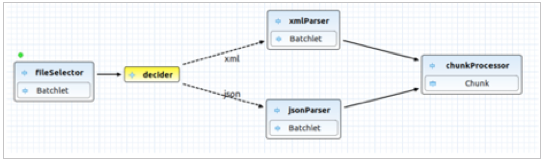
As shown in Figure 1, the application can be easily designed using the Red Hat CodeReady Studio software that’s available in the Eclipse Marketplace.
Figure 1: The Sample Application Design
In this case, the Jakarta Batch descriptor for XML files looks like the code shown in Figure 2,
META-INF/batch-jobs/hugeImport.xml
Figure 2: XML Batch Descriptor Code

Now, we need to implement each brick above and try to keep each batchlet as independent as possible. As you can see in Figure 2, our sample job consists of:
- fileSelector: A batchlet that selects files based on the configuration file extension.
- decider: The decision-maker that is responsible for choosing the right parser for the file type.
- xmlParserBatchlet and jsonParserBatchlet: Parser batchlets that are responsible for file parsing to a list of items.
- chunkProcessor: Item-processing chunk reader, (optionally also a chunk processor and writer) with partitioning to boost performance.
First, let's design a solution to share states between steps. Unfortunately, the Jakarta Batch specification does not provide job-scoped Contexts and Dependency Injection (CDI) beans yet. But, we can use JobContext.set\getTransientUserData()to deal with the current batch context.
In our case, we want to share File and Queue with items for processing, as shown in Figure 3.
Figure 3: Sharing File and Queue With Items for Processing
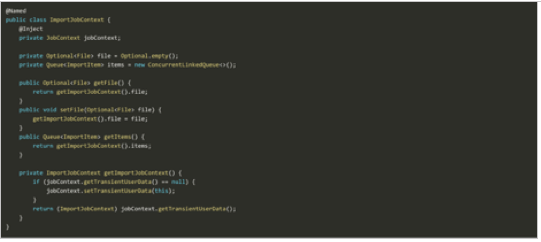
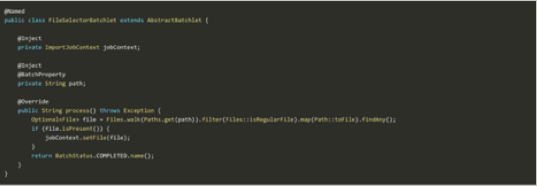
Now we can inject ImportJobContext to share type-safe state information between batchlets. The first step is to search for the file for processing by providing the file name in the properties path, as shown in Figure 4.
Figure 4: Searching for the File to Be Processed
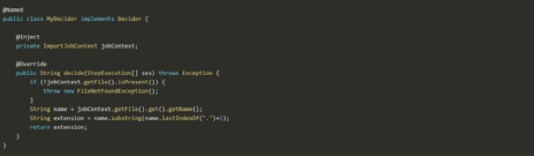
Now, it’s time to make the decision about which parser to use based on the file extension, as shown in Figure 5. When the decider returns the file extension as a string, the batch runtime should give control to the corresponding parser batchlet. For reference, see the <decision id="decider" ref="myDecider"> section in the XML batch descriptor code shown in Figure 2.
Figure 5: Deciding Which Parser to Use
The appropriate ParserBatchlet should now parse the file using JSON-B or JAXB, depending on the file type, and fill the Queue with ImportItem objects, as shown in Figure 6.
I would like to use ConcurrentLinkedQueue to share items between partitions, but if you need a different behavior here, you can provide javax.batch.api.partition.PartitionMapper with your own implementation.
Figure 6: Filling the Queue With ImportItem Objects
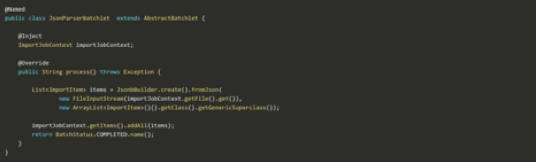
At this point, the ItemReader is simply pooling items from the Queue, as shown in Figure 7.
Figure 7: ItemReader Pooling Items From the Queue

And persist time, as shown in Figure 8.
Figure 8: Setting up Persistence
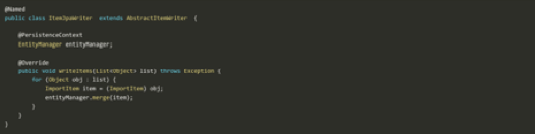
From here, it’s easy to extend the application with new parsers, processors, and writers without changing the existing code. You can simply describe the new flow, and update existing flows, using the Jakarta Batch descriptor.
The Jakarta Batch specification provides much more helpful functionality than I have covered in this article, including checkpoints, exception handling, listeners, flow control, and failed job restarting, but hopefully this is enough to help you see how simple, powerful, and well-structured batch processing can be.
The sample application source code in this article is available here in GitHub.
About the Author
